This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. What are machinelearning algorithms? Regression: Focuses on predicting continuous values, such as forecasting sales or estimating property prices.
Training-serving skew is a significant concern in the machinelearning domain, affecting the reliability of models in practical applications. Understanding how discrepancies between training data and operational data can impact model performance is essential for developing robust systems. What is training-serving skew?
Machinelearning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. Solution overview This post focuses on the benefits of using Ray and SageMaker together.
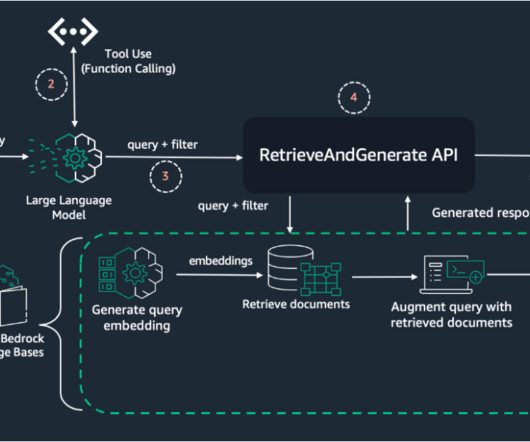
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
In this article we will speak about Serverless Machinelearning in AWS, so sit back, relax, and enjoy! Introduction to Serverless MachineLearning in AWS Serverless computing reshapes machinelearning (ML) workflow deployment through its combination of scalability and low operational cost, and reduced total maintenance expenses.
Predictive modeling plays a crucial role in transforming vast amounts of data into actionable insights, paving the way for improved decision-making across industries. By leveraging statistical techniques and machinelearning, organizations can forecast future trends based on historical data.
Introduction Machinelearning models learn patterns from data and leverage the learning, captured in the model weights, to make predictions on new, unseen data. Data, is therefore, essential to the quality and performance of machinelearning models.
In this post, we explore the best practices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. with a default value of 1.0.
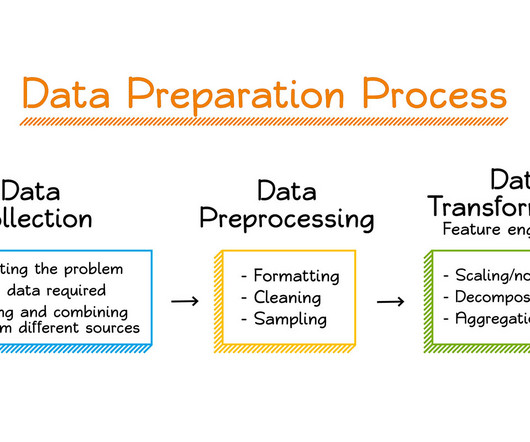
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machinelearning (ML) from weeks to minutes.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machinelearning (ML) lifecycle. Datapreparation In this phase, prepare the training and test data for the LLM. amazonaws.com/djl-inference:0.29.0-tensorrtllm0.11.0-cu124",
Data mining is a fascinating field that blends statistical techniques, machinelearning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
Data science is an interdisciplinary field that utilizes advanced analytics techniques to extract meaningful insights from vast amounts of data. This helps facilitate data-driven decision-making for businesses, enabling them to operate more efficiently and identify new opportunities.
Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. What is machinelearning (ML)?
Understanding Supervised vs Unsupervised Learning: A Comparative Overview Introduction Hello dear readers, hope you’re doing just fine! (Or Or even better than that) Machinelearning has transformed the way businesses operate by automating processes, analyzing data patterns, and improving decision-making.
Machinelearning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
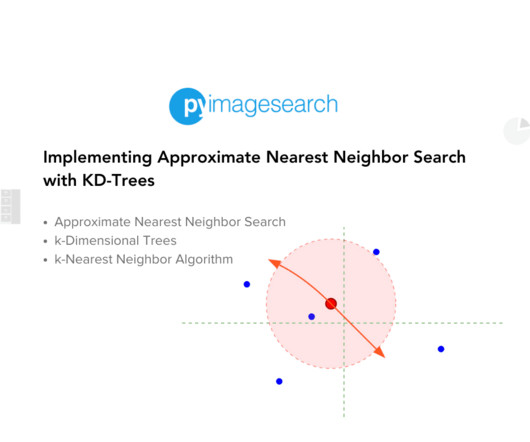
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machinelearning. Imagine a database with billions of samples ( ) (e.g.,
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for datapreparation before analysis. Data Analysis and Modeling This stage is focused on discovering patterns, trends, and insights through statistical methods, machine-learning models, and algorithms.
In recent years, the field of machinelearning has gained tremendous momentum, offering powerful solutions and valuable insights from vast amounts of data. However, the process of building machinelearning models traditionally involved a time-consuming and resource-intensive approach, requiring extensive expertise.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Pietro Jeng on Unsplash MLOps is a set of methods and techniques to deploy and maintain machinelearning (ML) models in production reliably and efficiently. Thus, MLOps is the intersection of MachineLearning, DevOps, and Data Engineering (Figure 1). Projects: a standard format for packaging reusable ML code.
Teaching Through Data The purpose of annotating data is to tell machinelearning models exactly what we want them to know. Teaching a machine to learn through annotation can be likened to teaching a toddler shapes and colors using flashcards, where the annotations are the flashcards and annotators are the teacher.
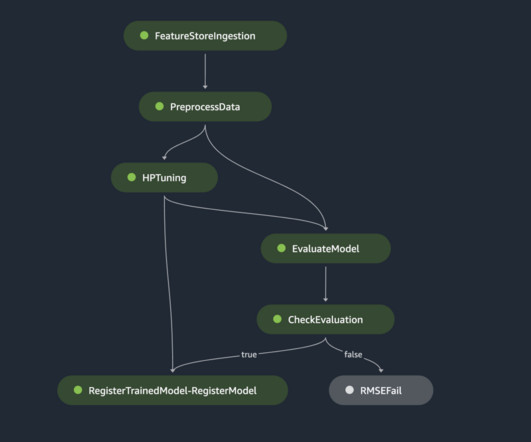
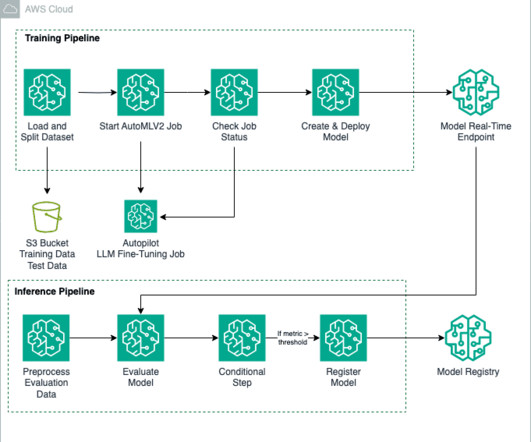
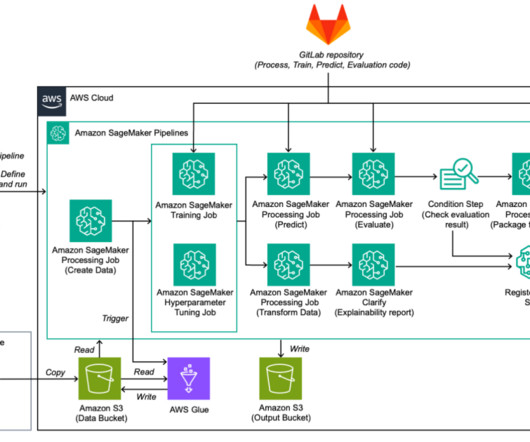
We use Amazon SageMaker Pipelines , which helps automate the different steps, including datapreparation, fine-tuning, and creating the model. We demonstrated an end-to-end solution that uses SageMaker Pipelines to orchestrate the steps of datapreparation, model training, evaluation, and deployment.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machinelearning workflow from datapreparation to model deployment. Datapreparation The foundation of any machinelearning project is datapreparation.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
The machinelearning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses. Huy Dang Data Scientist at Scalable GmbH.
How to Use MachineLearning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machinelearning were introduced.
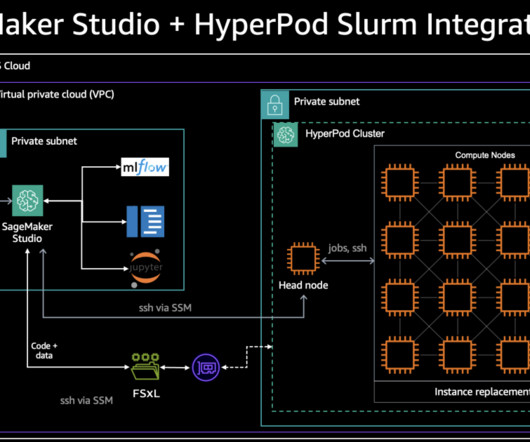
Sharing in-house resources with other internal teams, the Ranking team machinelearning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. Daniel Zagyva is a Data Scientist at AWS Professional Services.
Gungor Basa Technology of Me There is often confusion between the terms artificial intelligence and machinelearning. An agent is learning if it improves its performance based on previous experience. When the agent is a computer, the learning process is called machinelearning (ML) [6, p.
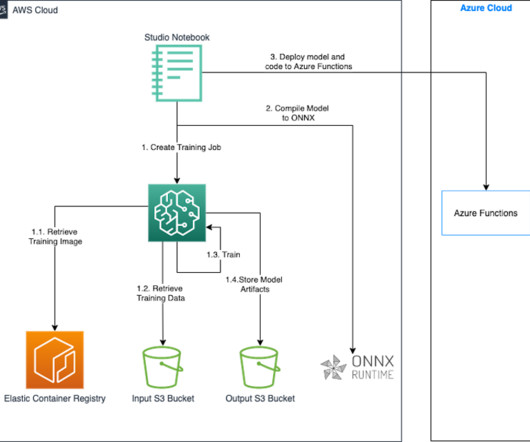
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. What is machinelearning (ML)?
It provides a unified, web-based interface where data scientists and developers can perform ML tasks, including datapreparation, model building, training, tuning, evaluation, deployment, and monitoring. This way, we provide a faster execution of the training workload by avoiding asset copy from other data repositories.
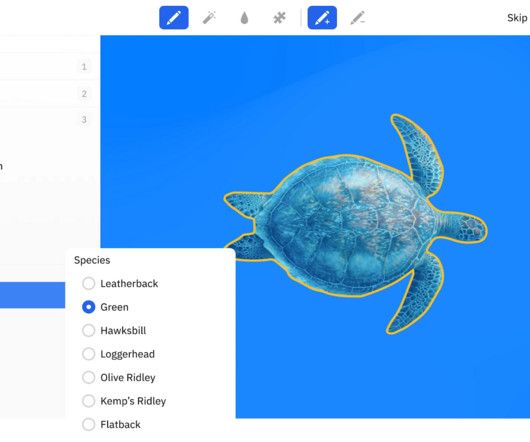
Image labeling and annotation are the foundational steps in accurately labeling the image data and developing machinelearning (ML) models for the computer vision task. In this article, you will learn about the importance of image annotation and what you should know for annotating image files for machinelearning at scale.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machinelearning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
It can be difficult to find insights from this data, particularly if efforts are needed to classify, tag, or label it. Amazon Comprehend is a natural-language processing (NLP) service that uses machinelearning to uncover valuable insights and connections in text. This can increase user engagement.
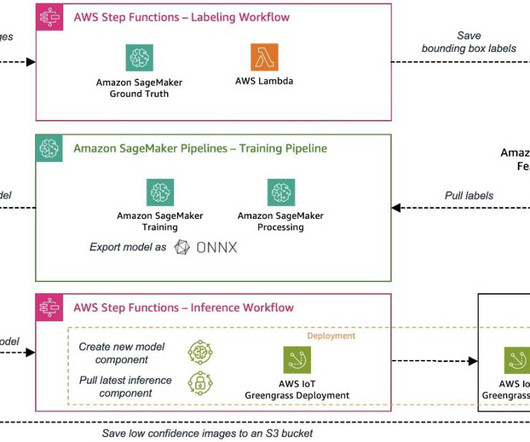
Solution overview In Part 1 of this series, we laid out an architecture for our end-to-end MLOps pipeline that automates the entire machinelearning (ML) process, from data labeling to model training and deployment at the edge. For other topics and use cases, refer to our MachineLearning and IoT blogs.
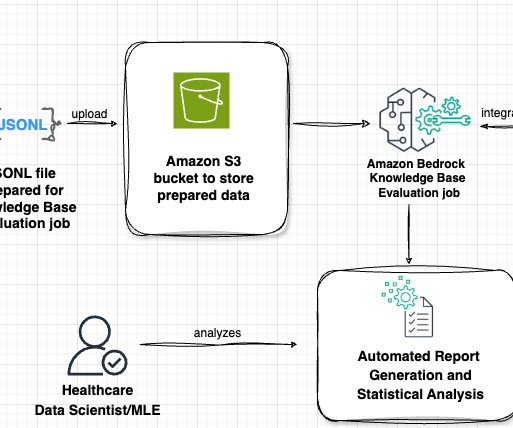
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions. No definite pneumonia.
Or an organization may be operating in a Region where a primary cloud provider is not available, and in order to meet the data sovereignty or data residency requirements, they can use a secondary cloud provider. Key concepts Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machinelearning.
Custom geospatial machinelearning : Fine-tune a specialized regression, classification, or segmentation model for geospatial machinelearning (ML) tasks. While this requires a certain amount of labeled data, overall data requirements are typically much lower compared to training a dedicated model from the ground up.
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. With predictive maintenance, L&W can get advanced warning of machine breakdowns and proactively dispatch a service team to inspect the issue.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. With this Spark connector, you can easily ingest data to the feature group’s online and offline store from a Spark DataFrame. When not helping customers, she enjoys outdoor activities.
Simple Random Sampling Definition and Overview Simple random sampling is a technique in which each member of the population has an equal chance of being selected to form the sample. Analyze the obtained sample data. Analyze the obtained sample data. Collect data from individuals within the selected clusters.
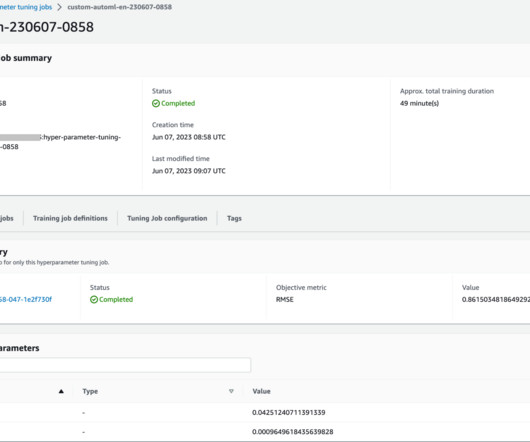
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machinelearning (ML) project lifecycle. It plays a crucial role in every model’s development process and allows data scientists to focus on the most promising ML techniques. py"): estimator_name = script.split(".")[0].replace("_",
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content