This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
Definition and functionality of LLM app platforms These platforms encompass various capabilities specifically tailored for LLM development. Data cleaning and annotation Data cleaning: Involves standardizing text and eliminating any unnecessary formatting. KLU.ai: Offers no-code solutions for smooth data source integration.
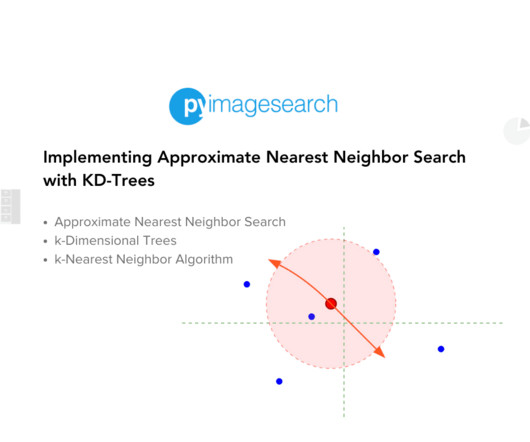
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. Imagine a database with billions of samples ( ) (e.g., So, how can we perform efficient searches in such big databases?
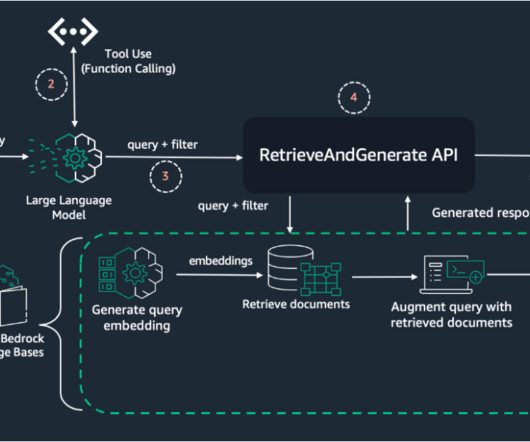
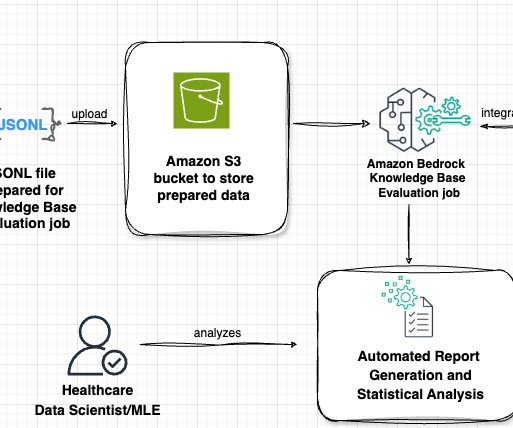
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
In this post, we highlight the advanced data augmentation techniques and performance improvements in Amazon Bedrock Model Distillation with Metas Llama model family. Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities.
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
This post explores deploying a text-to-SQL pipeline using generative AI models and Amazon Bedrock to ask natural language questions to a genomics database. Text-to-SQL for genomics data Text-to-SQL is a task in natural language processing (NLP) to automatically convert natural language text into SQL queries.
Few static analysis tools store the relational representation of the code base and evaluate a query (written in a specific query language) on the code base, similar to how a database query is evaluated by a database engine. the definitions of the conflicting attributes in the example). So, what did we find out?!
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. RPA tools can be programmed to interact with various systems, such as web applications, databases, and desktop applications. RPA and ML are two different technologies that serve different purposes.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly. The following figure shows schema definition and model which reference it.
If you are targeting roles involving data visualization , Data Analysis , or Business Intelligence , you can expect your interview to include questions specifically testing your data viz prowess. Preparing for these questions is crucial. The approach depends on the context and the amount of missing data.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. compute.internal.
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions. No definite pneumonia.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you want to do the process in a low-code/no-code way, you can follow option C.
A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle. They all agree that a Datamart is a subject-oriented subset of a data warehouse focusing on a particular business unit, department, subject area, or business functionality. A replacement for datasets.
This entails breaking down the large raw satellite imagery into equally-sized 256256 pixel chips (the size that the mode expects) and normalizing pixel values, among other datapreparation steps required by the GeoFM that you choose. For scalability and search performance, we index the embedding vectors in a vector database.
Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
Snowflake stored procedures are programmable routines that allow users to encapsulate and execute complex logic directly in a Snowflake database. Integrating Snowflake stored procedures with dbt Hooks automates complex data workflows and improves pipeline orchestration. What are Snowflake Stored Procedures & dbt Hooks?
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. RPA tools can be programmed to interact with various systems, such as web applications, databases, and desktop applications. RPA and ML are two different technologies that serve different purposes.
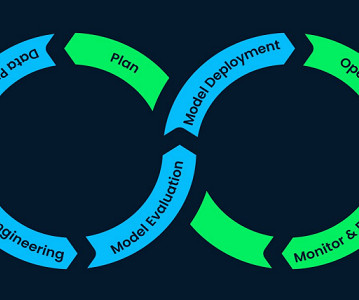
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
Let’s explore some common examples to understand how it works in practice: Example 1: Filtering and Sorting One fundamental data manipulation task is filtering and sorting. This involves selecting specific rows or columns based on certain criteria and arranging the data in order.
Generative AI definitions and differences to MLOps In classic ML, the preceding combination of people, processes, and technology can help you productize your ML use cases. Additions are required in historical datapreparation, model evaluation, and monitoring. Only prompt engineering is necessary for better results.
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes.
A second technique for customizing LLMs and other FMs for your business is retrieval augmented generation (RAG), which allows you to customize a model’s responses by augmenting your prompts with data from multiple sources, including document repositories, databases, and APIs. or “Should I use a relational or non-relational database?”).
It systematically collects data from diverse sources such as databases, online repositories, sensors, and other digital platforms, ensuring a comprehensive dataset is available for subsequent analysis and insights extraction. Sources of DataData can come from multiple sources. Removing outliers is also necessary.
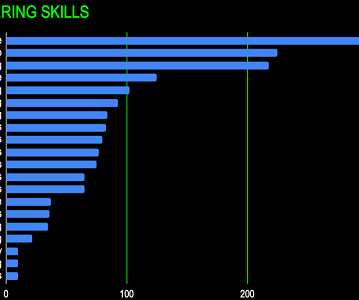
We don’t claim this is a definitive analysis but rather a rough guide due to several factors: Job descriptions show lagging indicators of in-demand prompt engineering skills, especially when viewed over the course of 9 months. The definition of a particular job role is constantly in flux and varies from employer to employer.
By maintaining clean and reliable data, businesses can avoid costly mistakes, enhance operational efficiency, and gain a competitive edge in their respective industries. Best Data Hygiene Tools & Software Trifacta Wrangler Pros: User-friendly interface with drag-and-drop functionality. Provides real-time data monitoring and alerts.
There are definitely compelling economic reasons for us to enter into this realm. Datapreparation, train and tune, deploy and monitor. We have data pipelines and datapreparation. A database of prompt examples may need to be required for each of these phases. It can cover the gamut.
There are definitely compelling economic reasons for us to enter into this realm. Datapreparation, train and tune, deploy and monitor. We have data pipelines and datapreparation. A database of prompt examples may need to be required for each of these phases. It can cover the gamut.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. The type of data you collect is essential, and it falls into two main categories: structured and unstructured data. Once you have your data, preprocessing is the next step.
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. When you look at the end-to-end journey of an eCommerce platform, you will find there are plenty of components where data is generated.
Decision Trees ML-based decision trees are used to classify items (products) in the database. Preparation Stage Project goal definition — start with the comprehensive outline and understanding of minor and major milestones and goals. Data visualization charts and plot graphs can be used for this.
Historical data is normally (but not always) independent inter-day, meaning that days can be parsed independently. In GPU Accelerated DataPreparation for Limit Order Book Modeling , the authors describe a GPU pipeline handling data collection, LOB pre-processing, data normalization, and batching into training samples.
However, you can also test this by using the Custom project profile by selecting specific blueprints such as LakehouseCatalog and LakeHouseDatabase for scenarios where the business unit doesnt have their own data warehouse. Solution walkthrough (Scenario 1) The first step focuses on preparing the data for each data source for unified access.
We are also hiring for other engineering and growth roles - https://supabase.com/careers reply manish_gill 9 hours ago | prev | next [–] ClickHouse | Senior Software Engineer - Cloud Infrastructure / Kubernetes | Remote (US / EU preferred) ClickHouse is a popular, Open-Source OLAP Database.
Organizational resiliency draws on and extends the definition of resiliency in the AWS Well-Architected Framework to include and prepare for the ability of an organization to recover from disruptions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content