This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Charles holds an MS in Supply Chain Management and a PhD in Data Science. Huong Nguyen is a Sr. Product Manager at AWS.
Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular. A new data flow is created on the Data Wrangler console. Choose Get data insights to identify potential data quality issues and get recommendations. For Data size , select Sampled dataset (20k).
As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. But here is a problem: While pySpark syntax is straightforward and very easy to follow, it can be readily confused with other common libraries for datawrangling. Default is True.
This includes duplicate removal, missing value treatment, variable transformation, and normalization of data. Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for datapreparation before analysis.
Stefanie Molin, Data Scientist, Software Engineer, Author of Hands-On Data Analysis with Pandas at Bloomberg Stefanie Molin is a software engineer and data scientist at Bloomberg, where she tackles complex information security challenges through datawrangling, visualization, and tool development.
To prepare the data for models, a data scientist often needs to transform, clean, and enrich the dataset. Fortunately, SageMaker’s data-wrangling capabilities allow data scientists to quickly and efficiently transform and review the transformed data. We will explore these options in the next steps.
Data Analysts need deeper knowledge on SQL to understand relational databases like Oracle, Microsoft SQL and MySQL. Moreover, SQL is an important tool for conducting DataPreparation and DataWrangling. SQL Data Analyst Salary SQL Data Analyst’s salary has a pay scale that starts from $61,128 per annum.
We can’t send private data such as medical records to an API, and therefore we need small open-source models to improve the feasibility of our proposal. A next huge challenge is datapreparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases.
We can’t send private data such as medical records to an API, and therefore we need small open-source models to improve the feasibility of our proposal. A next huge challenge is datapreparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases.
There is a position called Data Analyst whose work is to analyze the historical data, and from that, they will derive some KPI s (Key Performance Indicators) for making any further calls. For Data Analysis you can focus on such topics as Feature Engineering , DataWrangling , and EDA which is also known as Exploratory Data Analysis.
Retrieval Augmented Generation (RAG) system can also use Vector databases to act as long-term memory for LLMs via embeddings, storing and retrieving relevant information based on semantic similarity. Tokens are vital to how LLMs understand and process information. This enhances the context awareness and factual accuracy of LLM outputs.
References : Links to internal or external documentation with background information or specific information used within the analysis presented in the notebook. Introduction & background : Put the task into context, add information about the key business precedents around the issue, and explain the task in more detail.
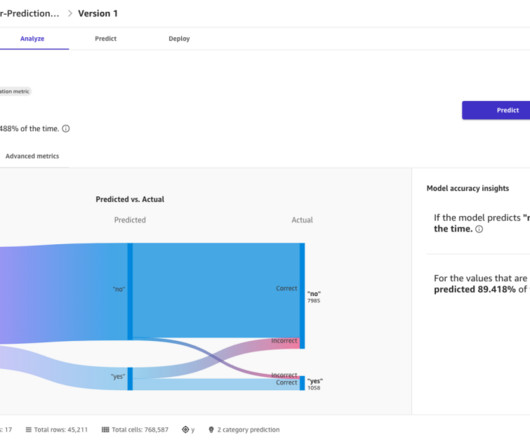
Amazon SageMaker Canvas is a low-code no-code (LCNC) ML platform that guides users through every stage of the ML journey, from initial datapreparation to final model deployment. Without writing a single line of code, users can explore datasets, transform data, build models, and generate predictions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content