
Data Preparation in R Cheatsheet
KDnuggets
JULY 5, 2022
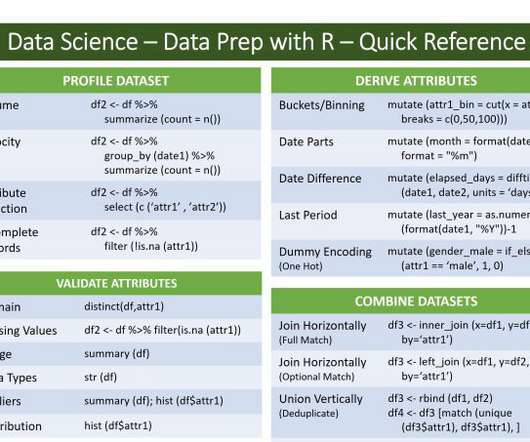
Leverage the powerful data wrangling tools in R’s dplyr to clean and prepare your data.
KDnuggets
JULY 5, 2022
Leverage the powerful data wrangling tools in R’s dplyr to clean and prepare your data.

AWS Machine Learning Blog
AUGUST 20, 2024
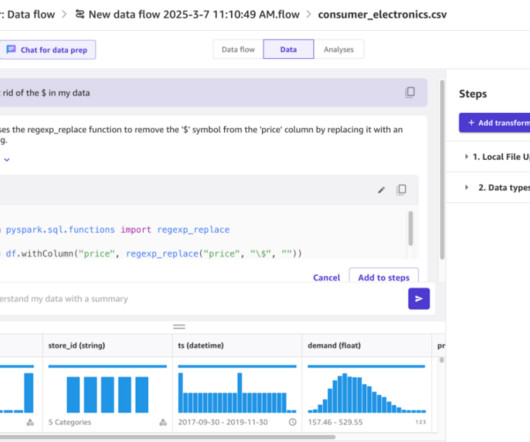
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate data preparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Charles holds an MS in Supply Chain Management and a PhD in Data Science. Huong Nguyen is a Sr.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
AWS Machine Learning Blog
JUNE 23, 2025
Traditional approaches require extensive knowledge of statistical methods and data science methods to process raw time series data. Amazon SageMaker Canvas offers no-code solutions that simplify data wrangling, making time series forecasting accessible to all users regardless of their technical background.
phData
NOVEMBER 4, 2024
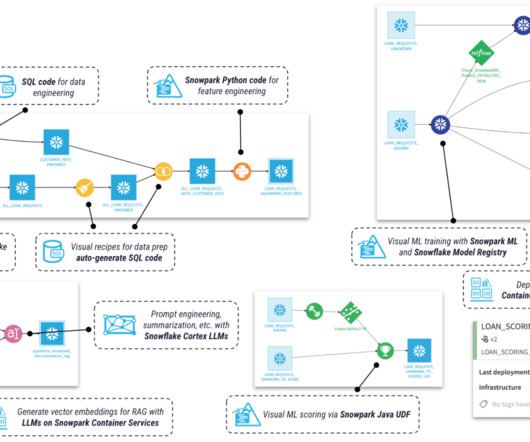
With data software pushing the boundaries of what’s possible in order to answer business questions and alleviate operational bottlenecks, data-driven companies are curious how they can go “beyond the dashboard” to find the answers they are looking for. One of the standout features of Dataiku is its focus on collaboration.
ODSC - Open Data Science
MARCH 13, 2023
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and data preparation.
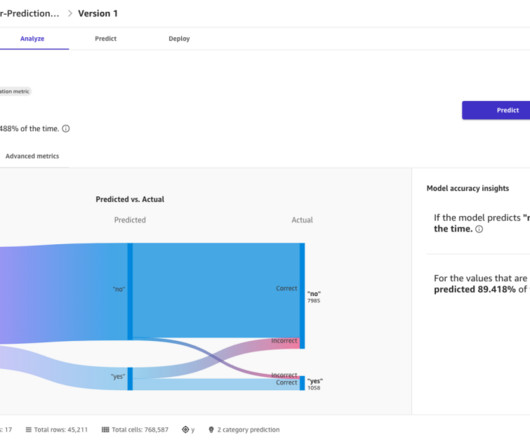
AWS Machine Learning Blog
AUGUST 21, 2024
Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular. You can review the generated Data Quality and Insights Report to gain a deeper understanding of the data, including statistics, duplicates, anomalies, missing values, outliers, target leakage, data imbalance, and more.

Towards AI
JUNE 25, 2024
As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. But here is a problem: While pySpark syntax is straightforward and very easy to follow, it can be readily confused with other common libraries for data wrangling.

Expert insights. Personalized for you.















Let's personalize your content