This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
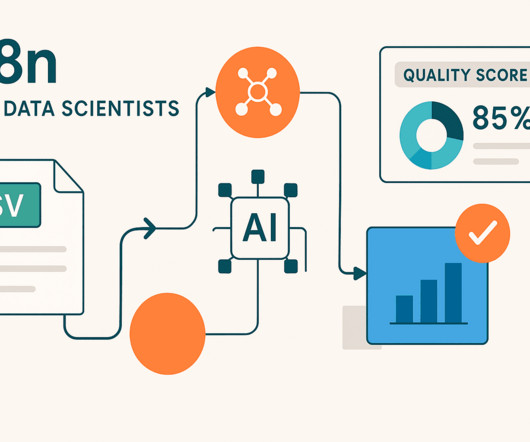
Whats the overall data quality score? Most datascientists spend 15-30 minutes manually exploring each new dataset—loading it into pandas, running.info() ,describe() , and.isnull().sum() sum() , then creating visualizations to understand missing data patterns. Which columns are problematic? Next Steps 1.
Datapreparation tools : Libraries such as Pandas, Scikit-learn pipelines, and Spark MLlib simplify data cleaning and transformation tasks. AutoML frameworks : Tools like Google AutoML and H2O.ai include automated feature engineering as part of their machine learning pipelines.
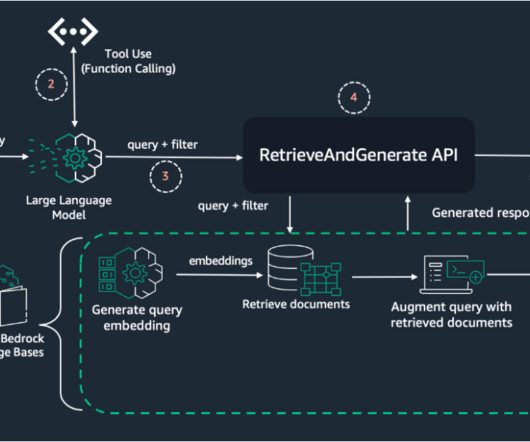
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
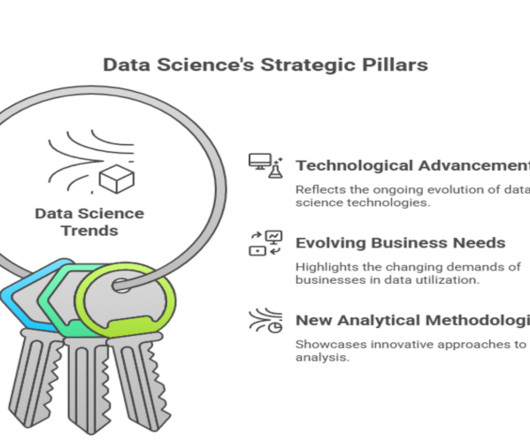
Trends in data science reflect technological advancements, evolving business needs, and new analytical methodologies that shape how data is collected, processed, and utilized. For datascientists and aspiring professionals, awareness of these trends guides skill development and career growth in a rapidly changing landscape.
Well highlight key features that allow your nonprofit to harness the power of ML without data science expertise or dedicated engineering teams. SageMaker Canvas guides users through the entire ML lifecycle using a point-and-click interface, built-in datapreparation tools, and automated model building capabilities.
Although rapid generative AI advancements are revolutionizing organizational naturallanguageprocessing tasks, developers and datascientists face significant challenges customizing these large models. There are three personas: admin, data engineer, and user, which can be a datascientist or an ML engineer.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring.
They are particularly effective in applications such as image recognition and naturallanguageprocessing, where traditional methods may fall short. By analyzing data from IoT devices, organizations can perform maintenance tasks proactively, reducing downtime and operational costs.
Start a distillation job with S3 JSONL data using an API To use an API to start a distillation job using training data stored in an S3 bucket, follow these steps: First, create and configure an Amazon Bedrock client: import boto3 from datetime import datetime bedrock_client = boto3.client(service_name="bedrock")
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
Datascientists and developers can quickly prototype and experiment with various ML use cases, accelerating the development and deployment of ML applications. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
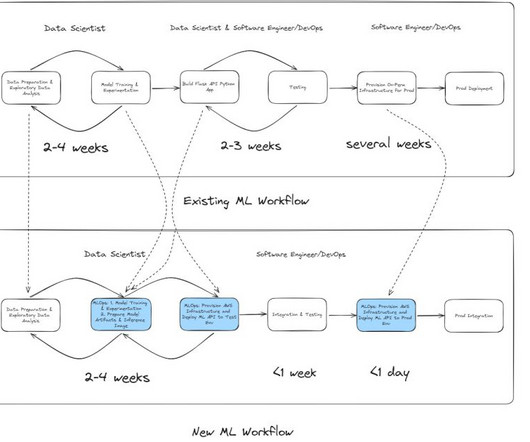
Scaling an on-premises infrastructure is typically a slow and resource-intensive process, hindering a businesss ability to adapt quickly to increased demand. Legacy workflow: On-premises ML development and deployment When the data science team needed to build a new fraud detection model, the development process typically took 24 weeks.
Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production.
Statistical analysis and hypothesis testing Statistical methods provide powerful tools for understanding data. An Applied DataScientist must have a solid understanding of statistics to interpret data correctly. Machine learning algorithms Machine learning forms the core of Applied Data Science.
This model can help organizations automate decision-making processes, freeing up human resources for more strategic tasks ( Image Credit ) Automation’s role is vital in decision intelligence Automation is playing an increasingly important role in decision intelligence. Featured image credit: Photo by Google DeepMind on Unsplash.
Learn how DataScientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of naturallanguageprocessing, modeling, data analysis, data cleaning, and data visualization. It also improves data analysis.
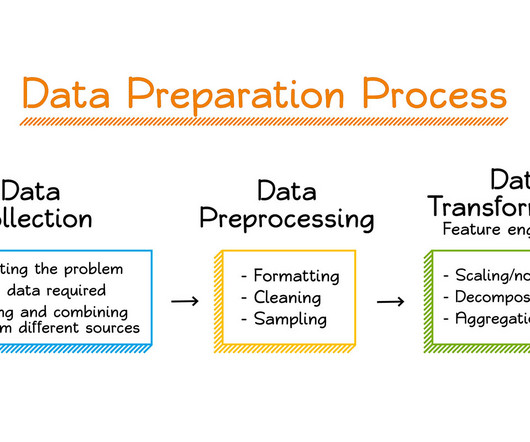
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
Processing unstructured data has become easier with the advancements in naturallanguageprocessing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend. We will be using the Data-Preparation notebook.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for naturallanguageprocessing (NLP) tasks. Hugging Face integrates seamlessly with SageMaker, which is a fully managed service that enables developers and datascientists to build, train, and deploy ML models at scale.
By implementing a modern naturallanguageprocessing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. The following diagram shows the workflow for our email classifier project, but can also be generalized to other data science projects.
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. These tools are becoming increasingly sophisticated, enabling the development of advanced applications.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. RPA and ML are two different technologies that serve different purposes.
Data preprocessing is a fundamental and essential step in the field of sentiment analysis, a prominent branch of naturallanguageprocessing (NLP). Missing data can lead to inaccurate results and biased analyses. In 2023, several data preprocessing tools have emerged as top choices for datascientists and analysts.
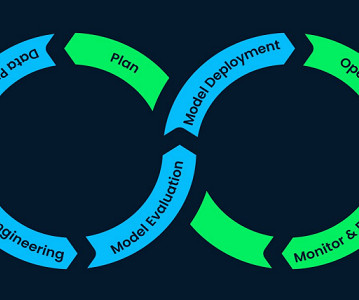
The Evolving AI Development Lifecycle Despite the revolutionary capabilities of LLMs, the core development lifecycle established by traditional naturallanguageprocessing remains essential: Plan, PrepareData, Engineer Model, Evaluate, Deploy, Operate, and Monitor. For instance: DataPreparation: GoogleSheets.
This post is co-written with Swagata Ashwani, Senior DataScientist at Boomi. First and foremost, Studio makes it easier to share notebook assets across a large team of datascientists like the one at Boomi. Swagata Ashwani is a Senior DataScientist at Boomi with over 6+ years experience in Data Science.
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and data governance processes.
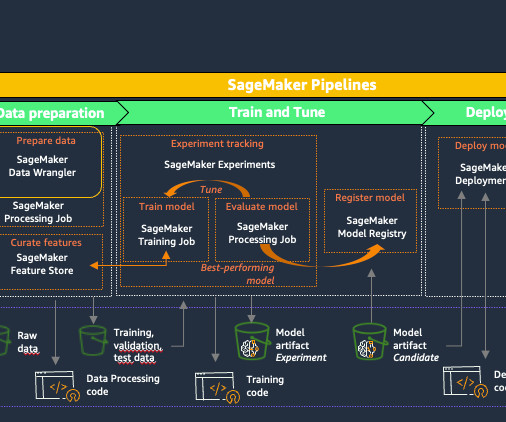
It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as datapreparation, model training, tuning and validation. However, the datascientist doesn’t want to run the entire pipeline workflow or deploy the model. .
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful dataprocessing capabilities of EMR Serverless. In his free time, he enjoys playing chess and traveling. You can find Pranav on LinkedIn.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. If you have administrator access to the account, no additional action is required.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the datascientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Solution overview This solution uses Amazon Comprehend and SageMaker Data Wrangler to automatically redact PII data from a sample dataset. Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required.
PyTorch For tasks like computer vision and naturallanguageprocessing, Using the Torch library as its foundation, PyTorch is a free and open-source machine learning framework that comes in handy. spaCy When it comes to advanced and intermedeate naturallanguageprocessing, spaCy is an open-source library workin in Python.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
It can be difficult to find insights from this data, particularly if efforts are needed to classify, tag, or label it. Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Now, we encourage you, our readers, to test these tools.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
These data owners are focused on providing access to their data to multiple business units or teams. Data science team – Datascientists need to focus on creating the best model based on predefined key performance indicators (KPIs) working in notebooks. The following figure illustrates their journey.
Because the machine learning lifecycle has many complex components that reach across multiple teams, it requires close-knit collaboration to ensure that hand-offs occur efficiently, from datapreparation and model training to model deployment and monitoring. Generative AI relies on foundation models to create a scalable process.
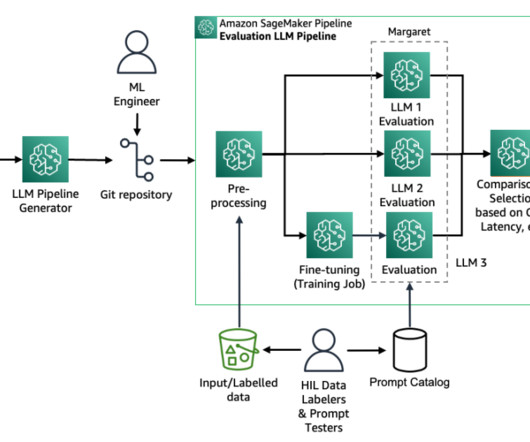
Large language models (LLMs) have achieved remarkable success in various naturallanguageprocessing (NLP) tasks, but they may not always generalize well to specific domains or tasks. Fine-tuning an LLM can be a complex workflow for datascientists and machine learning (ML) engineers to operationalize.
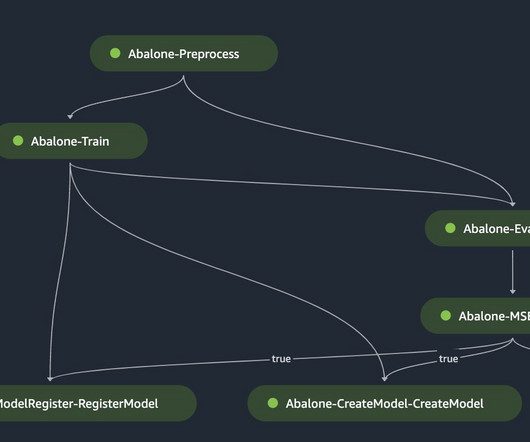
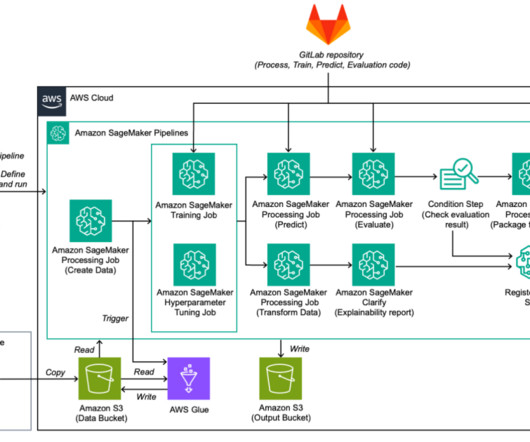
SageMaker pipeline steps The pipeline is divided into the following steps: Train and test datapreparation – Terabytes of raw data are copied to an S3 bucket, processed using AWS Glue jobs for Spark processing, resulting in data structured and formatted for compatibility.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
The rise of advanced technologies such as Artificial Intelligence (AI), Machine Learning (ML) , and Big Data analytics is reshaping industries and creating new opportunities for DataScientists. Automated Machine Learning (AutoML) will democratize access to Data Science tools and techniques.
Libraries and Extensions: Includes torchvision for image processing, touchaudio for audio processing, and torchtext for NLP. Notable Use Cases PyTorch is extensively used in naturallanguageprocessing (NLP), including applications like sentiment analysis, machine translation, and text generation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content