This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
14 Essential Git Commands for DataScientists • Statistics and Probability for DataScience • 20 Basic Linux Commands for DataScience Beginners • 3 Ways Understanding Bayes Theorem Will Improve Your DataScience • Learn MLOps with This Free Course • Primary Supervised Learning Algorithms Used in Machine Learning • DataPreparation with SQL Cheatsheet. (..)
As datascientists who are the brains behind the AI-based innovations, you need to understand the significance of datapreparation to achieve the desired level of cognitive capability for your models. Let’s begin.
As datascientists, we often invest significant time and effort in datapreparation, model development, and optimization. However, the true value of our work emerges when we can effectively interpret our findings and convey them to stakeholders.
As datascience evolves and grows, the demand for skilled datascientists is also rising. A datascientist’s role is to extract insights and knowledge from data and to use this information to inform decisions and drive business growth.
Datascientists play a crucial role in today’s data-driven world, where extracting meaningful insights from vast amounts of information is key to organizational success. As the demand for data expertise continues to grow, understanding the multifaceted role of a datascientist becomes increasingly relevant.
Datascience is reshaping the world in fascinating ways, unlocking the potential hidden within the vast amounts of data generated every day. As organizations realize the immense value of data-driven insights, the demand for skilled professionals who can harness this power is at an all-time high. What is datascience?
Big data and datascience in the digital age The digital age has resulted in the generation of enormous amounts of data daily, ranging from social media interactions to online shopping habits. quintillion bytes of data are created. This is where datascience plays a crucial role. What is datascience?
In the modern digital era, this particular area has evolved to give rise to a discipline known as DataScience. DataScience offers a comprehensive and systematic approach to extracting actionable insights from complex and unstructured data.
Today’s question is, “What does a datascientist do.” ” Step into the realm of datascience, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of datascientists.
The datascience profession has become highly complex in recent years. Datascience companies are taking new initiatives to streamline many of their core functions and minimize some of the more common issues that they face. Datascientists can access remote computing power through sophisticated networks.
The field of datascience is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for datascience hires peak. And Why did it happen?).
Well highlight key features that allow your nonprofit to harness the power of ML without datascience expertise or dedicated engineering teams. SageMaker Canvas guides users through the entire ML lifecycle using a point-and-click interface, built-in datapreparation tools, and automated model building capabilities.
Learn the essential skills needed to become a DataScience rockstar; Understand CNNs with Python + Tensorflow + Keras tutorial; Discover the best podcasts about AI, Analytics, DataScience; and find out where you can get the best Certificates in the field.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
With its decoupled compute and storage resources, Snowflake is a cloud-native data platform optimized to scale with the business. Dataiku is an advanced analytics and machine learning platform designed to democratize datascience and foster collaboration across technical and non-technical teams.
Datascientist time is a precious, expensive commodity. Do you truly understand what your datascience talent works on all day? Are they spending way too much time researching datascience theory, coding the same datapreparation tasks over and over again, and maintaining scripts for model factories?
This structured framework ensures that all necessary stepsfrom datapreparation to model monitoringare executed systematically, enhancing efficiency and effectiveness in both business and technology applications. The main components typically include datapreparation, model training, deployment, and ongoing monitoring.
This training should cover the basics of datascience, analytics, and machine learning. Automation can be used to automate a number of tasks involved in decision-making, such as data collection, datapreparation, and model deployment. However, there are some key differences between the two fields.
These tools provide a visual interface for building machine learning pipelines, making the process easier and more efficient for datascientists. These tools are designed to be user-friendly and do not require any coding skills, making it easier for datascientists to build models quickly and efficiently.
Dplyr is an essential package in R programming, particularly beneficial for data manipulation tasks. It streamlines datapreparation and analysis, making it easier for datascientists and analysts to extract insights from their datasets. Improves comprehension through a user-friendly syntax.
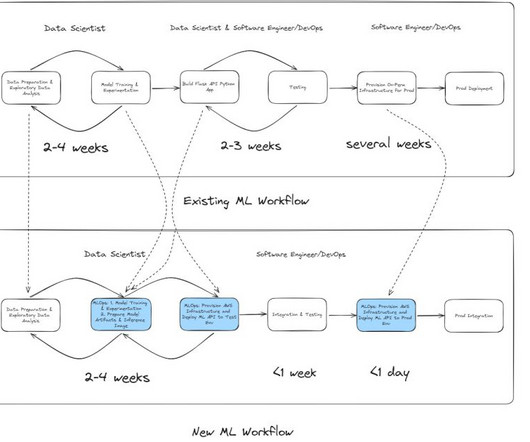
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and datapreparation activities.
Through data crawling, cataloguing, and indexing, they also enable you to know what data is in the lake. To preserve your digital assets, data must lastly be secured. Data Lakes compared to Data Warehouses – two different approaches What a data lake is not also helps to define it.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in DataScience using Microsoft Azure. DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling.
Summary: Demystify time complexity, the secret weapon for DataScientists. Explore practical examples, tools, and future trends to conquer big data challenges. Introduction to Time Complexity for DataScientists Time complexity refers to how the execution time of an algorithm scales in relation to the size of the input data.
Summary: The future of DataScience is shaped by emerging trends such as advanced AI and Machine Learning, augmented analytics, and automated processes. As industries increasingly rely on data-driven insights, ethical considerations regarding data privacy and bias mitigation will become paramount.
Learn how DataScientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, data analysis, data cleaning, and data visualization. It facilitates exploratory Data Analysis and provides quick insights.
Because ML is becoming more integrated into daily business operations, datascience teams are looking for faster, more efficient ways to manage ML initiatives, increase model accuracy and gain deeper insights. MLOps is the next evolution of data analysis and deep learning. How MLOps will be used within the organization.
Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. What to do next?
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Be sure to check out her talk, “ Hands-on Data-Centric AI: Datapreparation tuning — why and how? After all the datapreparation is time to re-train our baseline model. Have we achieved the performance expected?
Exploratory data analysis (EDA) is a critical component of datascience that allows analysts to delve into datasets to unearth the underlying patterns and relationships within. EDA serves as a bridge between raw data and actionable insights, making it essential in any data-driven project.
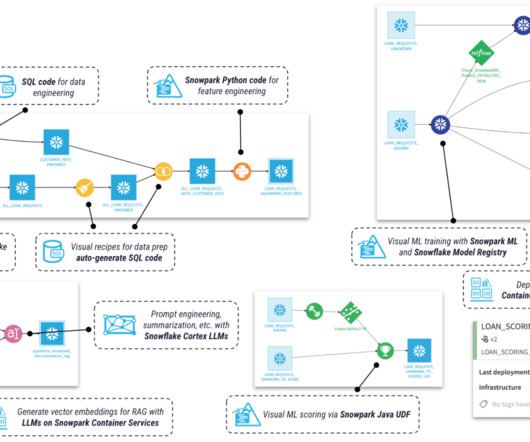
Scalable Capital’s datascience and client service teams identified that one of the largest bottlenecks in servicing our clients was responding to email inquiries. The following diagram shows the workflow for our email classifier project, but can also be generalized to other datascience projects.
On the model training side, datascientists often face bottlenecks due to limited resources, forcing them to wait for infrastructure availability or reduce the scope of their experiments. This delays innovation and can lead to suboptimal model performance, putting businesses at a disadvantage in a rapidly changing fraud landscape.
Summary: DataScience and AI are transforming the future by enabling smarter decision-making, automating processes, and uncovering valuable insights from vast datasets. Introduction DataScience and Artificial Intelligence (AI) are at the forefront of technological innovation, fundamentally transforming industries and everyday life.
Datascientists dedicate a significant chunk of their time to datapreparation, as revealed by a survey conducted by the datascience platform Anaconda. This process involves rectifying or discarding abnormal or non-standard data points and ensuring the accuracy of measurements.
By Carolyn Saplicki , IBM DataScientist Industries are constantly seeking innovative solutions to maximize efficiency, minimize downtime, and reduce costs. All datascientists could leverage our patterns during an engagement. We are leveraging Air Compressors data, but the solutions are generalizable.
Allen Downey, PhD, Principal DataScientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about datascience and Bayesian statistics. in computer science from the University of California, Berkeley; and Bachelors and Masters degrees fromMIT.
This may be a daunting task for a non-datascientist or a datascientist with little to no experience. This article will walk you though how to approach deep learning modeling through the MVI platform from datapreparation to your first deployment. You’re all set!
Summary: The DataScience and Data Analysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Understanding their life cycles is critical to unlocking their potential.
With all the talk about new AI-powered tools and programs feeding the imagination of the internet, we often forget that datascientists don’t always have to do everything 100% themselves. PyCaret allows data professionals to build and deploy machine learning models easily and efficiently. So why is this library so popular?
With the unification of SageMaker Model Cards and SageMaker Model Registry, architects, datascientists, ML engineers, or platform engineers (depending on the organization’s hierarchy) can now seamlessly register ML model versions early in the development lifecycle, including essential business details and technical metadata.
This post is co-written with Swagata Ashwani, Senior DataScientist at Boomi. Boomi’s datascience team implemented a Markov chain model that could be applied to common integration sequences, or steps, on their platform, hence the name Step Suggest. These tools integrate via API into Boomi’s core service offering.
These statistical models are growing as a result of the wide swaths of available current data as well as the advent of capable artificial intelligence and machine learning. Data Sourcing. The applications of predictive analytics are extensive and often require four key components to maintain effectiveness.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. A datascientist team orders a new JuMa workspace in BMW’s Catalog.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































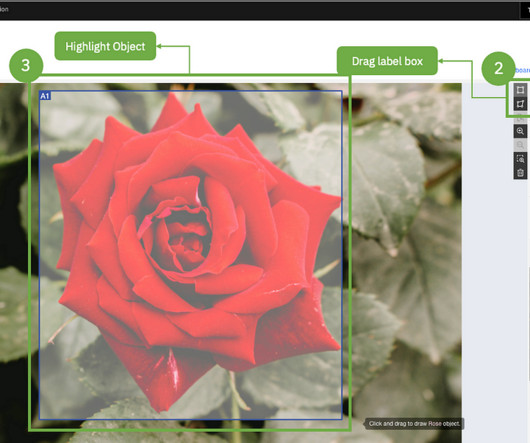



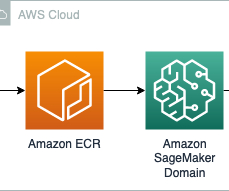








Let's personalize your content