This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
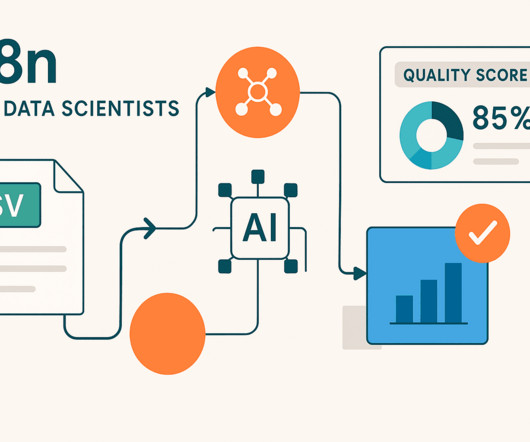
🔗 Link to the code on GitHub Why Data Cleaning Pipelines? Think of datapipelines like assembly lines in manufacturing. Performance optimization : For large datasets, consider using vectorized operations or parallel processing. Wrapping Up Datapipelines arent just about cleaning individual datasets.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
As the world becomes more interconnected and data-driven, the demand for real-time applications has never been higher. Artificial intelligence (AI) and naturallanguageprocessing (NLP) technologies are evolving rapidly to manage live data streams.
Scheduled Analysis Replace the Manual Trigger with a Schedule Trigger to automatically analyze datasets at regular intervals, perfect for monitoring data sources that update frequently. This proactive approach helps you identify datapipeline issues before they impact downstream analysis or model performance.
Chronos is founded on a key insight: both LLMs and time series forecasting aim to decode sequential patterns to predict future events. This parallel allows us to treat time series data as a language to be modeled by off-the-shelf transformer architectures. Outside of work, he enjoys game development and rock climbing.
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
Ideal for building forecasting models or studying market reactions to events. Global Economic Indicators (2010–2023): Offers data on GDP, inflation, employment, and trade for dozens of countries — perfect for comparative studies. Zillow Economics Data: This dataset captures U.S. housing prices by ZIP code.
Data Engineering for Large Language Models LLMs are artificial intelligence models that are trained on massive datasets of text and code. They are used for a variety of tasks, such as naturallanguageprocessing, machine translation, and summarization. Interested in attending an ODSC event?
Brian Chesky, CEO of Airbnb, spoke at a Y Combinator event this summer. (Y The companies include: Talc AI, a service for assessing large language models. We borrow proven techniques from the latest in NLP (naturallanguageprocessing) academia to build evaluation tooling that any software engineer can use.
Amazon Kendra uses naturallanguageprocessing (NLP) to understand user queries and find the most relevant documents. For our final structured and unstructured datapipeline, we observe Anthropic’s Claude 2 on Amazon Bedrock generated better overall results for our final datapipeline.
Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Artificial Intelligence : Concepts of AI include neural networks, naturallanguageprocessing (NLP), and reinforcement learning.
In these applications, time series data can have heavy-tailed distributions, where the tails represent extreme values. Accurate forecasting in these regions is important in determining how likely an extreme event is and whether to raise an alarm. However, the extreme event will have zero probability.
Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processingdata. They use their knowledge of data warehousing, data lakes, and big data technologies to build and maintain datapipelines. Interested in attending an ODSC event?
MLOps aims to bridge the gap between data science and operational teams so they can reliably and efficiently transition ML models from development to production environments, all while maintaining high model performance and accuracy. AIOps integrates these models into existing IT systems to enhance their functions and performance.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. Interested in attending an ODSC event?
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data. In addition to naturallanguage, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
From state-of-the-art language models to innovative AI-driven applications, to new open-source models hoping to take away GPT’s crown, let’s take a tour of some of the most notable AI tools and top LLMs that are working to shape how 2024 concludes, and how AI will shape the future. Interested in attending an ODSC event?
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions. You need to find a place to park your data.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions. You need to find a place to park your data.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
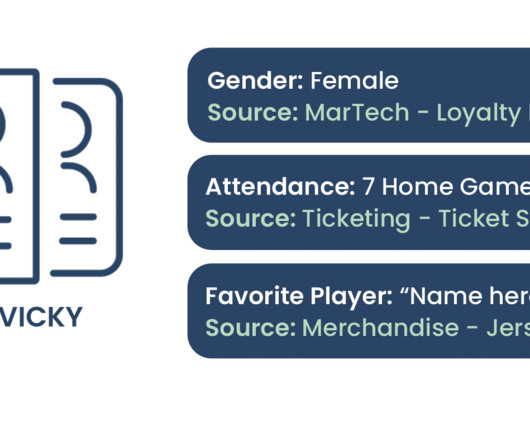
This allows proactive and targeted engagement strategies, such as predicting attendance for specific events, tailoring promotions, and optimizing marketing efforts. Integrating naturallanguageprocessing capabilities allows for more human-like interactions, enhancing the overall fan experience.
NaturalLanguageProcessing (NLP) has emerged as a dominant area, with tasks like sentiment analysis, machine translation, and chatbot development leading the way. Data Engineering Data engineering remains integral to many data science roles, with workflow pipelines being a key focus.
DL is particularly effective in processing large amounts of unstructured data, such as images, audio, and text. NaturalLanguageProcessing (NLP) : NLP is a branch of AI that deals with the interaction between computers and human languages.
Socio-political events have also caused delays and issues, such as a COVID backlog, and with inert gases for manufacturing coming from Russia. The benchmark used is the RoBERTa-Base, a popular model used in naturallanguageprocessing (NLP) applications, that uses the transformer architecture.
Long Short-Term Memory (LSTM) A type of recurrent neural network (RNN) designed to learn long-term dependencies in sequential data. Facebook Prophet A user-friendly tool that automatically detects seasonality and trends in time series data. This is vital for agriculture, disaster management, and event planning.
Data Scientists can use Azure Data Factory to prepare data for analysis by creating datapipelines that ingest data from multiple sources, clean and transform it, and load it into Azure data stores.
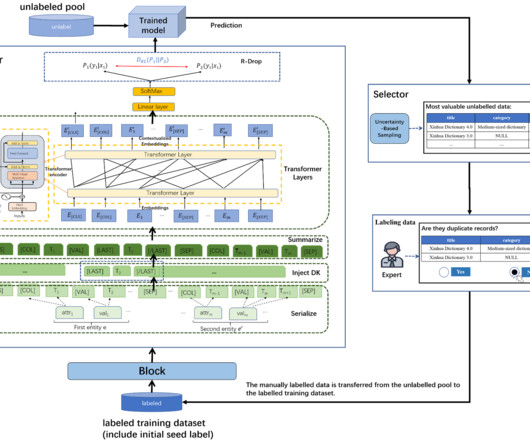
Similar Audio: Audio recordings of the same event or sound but with different microphone placements or background noise. It would help to improve the process in future by creating a clear audit trail of how duplicate records are identified and handled throughout the datapipeline.
The service will consume the features in real time, generate predictions in near real-time , such as in an eventprocessingpipeline, and write the outputs to a prediction queue. Solution Data lakes and warehouses are the two key components of any datapipeline. Data engineers are mostly in charge of it.
Query Synthesis Scenario : Training a model to classify rare astronomical events using synthetic telescope data. Libact : It is a Python package for active learning. It provides implementations of various active learning algorithms like uncertainty sampling, query-by-committee, and density-weighted methods.
Encora also partners with BFSI clients to develop scalable, AI-driven EWS and real-time datapipelines using cloud-native architectures. Mhaskar highlighted that the company uses naturallanguageprocessing (NLP) to analyse digital interactions and understand customer behaviour.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls. I've secured $1.7M ecosystems.
David: My technical background is in ETL, data extraction, data engineering and data analytics. I spent over a decade of my career developing large-scale datapipelines to transform both structured and unstructured data into formats that can be utilized in downstream systems.
Internally within Netflix’s engineering team, Meson was built to manage, orchestrate, schedule, and execute workflows within ML/Datapipelines. Meson managed the lifecycle of ML pipelines, providing functionality such as recommendations and content analysis, and leveraged the Single Leader Architecture.
But the most impactful developments may be those focused on governance, middleware, training techniques and datapipelines that make generative AI more trustworthy , sustainable and accessible, for enterprises and end users alike. Here are some important current AI trends to look out for in the coming year.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content