This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Airflow: Apache Airflow is an open-source platform for orchestrating and scheduling datapipelines.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
In the data analytics processes, choosing the right tools is crucial for ensuring efficiency and scalability. Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable datapipelines.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. Room for improvement!
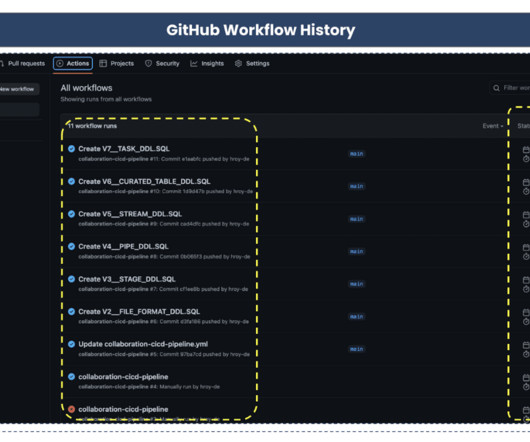
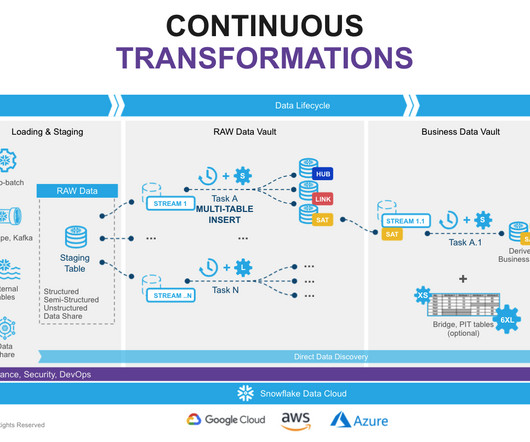
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provides a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. What is Matillion ETL?
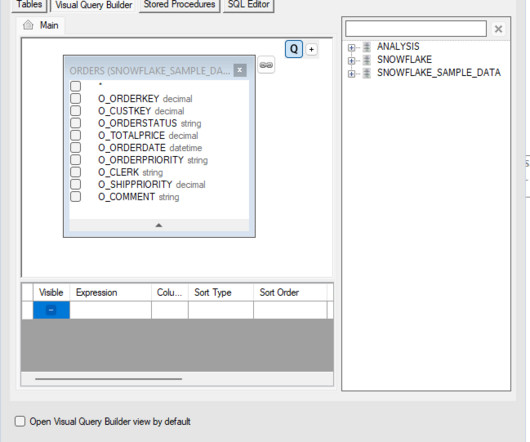
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provide a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. In our case, this table is “orders.”
Automation Automating datapipelines and models ➡️ 6. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data. The Data Engineer Not everyone working on a data science project is a data scientist.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Fivetran’s automated data movement platform simplifies the ETL (extract, transform, load) process by automating most of the time-consuming tasks of ETL that data engineers would typically do.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
Putting the T for Transformation in ELT (ETL) is essential to any datapipeline. After extracting and loading your data into the Snowflake AI Data Cloud , you may wonder how best to transform it. What are Snowflake’s Best Features for Data Transformation?
Evaluate integration capabilities with existing data sources and Extract Transform and Load (ETL) tools. Its PostgreSQL foundation ensures compatibility with most SQL clients. Strengths : Real-time analytics, built-in machine learning capabilities, and fast querying with standard SQL.
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. Related post MLOps Is an Extension of DevOps.
For those unfamiliar with GIT or GIT practices, please refer Git for Business Users with Matillion DPC What is a Matillion Pipeline? A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud data warehouse like Snowflake.
In order to fully leverage this vast quantity of collected data, companies need a robust and scalable data infrastructure to manage it. This is where Fivetran and the Modern Data Stack come in. This complexity often requires many hours of work from a large data engineering team to build and manually manage datapipelines.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring data quality and integrity.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
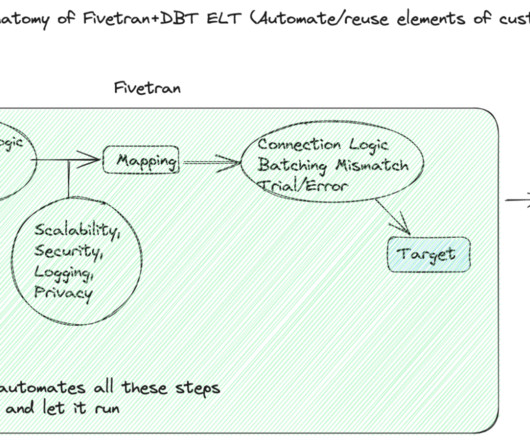
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
The story is all too common – a business user requests some data, the data team creates/prioritizes a ticket, and said ticket is completed after some number of months (or weeks if you’re lucky) – just to have the data be wrong, and the whole process starts again. Those are scary for data teams to change.
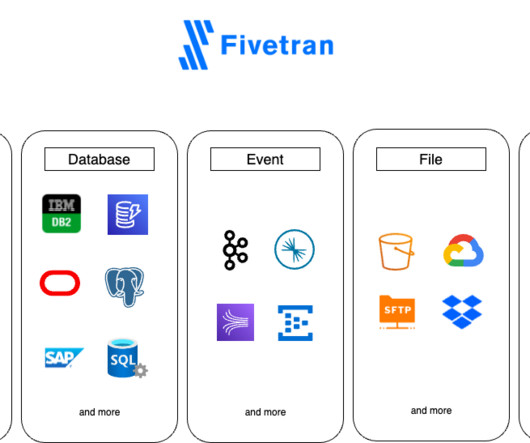
Some of the databases supported by Fivetran are: Snowflake Data Cloud (BETA) MySQL PostgreSQL SAP ERP SQL Server Oracle In this blog, we will review how to pull Data from on-premise Systems using Fivetran to a specific target or destination. Databases often write more information to a transaction log than is required.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT.
You don’t have to write ETL jobs.” That lowers the barrier to entry because you don’t have to be an ETL developer. DataPipeline Capabilities This team’s scope is massive because the datapipelines are huge and there are many different capabilities embedded in them. Invest in automation.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
There’s no need for developers or analysts to manually adjust table schemas or modify ETL (Extract, Transform, Load) processes whenever the source data structure changes. Time Efficiency – The automated schema detection and evolution features contribute to faster data availability.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python, Java, and Scala. A DataFrame is like a query that must be evaluated to retrieve data. An action causes the DataFrame to be evaluated and sends the corresponding SQL statement to the server for execution.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















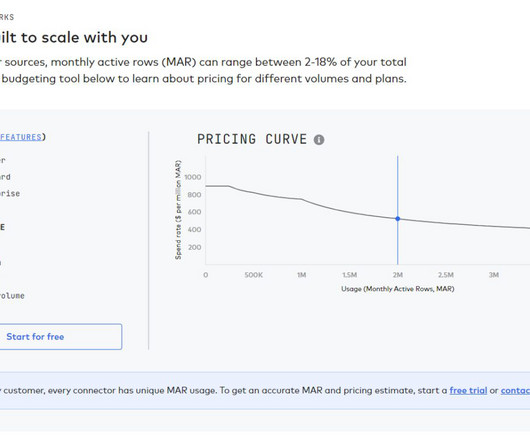


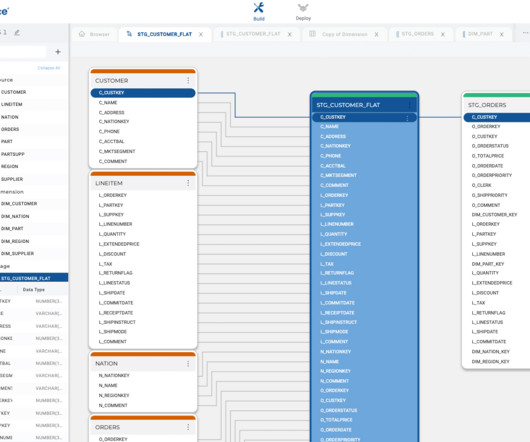
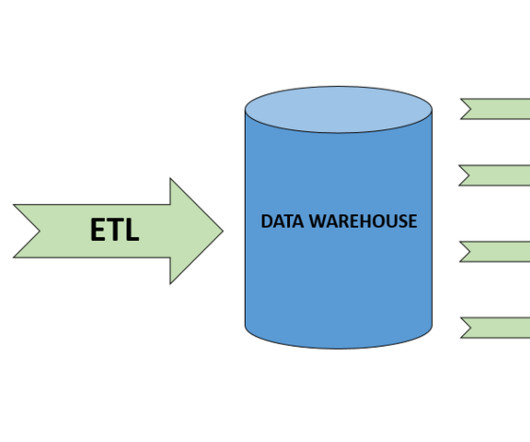















Let's personalize your content