This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
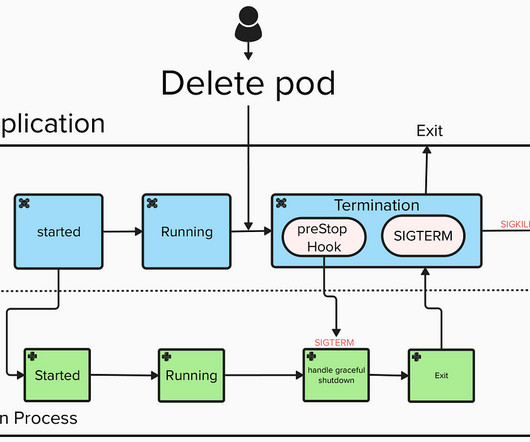
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
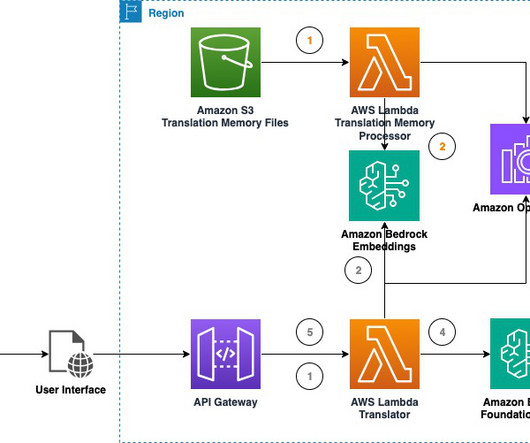
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. This is covered in detail later in the post.
However, they can’t generalize well to enterprise-specific questions because, to generate an answer, they rely on the public data they were exposed to during pre-training. However, the popular RAG design pattern with semantic search can’t answer all types of questions that are possible on documents.
Better documentation with more examples , clearer explanations of the choices and tools, and a more modern look and feel. Find the latest at [link] (the old documentation will redirect here shortly). This better reflects the common Python practice of having your top level module be the project name. CCDS tests : V1 has no tests.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Provide connectors for data sources: Orchestration frameworks typically provide connectors for a variety of data sources, such as databases, cloud storage, and APIs. This makes it easy to connect your datapipeline to the data sources that you need. It is known for its ease of use and flexibility.
Use case In this example of an insurance assistance chatbot, the customers generative AI application is designed with Amazon Bedrock Agents to automate tasks related to the processing of insurance claims and Amazon Bedrock Knowledge Bases to provide relevant documents. getOutstandingPaperwork What are the missing documents from {{claim}}?
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
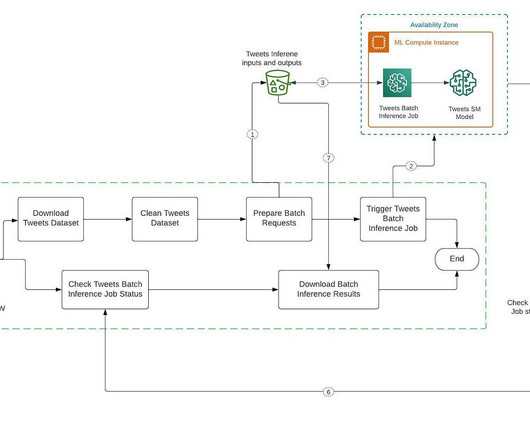
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc.
Photo by AltumCode on Unsplash As a data scientist, I used to struggle with experiments involving the training and fine-tuning of large deep-learning models. It facilitates the creation of various datapipelines, including tasks such as data transformation, model training, and the storage of all pipeline outputs.
You can easily: Store and process data using S3 and RedShift Create datapipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable datapipelines.
This personalized document helps the customer gain a deeper understanding of the vehicle and supports their decision-making process. In the application layer, the GUI for the solution is created using Streamlit in Python language.
The following are sample user queries: Write a Python function to validate email address syntax. For building and designing software applications, you will use the existing Knowledge Base on AWS well-architected framework to generate a response of the most relevant design principles and links to any documents.
The visualization of the data is important as it gives us hidden insights and potential details about the dataset and its pattern, which we may miss out on without data visualization. PowerBI, Tableau) and programming languages like R and Python in the form of bar graphs, scatter line plots, histograms, and much more.
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. Output is a fully self-contained HTML application. You can watch it on demand here.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. He specializes in designing, building, and optimizing large-scale data solutions.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc.
As AI and data engineering continue to evolve at an unprecedented pace, the challenge isnt just building advanced modelsits integrating them efficiently, securely, and at scale. This session explores open-source tools and techniques for transforming unstructured documents into structured formats like JSON and Markdown.
Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code. Comments and Notes: Documenting for Future You (or Someone Else) Good documentation makes life easiernot just for you but for anyone who might need to pick up your work later.
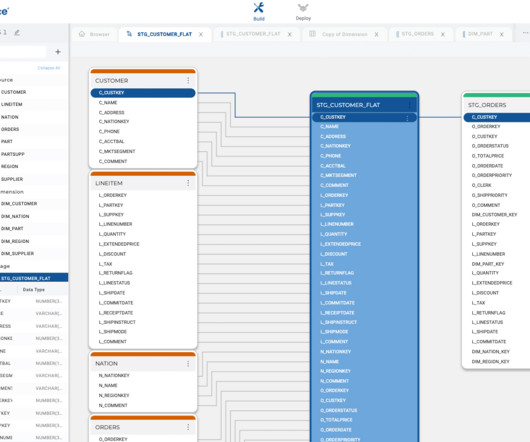
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern data engineering and analytics workflows.
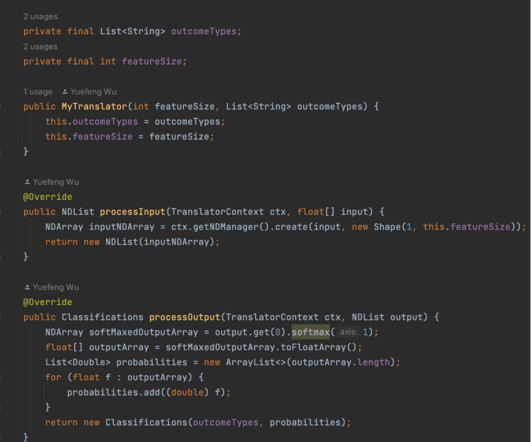
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. When we did our research online, the Deep Java Library showed up on the top. With v0.21.0
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
Putting the T for Transformation in ELT (ETL) is essential to any datapipeline. After extracting and loading your data into the Snowflake AI Data Cloud , you may wonder how best to transform it. Luckily, Snowflake answers this question with many features designed to transform your data for all your analytic use cases.
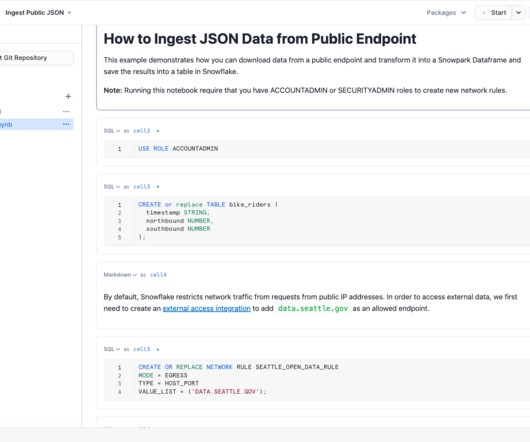
Cortex Search : This feature provides a search solution that Snowflake fully manages from data ingestion, embedding, retrieval, reranking, and generation. Use cases for this feature include needle-in-a-haystack lookups and multi-document synthesis and reasoning. Furthermore, Snowflake Notebooks can also be run on a schedule.
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects. Data Versioning In ML projects, keeping track of datasets is very important because the data can change over time.
Implementing proper version control in ML pipelines is essential for efficient management of code, data, and models by ensuring reproducibility and collaboration. Reproducibility ensures that experiments can be reliably reproduced by tracking changes in code, data, and model hyperparameters.
In addition, MLOps practices like building data, experting tracking, versioning, artifacts and others, also need to be part of the GenAI productization process. For example, when indexing a new version of a document, it’s important to take care of versioning in the ML pipeline. This helps cleanse the data.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Memory : Storing and retrieving data while conversing.
Hydra is a powerful Python-based configuration management framework designed to simplify the complexities of handling configurations in Machine Learning (ML) workflows and other projects. It also simplifies managing configuration dependencies in Deep Learning projects and large-scale datapipelines. What is Hydra?
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Although data scientists rightfully capture the spotlight, future-focused teams also include engineers building datapipelines, visualization experts, and project managers who integrate efforts across groups. Usability Do interfaces and documentation enable business analysts and data scientists to leverage systems?
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
Solution overview SageMaker algorithms have fixed input and output data formats. But customers often require specific formats that are compatible with their datapipelines. Option A In this option, we use the inference pipeline feature of SageMaker hosting. We use the SageMaker Python SDK for this purpose.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. Then software development phases are planned to deliver the software.
or as narrow as a couple of Python projects developed by a small team thrown into a single repository. These pipelines might be tightly integrated with the ML code. Keeping the datapipelines and ML code in the same repo helps maintain this tight integration and streamline the workflow. Take testing.
Summary: In 2024, mastering essential Data Science tools will be pivotal for career growth and problem-solving prowess. Tools like Seaborn, R, Python, and PyTorch are integral for extracting actionable insights and enhancing career prospects. It offers various libraries and frameworks for various Data Science tasks.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content