This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
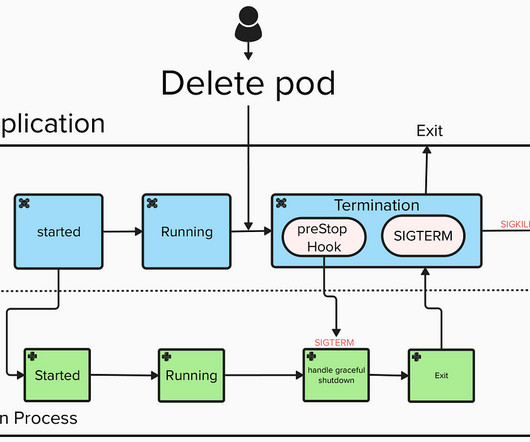
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Hello from our new, friendly, welcoming, definitely not an AI overlord cookie logo! This better reflects the common Python practice of having your top level module be the project name. Ruff is also emerging as a great all-purpose formatter and linter for Python codebases and may be an option in later CCDS versions.
Dataforge-Economics: A resource built to train models in economic literacy, offering definitions, concepts, and structured insights for educational or modeling use. Integration with Excel, Python (fredapi), and R. Our World in Data : Research-backed datasets on global issues — poverty, energy, climate, and more.
.” — Conor Murphy , Lead Data Scientist at Databricks, in “Survey of Production ML Tech Stacks” at the Data+AI Summit 2022 Your team should be motivated by MLOps to show everything that goes into making a machine learning model, from getting the data to deploying and monitoring the model. AIIA MLOps blueprints.
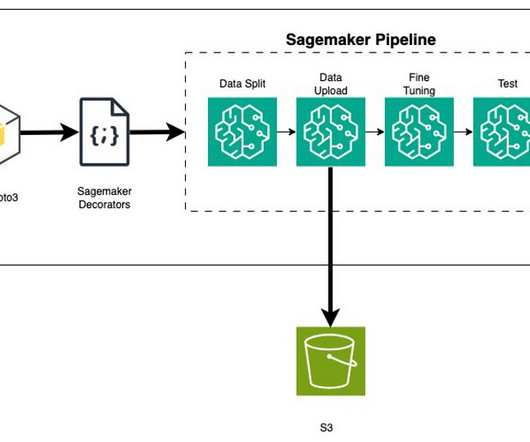
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources. We use Python to do this.
With their technical expertise and proficiency in programming and engineering, they bridge the gap between data science and software engineering. Programming skills: Data scientists should be proficient in programming languages such as Python, R, or SQL to manipulate and analyze data, automate processes, and develop statistical models.
The agent can generate SQL queries using natural language questions using a database schema DDL (datadefinition language for SQL) and execute them against a database instance for the database tier. The following are sample user queries: Write a Python function to validate email address syntax.
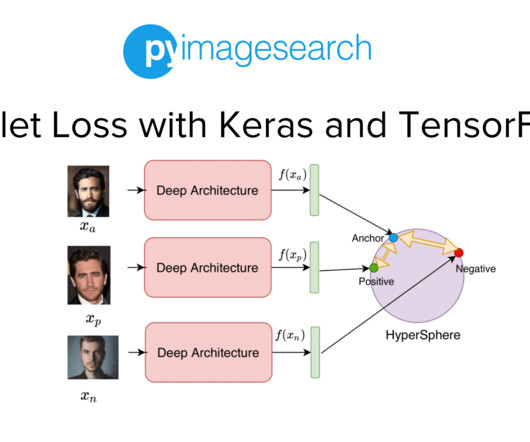
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Data science is an interdisciplinary field that utilizes advanced analytics techniques to extract meaningful insights from vast amounts of data. This helps facilitate data-driven decision-making for businesses, enabling them to operate more efficiently and identify new opportunities.
To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. Much of what we found was to be expected, though there were definitely a few surprises. While knowing Python, R, and SQL are expected, you’ll need to go beyond that.
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern data engineering and analytics workflows.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select.
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Designing the prompt Before starting any scaled use of generative AI, you should have the following in place: A clear definition of the problem you are trying to solve along with the end goal. Prerequisites To follow along with this post, set up Amazon SageMaker Studio to run Python in a notebook and interact with Amazon Bedrock.
This blog will cover creating customized nodes in Coalesce, what new advanced features can already be used as nodes, and how to create them as part of your datapipeline. To create a UDN, we’ll need a node definition that defines how the node should function and templates for how the object will be created and run.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. It integrates smoothly with other data processing libraries like Spark, Pandas, NumPy, and more, as well as ML frameworks like TensorFlow and PyTorch. This allows building end-to-end datapipelines and ML workflows on top of Ray.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
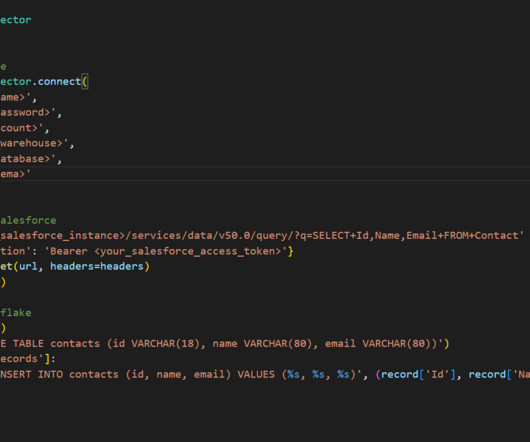
Here’s an example of code that can be used to extract Salesforce data and load it into Snowflake using Python: 2. Third-Party Tools Third-party tools like Matillion or Fivetran can help streamline the process of ingesting Salesforce data into Snowflake.
Definitions: Foundation Models, Gen AI, and LLMs Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements: Foundation Models (FMs) - Large deep learning models that are pre-trained with attention mechanisms on massive datasets. This helps cleanse the data.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
or as narrow as a couple of Python projects developed by a small team thrown into a single repository. These pipelines might be tightly integrated with the ML code. Keeping the datapipelines and ML code in the same repo helps maintain this tight integration and streamline the workflow. Take testing.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
Reichental describes data governance as the overarching layer that empowers people to manage data well ; as such, it is focused on roles & responsibilities, policies, definitions, metrics, and the lifecycle of the data. In this way, data governance is the business or process side. This is a very good thing.
Implementing Precision and Recall Calculations in Python Now that we have defined and segregated our samples into True Positives , True Negatives , False Positives , and False Negatives , let us try to use them to compute specific metrics to evaluate our model. label_pred !=1 1 ), and their ground-truth label was positive ( label_gt =1 ).
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Consider a datapipeline that detects its own failures, diagnoses the issue, and recommends the fix—all automatically. This is the potential of self-healing pipelines, and this blog explores how to implement them using dbt, Snowflake Cortex , and GitHub Actions. python/requirements.txt - name: Trigger dbt job run: | python -u./python/run_monitor_and_self_heal.py
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. Advise on getting started on topics Recommend get started materials Explain an implementation Explain general concepts in specific industry domain (e.g.
It is a process for moving and managing data from various sources to a central data warehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. Definition and Explanation of the ETL Process ETL is a data integration method that combines data from multiple sources.
Specifically, we will develop our datapipeline, implement the loss functions discussed in Part 1 and write our own code to train the CycleGAN model end-to-end using Keras and TensorFlow. With this, we finish the definition of our TrainMonitor class. Finally, we combine and consolidate our entire training data (i.e.,
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA platform is used through complier directives and extensions to standard languages, such as the Python cuNumeric library.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
The datapipelines can be scheduled as event-driven or be run at specific intervals the users choose. Below are some pictorial representations of simple ETL operations we used for data transformation. For that, we used another pipeline based on AWS Glue. For more information, please refer to this video.
That’s why many organizations invest in technology to improve data processes, such as a machine learning datapipeline. However, data needs to be easily accessible, usable, and secure to be useful — yet the opposite is too often the case. Narrow the scope It’s tempting to mark huge swaths of data as critical.
Next, it provides a deep dive into the anatomy of an AI Agent, examining its definition, role, and practical applications, including how LLMs, memory, and tools work together. Finally, participants will build their own AI Agent from scratch using Python and AI orchestrators like LangChain.
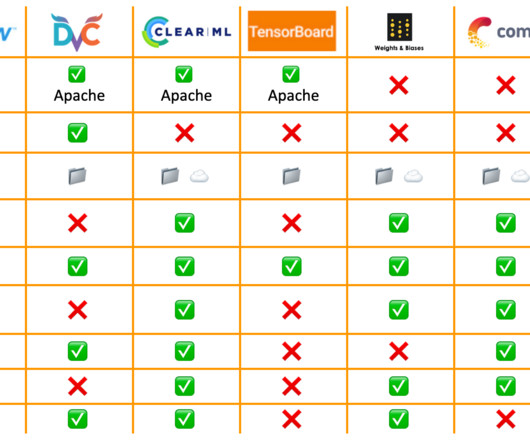
The Git integration means that experiments are automatically reproducible and linked to their code, data, pipelines, and models. We can interact with the platform using either a web interface or a Python API. ClearML allows multiple users to collaborate on the same project, enabling easy sharing of experiments and data.
You should look for a data warehouse that is scalable, flexible, and efficient. Popular cloud data warehouses today include Snowflake, Databricks, and BigQuery. If your organization is large, you definitely need to look for robustness. Good data warehouses should be reliable.
dustanbower 7 minutes ago | next [–] Location: Virginia, United States Remote: Yes (have worked exclusively remotely for past 14 years) Willing to relocate: No I've been doing backend work for the past 14 years, with Python, Django, and Django REST Framework. Interested in Python work or full-stack with Python.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. Data extraction and massage, delivery to destinations like Google/Meta/TikTok/etc.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content