This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
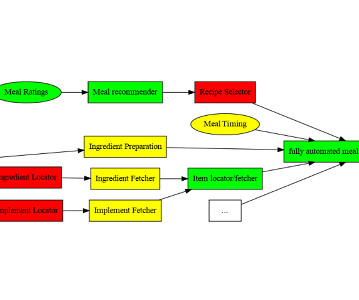
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in datascience and data engineering. They transform data into a consistent format for users to consume.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Spark offers a rich set of libraries for data processing, machine learning, graph processing, and stream processing.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Learning these tools is crucial for building scalable datapipelines. offers DataScience courses covering these tools with a job guarantee for career growth. Introduction Imagine a world where data is a messy jungle, and we need smart tools to turn it into useful insights.
Google Cloud Vertex AI Google Cloud Vertex AI provides a unified environment for both automated model development with AutoML and custom model training using popular frameworks. Qwak Qwak is a fully-managed, accessible, and reliable ML platform to develop and deploy models and monitor the entire machine learning pipeline.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Institute of Analytics The Institute of Analytics is a non-profit organization that provides datascience and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic datascience concepts to advanced machine learning techniques.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Matúš Chládek is a Senior Engineering Manager for ML Ops at Zeta Global.
Unfortunately, even the datascience industry — which should recognize tabular data’s true value — often underestimates its relevance in AI. Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any datascience and machine learning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
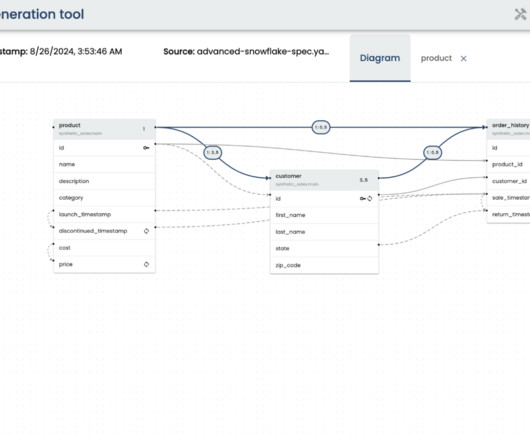
In order to fully leverage this vast quantity of collected data, companies need a robust and scalable data infrastructure to manage it. This is where Fivetran and the Modern Data Stack come in. Datamodeling, data cleanup, etc. Fivetran is a critical member of the Modern Data Stack. What is Fivetran?
How can we build up toward our vision in terms of solvable data problems and specific data products? data sources or simpler datamodels) of the data products we want to build? A data product may aim to automate a decision, or it may aim to assist a human decision-maker. What are we working towards?
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
I’ve moved from building user interfaces and backend systems to designing datamodels, creating datapipelines, and gaining valuable insights from complex datasets. This journey has reshaped my career from a software generalist to a data specialist. Outside of work, what's your life like?
As you can imagine, datascience is a pretty loose term or big tent idea overall. Though just about every industry imaginable utilizes the skills of a data-focused professional, each has its own challenges, needs, and desired outcomes. What makes this job title unique is the “Swiss army knife” approach to data.
Production App - Build resilient and modular production pipelines with automation, scale, testing, observability, versioning, security, risk handling, etc. Monitoring - Monitor all resources, data, model and application metrics to ensure performance. This helps cleanse the data.
This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 DataScience tools for 2024. It is a process for moving and managing data from various sources to a central data warehouse.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
DagsHub is a centralized platform to host and manage machine learning projects, including code, data, models, experiments, annotations, model registry, and more! Intermediate DataPipeline : Build datapipelines using DVC for automation and versioning of Open Source Machine Learning projects.
At this level, the datascience team will be small or nonexistent. Businesses will then require more information-literate staff, but they’ll need to contend with an ongoing shortage of data scientists. By now, data scientists have witnessed success optimizing internal operations and external offerings through AI.
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Union of business and data teams The success of ML projects lies in the strong collaboration between the data team and the business team. Such continuous alliance of the business team helps the datascience team to create ML models that have the potential to add significant business value.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. What does a modern data architecture do for your business?
By leveraging version control, testing, and documentation features, dbt Core enables teams to ensure data quality and consistency across their pipelines while integrating seamlessly with modern data warehouses. Aside from migrations, Data Source is also great for data quality checks and can generate datapipelines.
For datascience practitioners, productization is key, just like any other AI or ML technology. This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more.
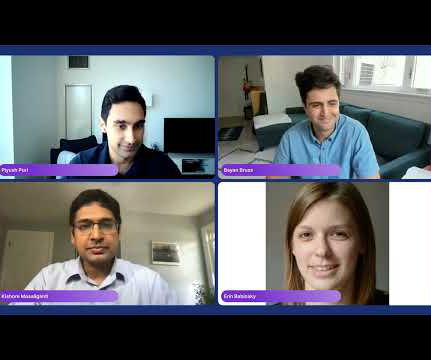
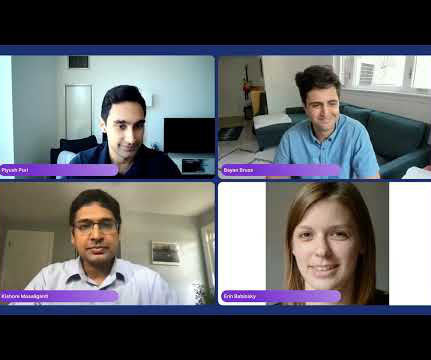
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
For datascience practitioners, productization is key, just like any other AI or ML technology. This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more.
Security is Paramount Implement robust security measures to protect sensitive time series data. Integration with DataPipelines and Analytics TSDBs often work in tandem with other data tools to create a comprehensive data ecosystem for analysis and insights generation.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for data scientists.
With collaborative coding tools, DagsHub provides a central location for datascience teams to visualize, compare, and review their experiments, eliminating the need to set up any infrastructure. DagsHub detects and supports DVC's metrics and params file formats, and it also sets up a DVC remote where we can version our data.
What frameworks and operating models have you seen work well? The firms that get data governance and management “right” bring people together and leverage a set of capabilities: (1) Agile; (2) Six sigma; (3) datascience; and (4) project management tools. Establishing a solid vision and mission is key.
Advanced Analytics: Snowflake’s platform is purposefully engineered to cater to the demands of machine learning and AI-driven datascience applications in a cost-effective manner. No Hardware Provisioning: No hardware to provision, just a t-shirt-sized warehouse available as needed within seconds.
Data can change a lot, models may also quickly evolve and dependencies become old-fashioned which makes it hard to maintain consistency or reproducibility. With weak version control, teams could face problems like inconsistent data, model drift , and clashes in their code.
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages. Happy pipelining!
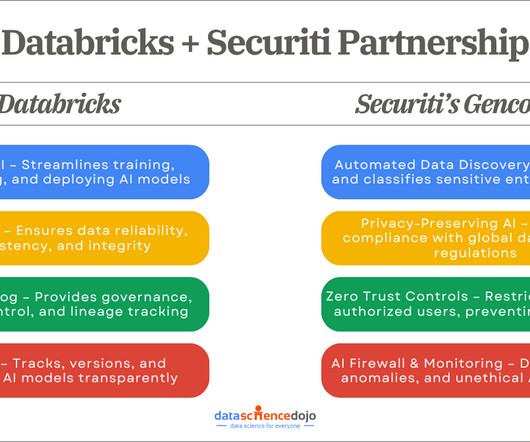
You must ensure continuous governance and security of your AI models and systems to prevent bias, data leaks, or any unauthorized AI interactions. The partnership between Databricks and Gencore AI enables enterprises to develop AI applications with robust security measures, optimized datapipelines, and comprehensive governance.
Simply put, focusing solely on data analysis, coding or modeling will no longer cuts it for most corporate jobs. In this regard, I believe the future of datascience belongs to those: who can connect the dots and deliver results across the entire data lifecycle.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























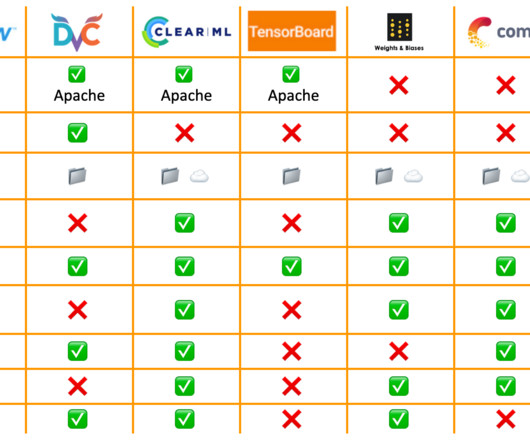










Let's personalize your content