This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data, undoubtedly, is one of the most significant components making up a machinelearning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods.
Data Scientist Data scientists are responsible for designing and implementing datamodels, analyzing and interpreting data, and communicating insights to stakeholders. They require strong programming skills, knowledge of statistical analysis, and expertise in machinelearning.
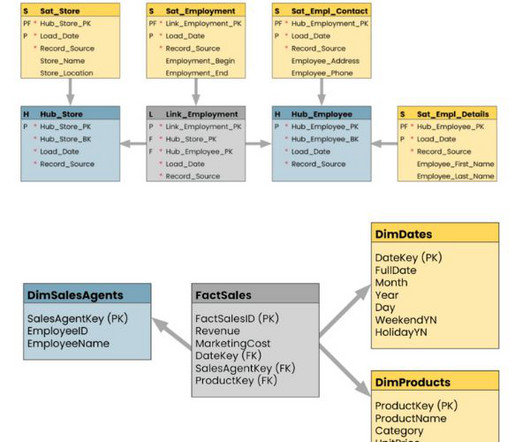
Traditional vs vector databases Datamodels Traditional databases: They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
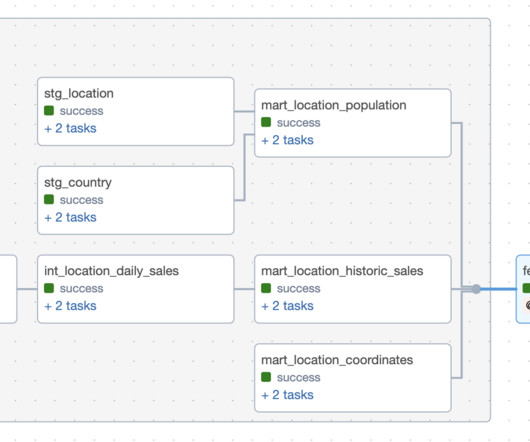
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
These skills include programming languages such as Python and R, statistics and probability, machinelearning, data visualization, and datamodeling. Programming Data scientists need to have a solid foundation in programming languages such as Python, R, and SQL.
Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL. But why is SQL, or Structured Query Language , so important to learn? Finally, SQL’s window function.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any data science and machinelearning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
Data Science is a field that encompasses various disciplines, including statistics, machinelearning, and data analysis techniques to extract valuable insights and knowledge from data. It is divided into three primary areas: data preparation, datamodeling, and data visualization.
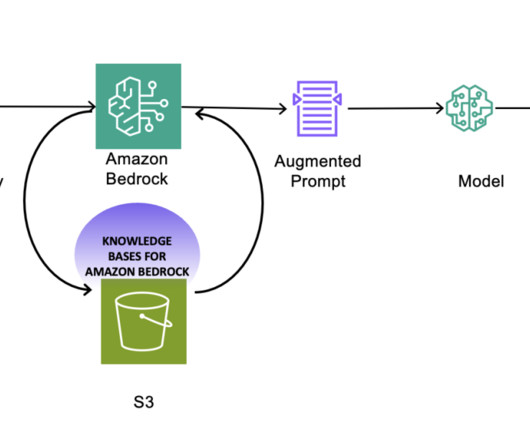
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share best practices on developing Text-to-SQL use cases using Meta Llama 3 models. Meta Llama 3’s capabilities enhance accuracy and efficiency in understanding and generating SQL queries from natural language inputs.
While data science and machinelearning are related, they are very different fields. In a nutshell, data science brings structure to big data while machinelearning focuses on learning from the data itself. What is data science? What is machinelearning?
First, the amount of data available to organizations has grown exponentially in recent years, creating a need for professionals who can make sense of it. Second, advancements in technology, such as big data and machinelearning, have made it easier and more efficient to analyze data.
What do machinelearning engineers do? They design, develop, and deploy the machinelearning algorithms that power everything from self-driving cars to personalized recommendations. What do machinelearning engineers do? Does a machinelearning engineer do coding? They build the future.
It integrates well with other Google Cloud services and supports advanced analytics and machinelearning features. It provides a scalable and fault-tolerant ecosystem for big data processing. Spark offers a rich set of libraries for data processing, machinelearning, graph processing, and stream processing.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house.
Since the field covers such a vast array of services, data scientists can find a ton of great opportunities in their field. Data scientists use algorithms for creating datamodels. These datamodels predict outcomes of new data. Data science is one of the highest-paid jobs of the 21st century.
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL.
AI databases are specialized to store, manage, and retrieve data for artificial intelligence and machinelearning applications ( Image credit ) What is an AI database? These formats play a significant role in how data is processed, analyzed, and used to develop AI models.
The term “feature store” is often used when architecting the ideal MachineLearning platform. Using dbt to transform data into features allows engineers to take advantage of the expressibility of SQL without worrying about data lineage.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. An integrated model factory to develop, deploy, and monitor models in one place using your preferred tools and languages.
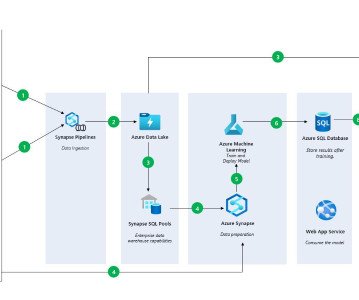
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure MachineLearning Studio.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Tabular data is the data in the typical table — some columns and rows are structured well, like in Excel or SQLdata. It's the most common usage of data forms in many data use cases. With the power of LLM, we would learn how to explore the data and perform datamodeling.
With these changes comes the challenge of understanding how to gather, manage, and make sense of the data collected in various markets. With the introduction and use of machinelearning, AI tech is enabling greater efficiencies with respect to data and the insights embedded in the information.
To create, update, and manage a relational database, we use a relational database management system that most commonly runs on Structured Query Language (SQL). NoSQL databases — NoSQL is a vast category that includes all databases that do not use SQL as their primary data access language.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machinelearningmodels and develop artificial intelligence (AI) applications.
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Role of Data Scientists Data Scientists are the architects of data analysis.
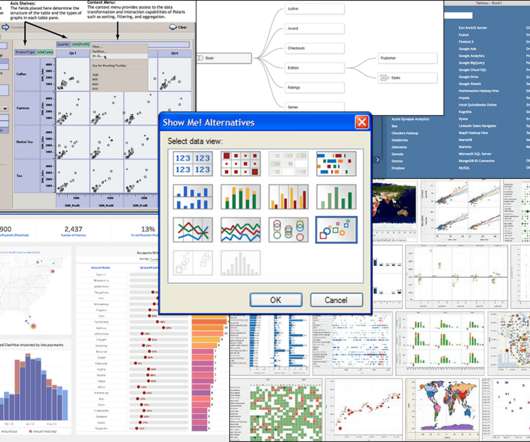
Query allowed customers from a broad range of industries to connect to clean useful data found in SQL and Cube databases. The prototype could connect to multiple data sources at the same time—a precursor to Tableau’s investments in data federation. Relationships in Tableau 2020.2 (May Beginning in Tableau 2020.2,
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machinelearning (ML) from weeks to minutes. Data professionals such as data scientists want to use the power of Apache Spark , Hive , and Presto running on Amazon EMR for fast data preparation; however, the learning curve is steep.
Select the uploaded file and from Actions dropdown and choose the Query with S3 Select option to query the.csv data using SQL if the data was loaded correctly. In this demonstration, let’s assume that you need to remove the data related to a particular customer. He is passionate about cloud and machinelearning.
Summary: Relational Database Management Systems (RDBMS) are the backbone of structured data management, organising information in tables and ensuring data integrity. This article explores RDBMS’s features, advantages, applications across industries, the role of SQL, and emerging trends shaping the future of data management.
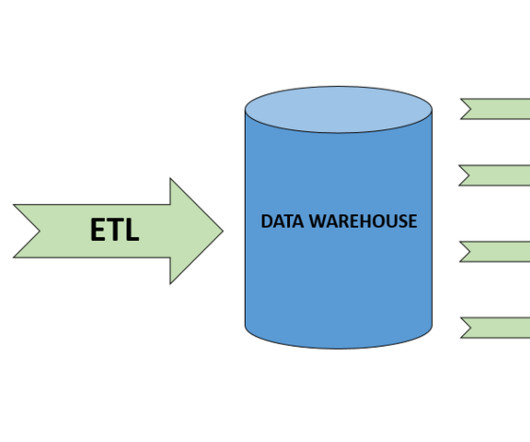
Data flows from the current data platform to the destination. The necessary access is granted so data flows without issue. SQL Server Agent jobs). Either way, it’s important to understand what data is transformed, and how so. Reporting The goal of this exercise is to determine how data is consumed.
Gen AI can automate microservice generation within a low-code platform by interpreting user-defined requirements and generating service interfaces, datamodels, and even testing scripts. Data integration and workflow automation The highest pain points in the application development would be through data integration.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. Its PostgreSQL foundation ensures compatibility with most SQL clients. Strengths : Real-time analytics, built-in machinelearning capabilities, and fast querying with standard SQL.
Key Takeaways Operations Analysts optimise efficiency through data-driven decision-making. Expertise in tools like Power BI, SQL, and Python is crucial. Expertise in programs like Microsoft Excel, SQL , and business intelligence (BI) tools like Power BI or Tableau allows analysts to process and visualise data efficiently.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Top Job-Oriented Courses for Higher Salaries: Business Analytics Certification Program The program has been specifically designed for the aspirants interested in Analytics which includes to expand their skills in Statistics, Predictive Modelling and MachineLearning. Through the Data Science Job Guarantee Program by Pickl.AI
My approach to graph-based Retrieval Augmented Generation The approach is a bit more rooted in traditional methods, I parse the DataModel (an SQL-based relational system) into Nodes and Relationships in a graph database and then provide an endpoint where those relationships can be queried to provide a source of truth.
Lookers strength lies in its ability to connect to a wide variety of data sources. Examples include SQl, DWH, and Cloud based systems (Google Bigquery). With Looker, you can share dashboards and visualizations seamlessly across teams, providing stakeholders with access to real-time data.
For example, a data scientist would be a good fit for a team that is in charge of handling large swaths of data and creating actionable insights from them. In another industry what matters is being able to predict behaviors in the medium and short terms, and this is where a machinelearning engineer might come to play.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content