This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As data science evolves and grows, the demand for skilled datascientists is also rising. A datascientist’s role is to extract insights and knowledge from data and to use this information to inform decisions and drive business growth.
It allows people with excess computing resources to sell them to datascientists in exchange for cryptocurrencies. Datascientists can access remote computing power through sophisticated networks. This feature helps automate many parts of the datapreparation and datamodel development process.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, datamodeling, and data visualization.
LLMOps facilitates the streamlined deployment, continuous monitoring, and ongoing maintenance of large language models. Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals.
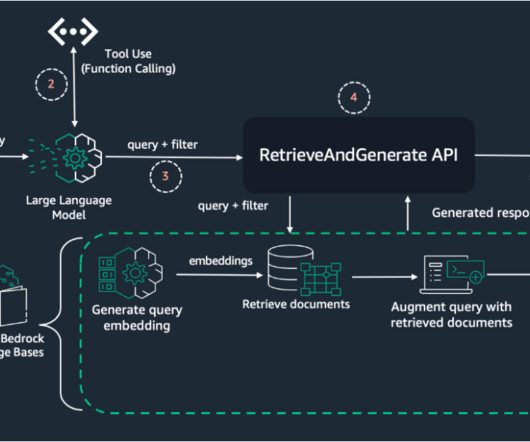
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. In her free time, she likes to go for long runs along the beach.
This required custom integration efforts, along with complex AWS Identity and Access Management (IAM) policy management, further complicating the model governance process. ML development – This phase of the ML lifecycle should be hosted in an isolated environment for model experimentation and building the candidate model.
Learn how DataScientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, data analysis, data cleaning, and data visualization. It facilitates exploratory Data Analysis and provides quick insights.
However, many datascientists and business analysts can’t readily lean on automated regression techniques like logistic regression and linear regression. This stems, largely, from the fact that there are certain data regulations in place when it comes to marketing tech and predictive analytics software.
The blog is based on the webinar Deploying Gen AI in Production with NVIDIA NIM & MLRun with Amit Bleiweiss, Senior DataScientist at NVIDIA, and Yaron Haviv, co-founder and CTO and Guy Lecker, ML Engineering Team Lead at Iguazio (acquired by McKinsey). When developers and datascientists need a gen Al app/tech playground.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly. Saurabh Gupta is a Principal Engineer at Zeta Global.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently. The choice is yours.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Kubeflow documentation. Can you render audio/video?
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
At Tableau, we wanted to understand use cases and common issues from our most advanced datascientists to general data consumers. While not exhaustive, here are additional capabilities to consider as part of your data management and governance solution: Datapreparation. Datamodeling.
At Tableau, we wanted to understand use cases and common issues from our most advanced datascientists to general data consumers. While not exhaustive, here are additional capabilities to consider as part of your data management and governance solution: Datapreparation. Datamodeling.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
New machines are added continuously to the system, so we had to make sure our model can handle prediction on new machines that have never been seen in training. Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Exploratory data analysis (EDA) and modeling.
Data engineers, datascientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. Data Pipeline - Manages and processes various data sources. Application Pipeline - Manages requests and data/model validations. LLMOps is MLOps for LLMs.
In case of professional Data Analysts, who might be engaged in performing experiments on data, standard SQL tools are required. Data Analysts need deeper knowledge on SQL to understand relational databases like Oracle, Microsoft SQL and MySQL. Moreover, SQL is an important tool for conducting DataPreparation and Data Wrangling.
You need to make that model available to the end users, monitor it, and retrain it for better performance if needed. This collaboration of ML and operations teams is what you call MLOps and focuses on streamlining the process of deploying the ML models to production, along with maintaining and monitoring them.
Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. It plays a crucial role in every model’s development process and allows datascientists to focus on the most promising ML techniques.
Model Evaluation and Tuning After building a Machine Learning model, it is crucial to evaluate its performance to ensure it generalises well to new, unseen data. Model evaluation and tuning involve several techniques to assess and optimise model accuracy and reliability.
However, as your model development process becomes more complex and involves numerous experiments and iterations, keeping track of your progress, managing experiments, and collaborating effectively with team members becomes increasingly challenging. First, ML models are becoming increasingly complex and require a lot of data to train.
It requires significant effort in terms of datapreparation, exploration, processing, and experimentation, which involves trying out algorithms and hyperparameters. It is so because these algorithms have proven great results on a benchmark dataset, whereas your business problem and hence your data is different.
The platform typically includes components for the ML ecosystem like data management, feature stores, experiment trackers, a model registry, a testing environment, model serving, and model management. They include: 1 Data (or input) pipeline. 2 Model (or training) pipeline.
The current team is very high functioning (MD + datascientist combos, former ASF board member, Google and Amazon engineers, Stanford LLM researchers, etc.) Experience integrating AI/ML models into production systems (LLMs, transformers, fine-tuning, etc.). Strong system design, datamodeling, and architectural thinking.
Datascientists can analyze detailed results with SageMaker Clarify visualizations in Notebooks, SageMaker Model Cards, and PDF reports. The following figure shows end-to-end LLMOps lifecycle: In LLMOps the main differences compared to MLOps are model selection and model evaluation involving different processes and metrics.
This includes responsible AI, Gartners concept of AI TRiSM (Trust, Risk and Security in AI Models) and Sovereign AI. AI engineering - AI is being democratized for developers and engineers, expanding beyond the limited pool of datascientists. AI Agents and multi-agent systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content