This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts. But those end users werent always clear on which data they should use for which reports, as the datadefinitions were often unclear or conflicting.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
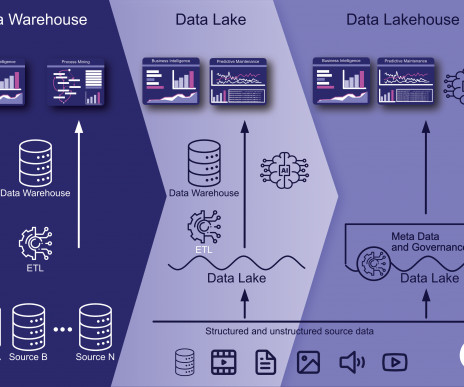
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Disruptive Trend #1: Hadoop.
The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only). Query the vector data store You can query the vector data store using the Vector Search aggregation pipeline. It uses the Vector Search index and performs a semantic search on the vector data store.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. All phases of the data-information lifecycle.
Key Components of Data Engineering Data Ingestion : Gathering data from various sources, such as databases, APIs, files, and streaming platforms, and bringing it into the data infrastructure. Data Processing: Performing computations, aggregations, and other data operations to generate valuable insights from the data.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Common options include: Relational Databases: Structured storage supporting ACID transactions, suitable for structured data.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Big Data wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit Big Data beinahe synonym gesetzt.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content