This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. We can use it to represent facts, figures, and other information that we can use to make decisions. The post DataLake or Data Warehouse- Which is Better?
Published: June 11, 2025 Announcements 5 min read by Ali Ghodsi , Stas Kelvich , Heikki Linnakangas , Nikita Shamgunov , Arsalan Tavakoli-Shiraji , Patrick Wendell , Reynold Xin and Matei Zaharia Share this post Keep up with us Subscribe Summary Operational databases were not designed for today’s AI-driven applications.
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
However, even digital information has to be stored somewhere. While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called datalakes. What Are DataLakes?
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding DataLakes A datalake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
But the Internet and search engines becoming mainstream enabled never-before-seen access to unstructured content and not just structured data. The demand for higher data velocity, faster access and analysis of data as its created and modified without waiting for slow, time-consuming bulk movement, became critical to business agility.
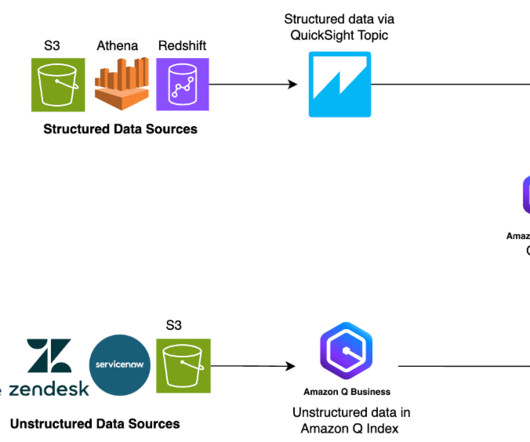
In this post, we show you how Amazon Q Business can help augment your generative AI needs in all the abovementioned use cases and more by answering questions, providing summaries, generating content, and securely completing tasks based on data and information in your enterprise systems. Traditionally, businesses face a challenge.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a datalake, and building an API to extract needed information isn’t working. It’s outdated, it’s clunky, and it was built for a different era. […].
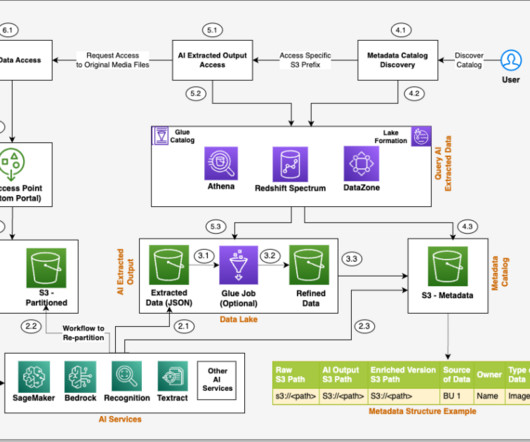
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context.
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Connect your database in QuickSight to create a dataset. For pricing information, see Amazon Q Business pricing.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. In this article, we’ll focus on a datalake vs. data warehouse.
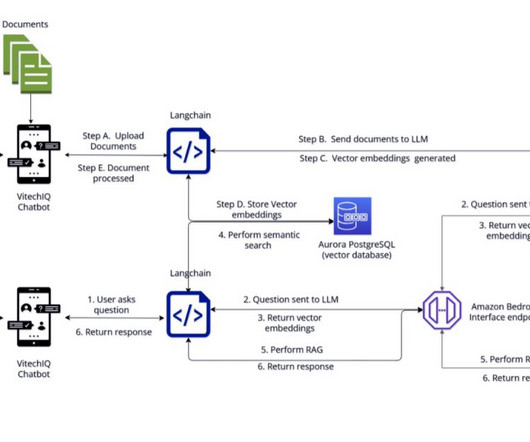
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
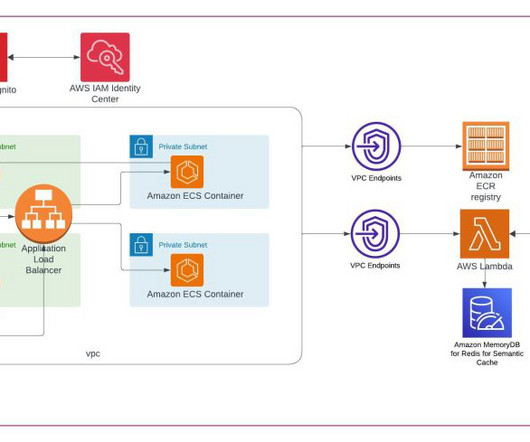
Writing data to an AWS datalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the datalake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
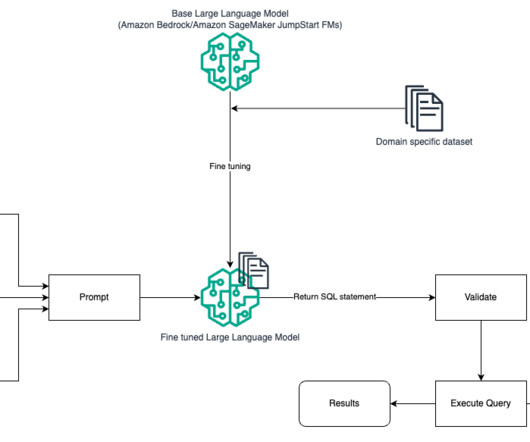
Data is the foundational layer for all generative AI and ML applications. Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. The following diagram illustrates the solution architecture.
Heres a sampling of what some of our more active users had to say about their experience with Field Advisor: I use Field Advisor to review executive briefing documents, summarize meetings and outline actions, as well analyze dense information into key points with prompts. Field Advisor continues to enable me to work smarter, not harder.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
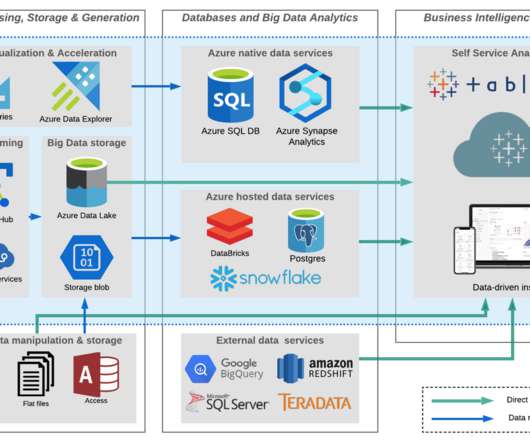
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure DataLake Storage Gen2 connector. As our customers increasingly adopt the cloud, we continue to make investments that ensure they can access their data anywhere. March 30, 2021.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
When defining your tagging strategy, you need to determine the right tags that will gather all the necessary information in your environment. Avoid personally identifiable information (PII) when labeling resources because tags remain unencrypted and visible. This identifies teams or cost centers responsible for those resources.
Data mining has emerged as a vital tool in todays data-driven environment, enabling organizations to extract valuable insights from vast amounts of information. As businesses generate and collect more data than ever before, understanding how to uncover patterns and trends becomes essential for making informed decisions.
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access.
The following is an example of a financial information dataset for exchange-traded funds (ETFs) from Kaggle in a structured tabular format that we used to test our solution. What would the LLM’s response or data analysis be when the user’s questions in industry specific natural language get more complex?
The Crucial Role of Data Engineering in IoT As the IoT ecosystem continues to expand with an influx of connected devices generating massive volumes of data, data engineering becomes a critical component in realizing IoT’s true potential. Data Cleaning and Preprocessing IoT data can be noisy, incomplete, and inconsistent.
Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake. Create a datalake with Lake Formation.
Data auditing and compliance Almost each company face data protection regulations such as GDPR, forcing them to store certain information in order to demonstrate compliance and history of data sources. In this scenario, data versioning can help companies in both internal and external audits process.
One way to mitigate LLMs from giving incorrect information is by using a technique known as Retrieval Augmented Generation (RAG). RAG combines the powers of pre-trained language models with a retrieval-based approach to generate more informed and accurate responses.
Why data warehousing is critical to a company’s success Data warehousing is the secure electronic information storage by a company or organization. Benefits of new data warehousing technology Everything is data, regardless of whether it’s structured, semi-structured, or unstructured.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Hopefully, it was informative and helpful to you. Well, let’s find out. Artificial intelligence (AI).
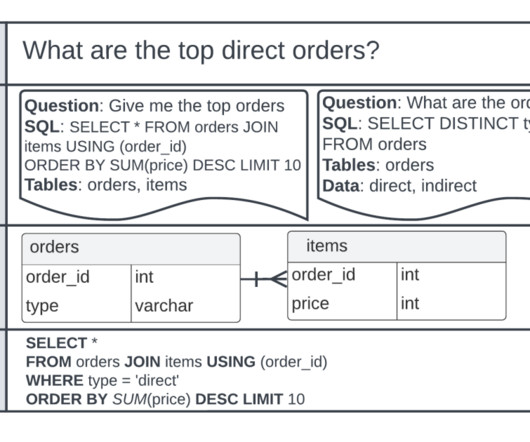
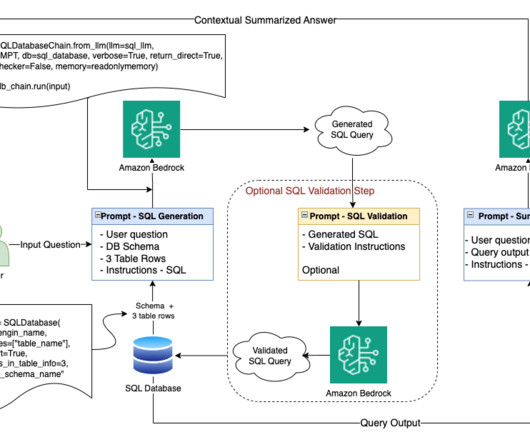
To do this, the text input is transformed into a structured representation, and from this representation, a SQL query that can be used to access a database is created. The primary goal of Text2SQL is to make querying databases more accessible to non-technical users, who can provide their queries in natural language. gymnast_id = t2.
Pipeline, as it sounds, consists of several activities and tools that are used to move data from one system to another using the same method of data processing and storage. Data pipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The problem Making data accessible to users through applications has always been a challenge.
Business analytics is a powerful enabler for organizations seeking to harness the quintessence of information to optimize performance and drive strategic initiatives. It delves beyond mere data collection, engaging in the processes of extracting meaningful insights to inform better business decisions.
Comprehensive data privacy laws in at least four states are going into effect this year, and more than a dozen states have similar legislation in the works. Database management may become increasingly complex as organizations must account for more of these laws.
Variety Variety delineates the different data types involved, encompassing structured data like databases, unstructured data such as text and multimedia content, and semi-structured data found in logs and sensor data. Velocity Velocity describes the speed at which data is generated and processed.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
In such cases, using an FM to parse the data will provide better results. You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs. Many organizations store their data in structured formats within data warehouses and datalakes.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.
To meet the growing demand for efficient and dynamic data retrieval, Q4 aimed to create a chatbot Q&A tool that would provide an intuitive and straightforward method for IROs to access the necessary information they need in a user-friendly format. The generated query is then run against the database to fetch the relevant context.
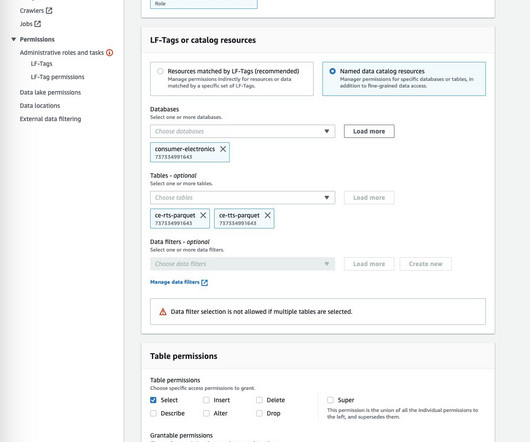
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The sample dataset Upload the dataset to Amazon S3 and crawl the data to create an AWS Glue database and tables.
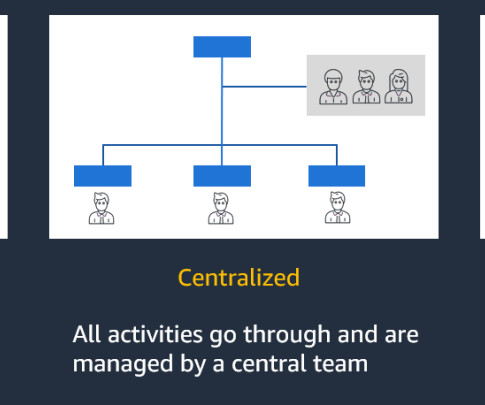
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is data governance. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content