This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This type of data maintains a clear structure, usually in rows and columns, which makes it easy to store and retrieve using database systems. Definition and characteristics of structured data Structured data is typically characterized by its organization within fixed fields in databases.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts. But those end users werent always clear on which data they should use for which reports, as the datadefinitions were often unclear or conflicting.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access.
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
A cloud data warehouse is designed to combine a concept that every organization knows, namely a data warehouse, and optimizes the components of it, for the cloud. What is a DataLake? A DataLake is a location to store raw data that is in any format that an organization may produce or collect.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. The job reads features, generates predictions, and writes them to a database. Building a Machine Learning platform (Lemonade).
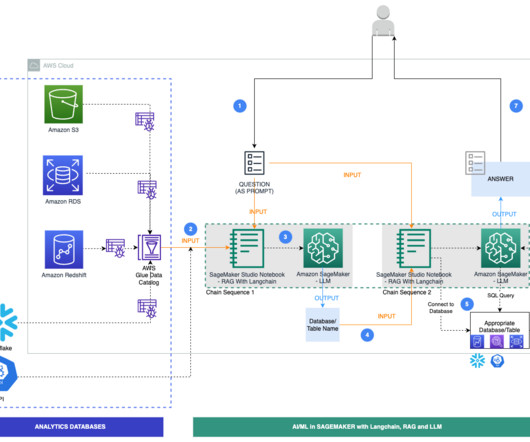
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you want to do the process in a low-code/no-code way, you can follow option C.
Depending on the requirement, it is important to choose between transient and permanent tables, as well as data recovery needs and downtime considerations. Therefore, Snowflake advises monitoring these files and deleting them from the stages once the data has been loaded and the files are no longer necessary to help control storage expenses.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. A data fabric is comprised of a network of data nodes (e.g.,
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) datalake, invoking the processing using AWS Step Functions. The raw data is processed by an LLM using a preconfigured user prompt.
Azure ML supports various approaches to model creation: Automated ML : For beginners or those seeking quick results, Automated ML can generate optimized models based on your dataset and problem definition. Simply prepare your data, define your target variable, and let AutoML explore various algorithms and hyperparameters.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Amazon Simple Storage Service (Amazon S3) object storage acts as a content datalake. TR built processes to securely access data from the content datalake to users’ experimentation workspaces while maintaining required authorization and auditability.
This session provides a gentle introduction to vector databases. You’ll start by demystifying what vector databases are, with clear definitions, simple explanations, and real-world examples of popular vector databases.
You can integrate existing data from AWS datalakes, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) instances with services such as Amazon Bedrock and Amazon Q. Role context – Start each prompt with a clear role definition.
Guided Navigation Guided navigation helps data stewards locate sensitive data. This includes finding the most exposed sensitive data and ensuring it is used properly. There are many locations where sensitive data can reside — from datalakes, databases, and reports, to APIs and queries.
A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle. They all agree that a Datamart is a subject-oriented subset of a data warehouse focusing on a particular business unit, department, subject area, or business functionality.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
The first two use cases are primarily aimed at a technical audience, as the lineage definitions apply to actual physical assets. Data is touched and manipulated by a myriad of solutions, including on-premises and cloud transformation tools, databases and datalake houses.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services.
For example, data science always consumes “historical” data, and there is no guarantee that the semantics of older datasets are the same, even if their names are unchanged. Pushing data to a datalake and assuming it is ready for use is shortsighted. On-premises business intelligence and databases.
Without partitioning, daily data activities will cost your company a fortune and a moment will come where the cost advantage of GCP BigQuery becomes questionable. In prior to creating your first Scheduled Query, I recommend that you confirm with your database administrator that you have the adequate IAM permissions to create one.
Kuba: Integrating things like Google Lens and making a product that essentially, I think a lot of companies definitely try to improve their to-shop experience, and that happens for sure and in fashion. That’s definitely happening, and it seems like a very valid use case with high value, monetary value. Any thoughts?
Now, a single customer might use multiple emails or phone numbers, but matching in this way provides a precise definition that could significantly reduce or even eliminate the risk of accidentally associating the actions of multiple customers with one identity. Store this data in a customer data platform or datalake.
Stephen: Definitely sounds a whole like the typical project management dilemma. When we speak about like NLP problems or classical ML problems with tabular data when the data can be spread in huge databases. Stephen: We definitely love war stories in this podcast. These are all very key and important aspects.
There are definitely compelling economic reasons for us to enter into this realm. So each of them may require some repositories from a datalake house/analytics hub kind of thing for sharing data, to a feature store, to a model hub, to the responsible AI (known sets of things that you need to guard against), to a model registry.
There are definitely compelling economic reasons for us to enter into this realm. So each of them may require some repositories from a datalake house/analytics hub kind of thing for sharing data, to a feature store, to a model hub, to the responsible AI (known sets of things that you need to guard against), to a model registry.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
We are also hiring for other engineering and growth roles - https://supabase.com/careers reply manish_gill 9 hours ago | prev | next [–] ClickHouse | Senior Software Engineer - Cloud Infrastructure / Kubernetes | Remote (US / EU preferred) ClickHouse is a popular, Open-Source OLAP Database. You can find it all at ML6.
Organizational resiliency draws on and extends the definition of resiliency in the AWS Well-Architected Framework to include and prepare for the ability of an organization to recover from disruptions. With Security Lake, you can get a more complete understanding of your security data across your entire organization.
. “ This sounds great in theory, but how does it work in practice with customer data or something like a ‘composable CDP’? Well, implementing transitional modeling does require a shift in how we think about and work with customer data. It often involves specialized databases designed to handle this kind of atomic, temporal data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content