

Data virtualization
Dataconomy
JUNE 13, 2025
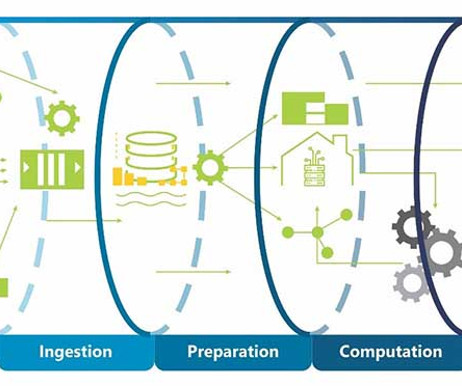
Mechanics of data virtualization Understanding how data virtualization works reveals its benefits in organizations. Middleware role Data virtualization often functions as middleware that bridges various data models and repositories, including cloud data lakes and on-premise warehouses.




























Let's personalize your content