This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
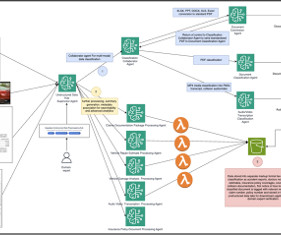
Enterprisesespecially in the insurance industryface increasing challenges in processing vast amounts of unstructured data from diverse formats, including PDFs, spreadsheets, images, videos, and audio files. These might include claims document packages, crash event videos, chat transcripts, or policy documents.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
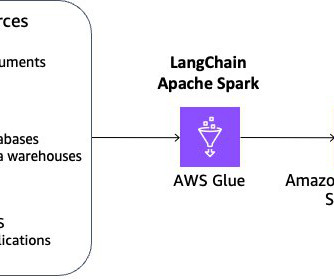
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. The datalake can then refine, enrich, index, and analyze that data. and various countries in Europe.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Robust data processing pipeline A sophisticated data processing pipeline maintains Alfreds knowledge base and promotes high-quality responses. Amazon S3 serves as the central datalake, providing scalable object storage for raw documents with versioning and lifecycle management capabilities.
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again.
DataQuality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
For example, a new data scientist who is curious about which customers are most likely to be repeat buyers, might search for customer data only to discover an article documenting a previous project that answered their exact question. Modern data catalogs also facilitate dataquality checks.
For any data user in an enterprise today, data profiling is a key tool for resolving dataquality issues and building new data solutions. In this blog, we’ll cover the definition of data profiling, top use cases, and share important techniques and best practices for data profiling today.
Figure 1 illustrates the typical metadata subjects contained in a data catalog. Figure 1 – Data Catalog Metadata Subjects. Datasets are the files and tables that data workers need to find and access. They may reside in a datalake, warehouse, master data repository, or any other shared data resource.
Precisely conducted a study that found that within enterprises, data scientists spend 80% of their time cleaning, integrating and preparing data , dealing with many formats, including documents, images, and videos. Overall placing emphasis on establishing a trusted and integrated data platform for AI.
As data types and applications evolve, you might need specialized NoSQL databases to handle diverse data structures and specific application requirements. Enterprises might also have petabytes, if not exabytes, of valuable proprietary data stored in their mainframe that needs to be unlocked for new insights and ML/AI models.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. The right tool can significantly enhance efficiency, scalability, and dataquality.
Additional considerations Though the potential of this approach is significant, there are several challenges to consider: Dataquality High-quality, diverse input data is key to effective model performance. He is focused on big data, datalakes, streaming and batch analytics services, and generative AI technologies.
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
To optimize data analytics and AI workloads, organizations need a data store built on an open data lakehouse architecture. This type of architecture combines the performance and usability of a data warehouse with the flexibility and scalability of a datalake.
Homogeneity, Completeness, and V-measure - Measures different aspects of cluster quality, such as the extent to which each cluster contains only samples from a single class (homogeneity), the extent to which all samples from the same class are assigned to the same cluster (completeness), and their harmonic mean (V-measure).
How do you get executives to understand the value of data governance? First, document your successes of good data, and how it happened. Share stories of data in good times and in bad (pictures help!). Some data seems more analytical, while other is operational (external facing). Seeing is believing!
So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns. Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
External Data Sources: These can be market research data, social media feeds, or third-party databases that provide additional insights. Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions.
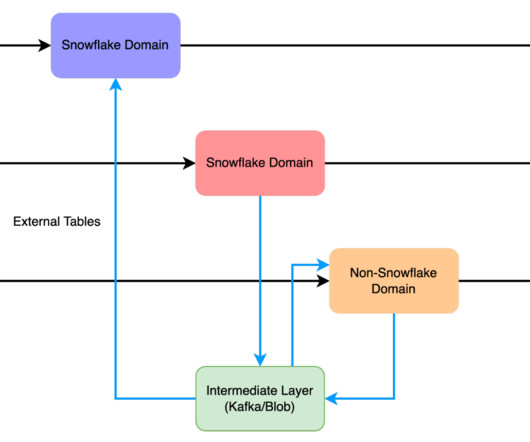
Traditional data management approaches often involve centralizing data in a data warehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks. What are the Advantages and Disadvantages of Data Mesh?
Behavioral intelligence, embedded in the catalog, learns from user behavior to enforce best practices through features like dataquality flags, which help folks stay compliant as they use data. Active Governance – Active data governance creates usage-based assignments, which prioritize and delegate curation duties.
This includes operations like data validation, data cleansing, data aggregation, and data normalization. The goal is to ensure that the data is consistent and ready for analysis. Loading : Storing the transformed data in a target system like a data warehouse, datalake, or even a database.
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning. ArangoDB ArangoDB is a company that provides a database platform for graph and documentdata.
Having been in business for over 50 years, ARC had accumulated a massive amount of data that was stored in siloed, on-premises servers across its 7 business domains. Using Alation, ARC automated the data curation and cataloging process. “So
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. And when the platform automates the entire process, it’ll likely produce and deploy a bad-quality model.
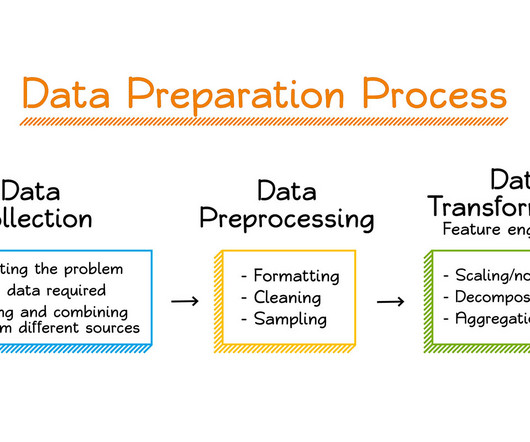
Only once you form a clear definition and understanding of the business problem , goals, and the necessity of machine learning should you move forward to the next stage of data preparation. In large ML organizations, there is typically a dedicated team for all the above aspects of data preparation.
DataQuality Next, dive into the details of your data. This means bringing together one or more of: Behavioral data like website visits, purchases, engagement with emails, and ads. Store this data in a customer data platform or datalake. What needs are they addressing?
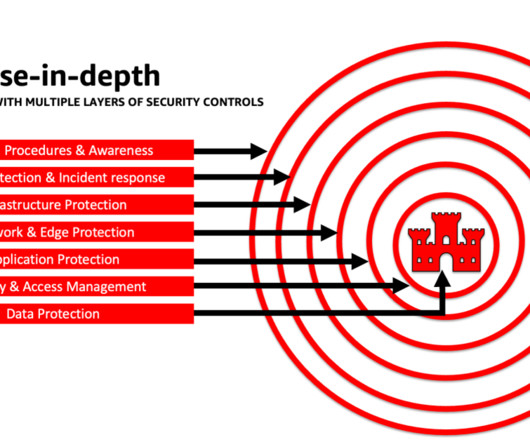
Accelerate your security and AI/ML learning with best practices guidance, training, and certification AWS also curates recommendations from Best Practices for Security, Identity, & Compliance and AWS Security Documentation to help you identify ways to secure your training, development, testing, and operational environments.
The pipelines are interoperable to build a working system: Data (input) pipeline (data acquisition and feature management steps) This pipeline transports raw data from one location to another. Model/training pipeline This pipeline trains one or more models on the training data with preset hyperparameters.
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. One model can perform completely different tasks such as answering questions, summarizing documents, translating languages, and completing sentences. Data must be preprocessed to enable semantic search during inference.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content