This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The data mining process The data mining process is structured into four primary stages: data gathering, datapreparation, data mining, and data analysis and interpretation. Each stage is crucial for deriving meaningful insights from data.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. million per year.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently. For them, the end-to-end MLOps lifecycle and infrastructure is necessary.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. Therefore, BMW established a centralized ML/deeplearning infrastructure on premises several years ago and continuously upgraded it.
Here’s a breakdown of ten top sessions from this year’s conference that data professionals should consider. Topological DeepLearning Made Easy with TopoX with Dr. Mustafa Hajij Slides In these AI slides, Dr. Mustafa Hajij introduced TopoX, a comprehensive Python suite for topological deeplearning.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Monitor the performance of machine learning models.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you want to do the process in a low-code/no-code way, you can follow option C.
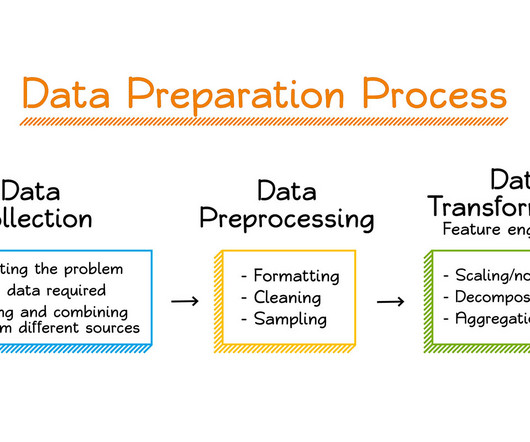
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering.
Mai-Lan Tomsen Bukovec, Vice President, Technology | AIM250-INT | Putting your data to work with generative AI Thursday November 30 | 12:30 PM – 1:30 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B How can you turn your datalake into a business advantage with generative AI? Reserve your seat now!
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content