

Here’s Why Automation For Data Lakes Could Be Important
Smart Data Collective
APRIL 2, 2019
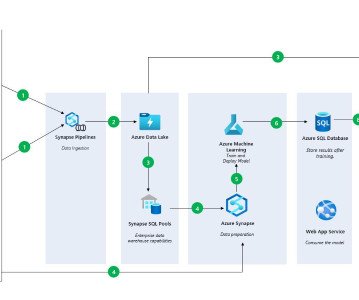
Data Lakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that data lakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.






























Let's personalize your content