This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following points illustrates some of the main reasons why data versioning is crucial to the success of any data science and machinelearning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Additionally, consider exploring other AWS services and tools that can complement and enhance your AI-driven applications, such as Amazon SageMaker for machinelearningmodel training and deployment, or Amazon Lex for building conversational interfaces. He is passionate about cloud and machinelearning.
It integrates well with other Google Cloud services and supports advanced analytics and machinelearning features. It provides a scalable and fault-tolerant ecosystem for big data processing. Spark offers a rich set of libraries for data processing, machinelearning, graph processing, and stream processing.
When it was no longer a hard requirement that a physical datamodel be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Customers of every size and industry are innovating on AWS by infusing machinelearning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries. This framework considers multiple personas and services to govern the ML lifecycle at scale.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
For the preceding techniques, the foundation should provide scalable infrastructure for data storage and training, a mechanism to orchestrate tuning and training pipelines, a model registry to centrally register and govern the model, and infrastructure to host the model.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machinelearning (ML) from weeks to minutes. SageMaker Data Wrangler supports fine-grained data access control with Lake Formation and Amazon Athena connections.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. An integrated model factory to develop, deploy, and monitor models in one place using your preferred tools and languages.
Article on Azure ML by Bethany Jepchumba and Josh Ndemenge of Microsoft In this article, I will cover how you can train a model using Notebooks in Azure MachineLearning Studio. At the end of this article, you will learn how to use Pytorch pretrained DenseNet 201 model to classify different animals into 48 distinct categories.
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure MachineLearning Studio.
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging.
In order to improve our equipment reliability, we partnered with the Amazon MachineLearning Solutions Lab to develop a custom machinelearning (ML) model capable of predicting equipment issues prior to failure. Dan Volk is a Data Scientist at the AWS Generative AI Innovation Center.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machinelearningmodels and develop artificial intelligence (AI) applications.
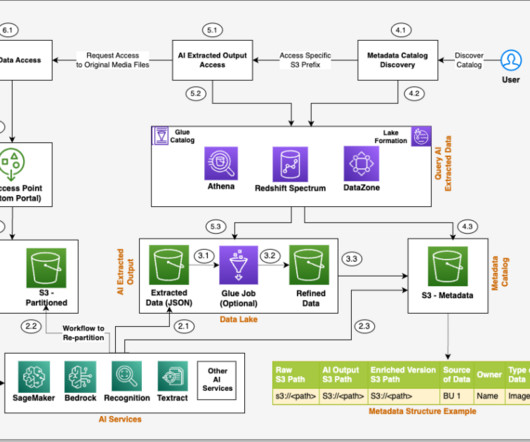
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
Each month, ODSC has a few insightful webinars that touch on a range of issues that are important in the data science world, from use cases of machinelearningmodels, to new techniques/frameworks, and more. This is due to how datalakes can become too large and complex. Watch on-demand here.
He has been helping the customers over the last 20 years in building the enterprise data strategies, advising customers on Generative AI, cloud implementations, migrations, reference architecture creation, datamodeling best practices, datalake/warehouses architectures.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificial intelligence and machinelearning to unify and securely manage disparate data sources without migrating them to a centralized location.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificial intelligence and machinelearning to unify and securely manage disparate data sources without migrating them to a centralized location.
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. With predictive maintenance, L&W can get advanced warning of machine breakdowns and proactively dispatch a service team to inspect the issue.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. Integrating seamlessly with other Google Cloud services, BigQuery is a powerful solution for organizations seeking efficient and cost-effective large-scale data analysis.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Much has been written about struggles of deploying machinelearning projects to production. As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. However, the concept is quite abstract. Compute.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides data science and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic data science concepts to advanced machinelearning techniques.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML). It can be used with both on-premise and multi-cloud environments.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machinelearning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
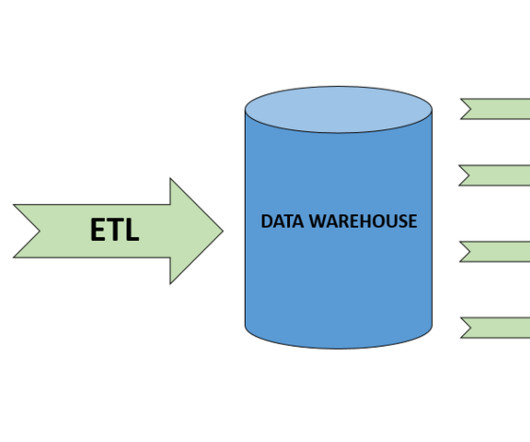
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a data warehouse or datalake. DataLakes: These store raw, unprocessed data in its original format.
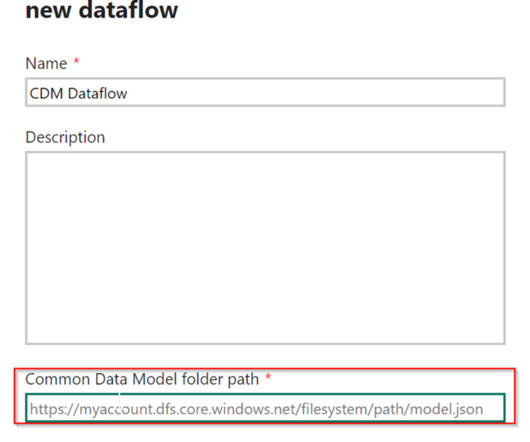
Attach a Common DataModel Folder (preview) When you create a Dataflow from a CDM folder, you can establish a connection to a table authored in the Common DataModel (CDM) format by another application. Dataflows provide centralized data and reduce the load on data sources.
Big data analytics, IoT, AI, and machinelearning are revolutionizing the way businesses create value and competitive advantage. The cloud is especially well-suited to large-scale storage and big data analytics, due in part to its capacity to handle intensive computing requirements at scale.
Sources The sources involved could influence or determine the options available for the data ingestion tool(s). These could include other databases, datalakes, SaaS applications (e.g. Data flows from the current data platform to the destination. Learn more about how a datamodel is chosen!
These tools use machinelearningmodels trained on vast amounts of code to assist developers in writing cleaner, more efficient code. Tools like Testim and Applitools leverage machinelearning to improve both unit testing and UI testing. How you might ask? What should you be looking for?
Just as you need data about finances for effective financial management, you need data about data (metadata) for effective data management. You can’t manage data without metadata. Figure 1 shows a logical datamodel that represents typical metadata content of a data catalog.
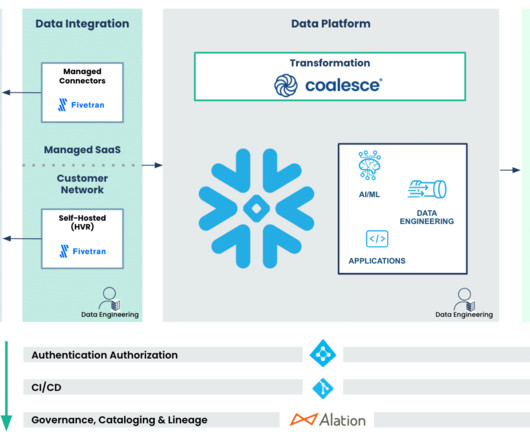
Built for integration, scalability, governance, and industry-leading security, Snowflake optimizes how you can leverage your organization’s data, providing the following benefits: Built to Be a Source of Truth Snowflake is built to simplify data integration wherever it lives and whatever form it takes.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machinelearning. What is Unstructured Data?
Reinforcement Learning with Human Feedback Luis Serrano, PhD | Author of Grokking MachineLearning and Creator of Serrano Academy In this session, you’ll explore the widely used LLM fine-tuning method of Reinforcement Learning with Human Feedback (RLHF).
Self-Service Analytics User-friendly interfaces and self-service analytics tools empower business users to explore data independently without relying on IT departments. This might involve data validation rules, data cleansing procedures, and ongoing monitoring to maintain data integrity.
Across the country, data scientists have an unemployment rate of 2% and command an average salary of nearly $100,000. As they attempt to put machinelearningmodels into production, data science teams encounter many of the same hurdles that plagued data analytics teams in years past: Finding trusted, valuable data is time-consuming.
Understand the fundamentals of data engineering: To become an Azure Data Engineer, you must first understand the concepts and principles of data engineering. Knowledge of datamodeling, warehousing, integration, pipelines, and transformation is required. Data Warehousing concepts and knowledge should be strong.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. MachineLearning Integration Opportunities Organizations harness machinelearning (ML) algorithms to make forecasts on the data.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage.
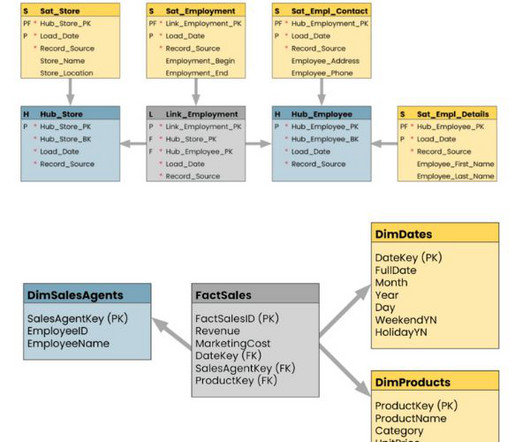
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
They run scripts manually to preprocess their training data, rerun the deployment scripts, manually tune their models, and spend their working hours keeping previously developed models up to date. Building end-to-end machinelearning pipelines lets ML engineers build once, rerun, and reuse many times.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



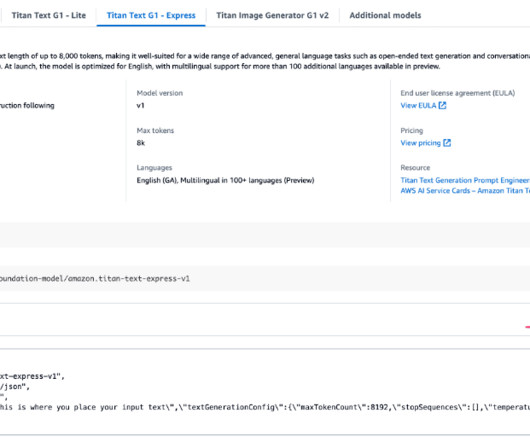







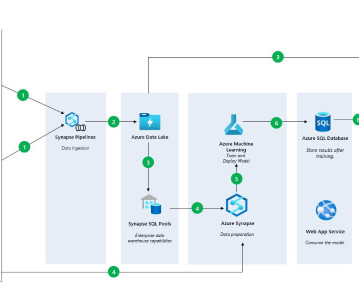

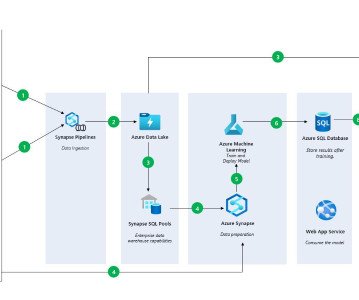

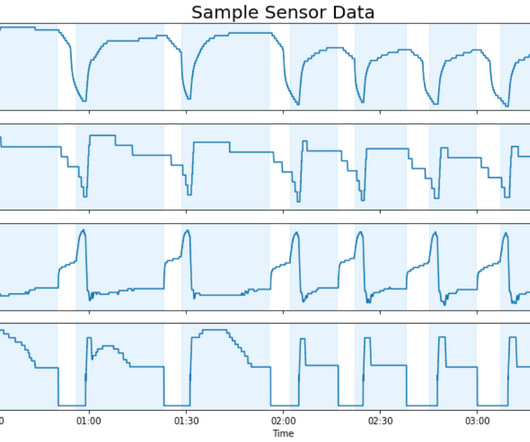


























Let's personalize your content