This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and data engineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
It enables data engineers to define datamodels, manage dependencies, and perform automated testing, making it easier to ensure data quality and consistency. Fivetran: Fivetran is a cloud-based data integration platform that simplifies the process of loading data from various sources into a data warehouse or datalake.
Each month, ODSC has a few insightful webinars that touch on a range of issues that are important in the datascience world, from use cases of machine learning models, to new techniques/frameworks, and more. This is due to how datalakes can become too large and complex. Watch on-demand here. Watch on-demand here.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any datascience and machine learning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
To get the data, you will need to follow the instructions in the article: Create a Data Solution on Azure Synapse Analytics with Snapshot Serengeti — Part 1 — Microsoft Community Hub, where you will load data into Azure DataLake via Azure Synapse. Lastly, upload the data from Azure Subscription.
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
Google Cloud Vertex AI Google Cloud Vertex AI provides a unified environment for both automated model development with AutoML and custom model training using popular frameworks. Qwak Qwak is a fully-managed, accessible, and reliable ML platform to develop and deploy models and monitor the entire machine learning pipeline.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? Adapted from the book Effective DataScience Infrastructure. Data is at the core of any ML project, so data infrastructure is a foundational concern.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. No-code/low-code experience using a diagram view in the data preparation layer similar to Dataflows.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
As they attempt to put machine learning models into production, datascience teams encounter many of the same hurdles that plagued data analytics teams in years past: Finding trusted, valuable data is time-consuming. Obstacles, such as user roles, permissions, and approval request prevent speedy data access.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides datascience and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic datascience concepts to advanced machine learning techniques.
Introduction to Containers for DataScience/Data Engineering Michael A Fudge | Professor of Practice, MSIS Program Director | Syracuse University’s iSchool In this hands-on session, you’ll learn how to leverage the benefits of containers for DS and data engineering workflows.
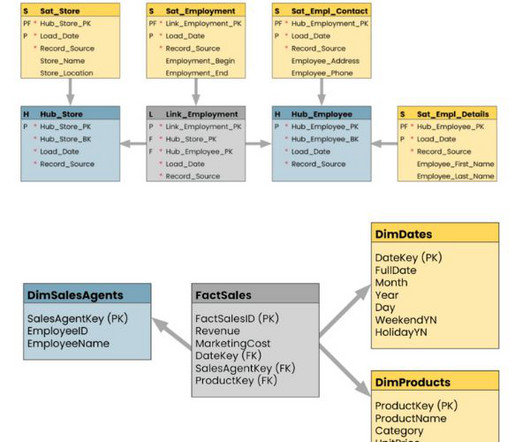
Just as you need data about finances for effective financial management, you need data about data (metadata) for effective data management. You can’t manage data without metadata. But data catalogs do much more. Figure 1 shows a logical datamodel that represents typical metadata content of a data catalog.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
The portal combines these predictive alerts with other insights we derive from our AWS-based datalake in order to give our dealers more clarity into equipment health across their entire client base. Dan Volk is a Data Scientist at the AWS Generative AI Innovation Center.
Sources The sources involved could influence or determine the options available for the data ingestion tool(s). These could include other databases, datalakes, SaaS applications (e.g. Data flows from the current data platform to the destination. Learn more about how a datamodel is chosen!
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
Data cleaning, normalization, and reformatting to match the target schema is used. · Data Loading It is the final step where transformed data is loaded into a target system, such as a data warehouse or a datalake. It ensures that the integrated data is available for analysis and reporting.
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. About the authors Aruna Abeyakoon is the Senior Director of DataScience & Analytics at Light & Wonder Land-based Gaming Division.
This might involve data validation rules, data cleansing procedures, and ongoing monitoring to maintain data integrity. Optimize DataModelling The way data is structured within the warehouse significantly impacts its usability and efficiency.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for data scientists.
What frameworks and operating models have you seen work well? The firms that get data governance and management “right” bring people together and leverage a set of capabilities: (1) Agile; (2) Six sigma; (3) datascience; and (4) project management tools. Establishing a solid vision and mission is key.
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages. They include: 1 Data (or input) pipeline.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








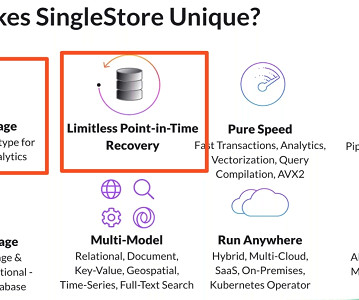

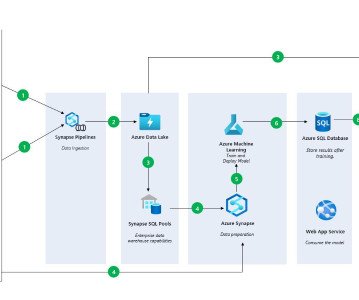
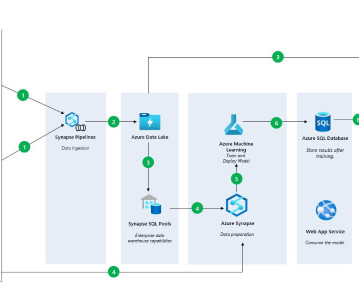



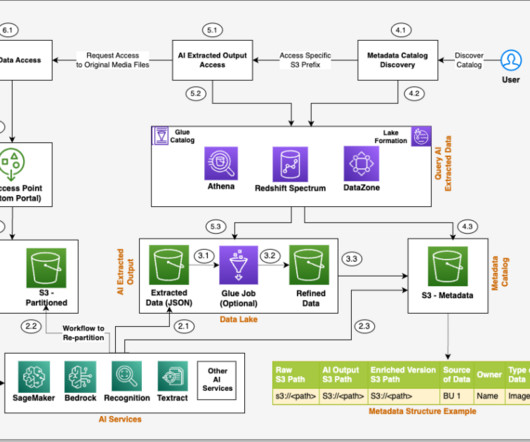























Let's personalize your content