This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
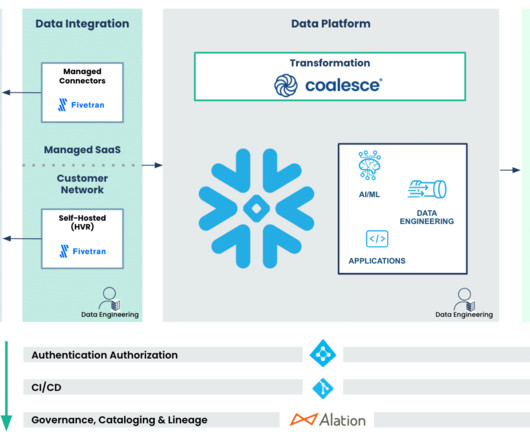
M aintaining the security and governance of data within a datawarehouse is of utmost importance. Data Security: A Multi-layered Approach In data warehousing, data security is not a single barrier but a well-constructed series of layers, each contributing to protecting valuable information.
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex. Lambda enables serverless, event-driven data processing tasks, allowing for real-time transformations and calculations as data arrives.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
The Precisely team recently had the privilege of hosting a luncheon at the Gartner Data & Analytics Summit in London. It was an engaging gathering of industry leaders from various sectors, who exchanged valuable insights into crucial aspects of datagovernance, strategy, and innovation.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them.
This can lead to better datagovernance practices and, ultimately, more accurate insights. The relationship between data democratization and datagovernance While data democratization is an important goal, it is also important to ensure that proper datagovernance practices are in place to ensure that data is managed appropriately.
The goal of digital transformation remains the same as ever – to become more data-driven. We have learned how to gain a competitive advantage by capturing business events in data. Events are data snap-shots of complex activity sourced from the web, customer systems, ERP transactions, social media, […].
Thus, DB2 PureScale on AWS equips this insurance company to innovate and make data-driven decisions rapidly, maintaining a competitive edge in a saturated market. The platform provides an intelligent, self-service data ecosystem that enhances datagovernance, quality and usability.
A part of that journey often involves moving fragmented on-premises data to a cloud datawarehouse. You clearly shouldn’t move everything from your on-premises datawarehouses. Otherwise, you can end up with a data swamp. 2: Biz Problem – Making Data Ready for Business Analysis.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud datawarehouse or data lake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance. Best Practice 5.
Key Takeaways Data Engineering is vital for transforming raw data into actionable insights. Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering?
This can lead to better datagovernance practices and, ultimately, more accurate insights. The relationship between data democratization and datagovernance While data democratization is an important goal, it is also important to ensure that proper datagovernance practices are in place to ensure that data is managed appropriately.
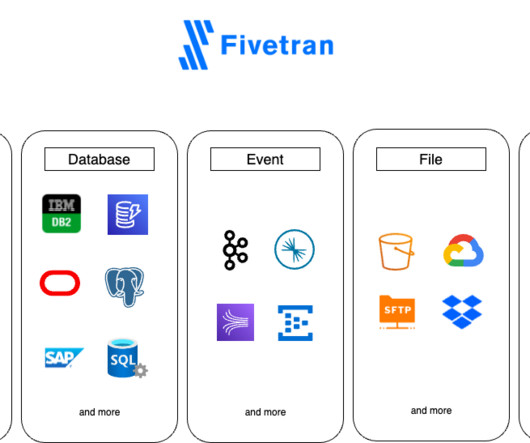
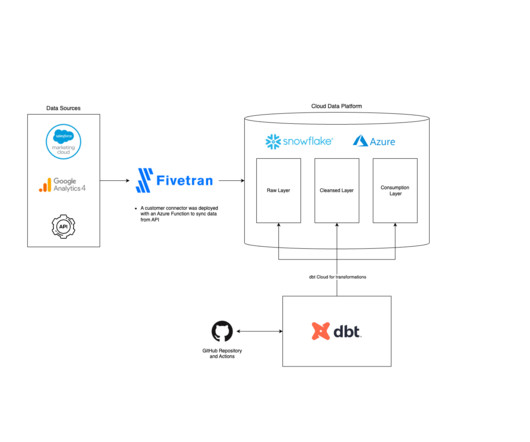
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. The phData team achieved a major milestone by successfully setting up a secure end-to-end data pipeline for a substantial healthcare enterprise.
In that sense, data modernization is synonymous with cloud migration. Modern data architectures, like cloud datawarehouses and cloud data lakes , empower more people to leverage analytics for insights more efficiently. What Is the Role of the Cloud in Data Modernization? Efficient Data Processing.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
For years, marketing teams across industries have turned to implementing traditional Customer Data Platforms (CDPs) as separate systems purpose-built to unlock growth with first-party data. Event Tracking : Capturing behavioral events such as page views, add-to-cart, signup, purchase, subscription, etc.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
These tables are called “factless fact tables” or “junction tables” They are used for modelling many-to-many relationships or for capturing timestamps of events. Ensuring Data Consistency Maintaining data consistency across multiple fact tables can be challenging, especially when dealing with conformed dimensions.
It asks much larger questions, which flesh out an organization’s relationship with data: Why do we have data? Why keep data at all? Answering these questions can improve operational efficiencies and inform a number of data intelligence use cases, which include datagovernance, self-service analytics, and more.
Wide support for enterprise-grade sources and targets Large organizations with complex IT landscapes must have the capability to easily connect to a wide variety of data sources. Whether it’s a cloud datawarehouse or a mainframe, look for vendors who have a wide range of capabilities that can adapt to your changing needs.
This was an eventful year in the world of data and analytics. billion merger of Cloudera and Hortonworks, the widely scrutinized GDPR (General Data Protection Regulation), or the Cambridge Analytica scandal that rocked Facebook. Amid the headline grabbing news, 2018 will also be remembered as the year of the data catalog.
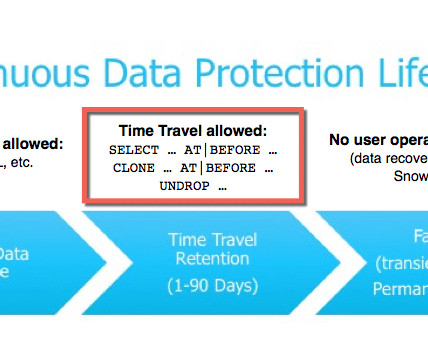
Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 data lake, Snowflake cloud datawarehouse and Tableau (and how it can be fixed). Time is money,” said Leonard Kwok, Senior Data Analyst, ARC.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of data pipelines. Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures.
Fivetran includes features like data movement, transformations, robust security, and compatibility with third-party tools like DBT, Airflow, Atlan, and more. Its seamless integration with popular cloud datawarehouses like Snowflake can provide the scalability needed as your business grows.
Overcoming the challenges of data catalog adoption takes more than patience and persistence. You’ll need a plan that recognizes adoption as a process that unfolds over time—not an event that happens at a point in time. People – Which data stakeholders will you bring on board at what times? How will data curation be funded?
Data Warehousing To store a large volume of data, every company needs to switch to DataWarehouse. It can be cloud-based or deploy a physical infrastructure catering to data warehousing. The latter is, however, costly, but cloud-based data storage is cheaper, more effective and more efficient.
Data Warehousing Solutions Tools like Amazon Redshift, Google BigQuery, and Snowflake enable organisations to store and analyse large volumes of data efficiently. Students should learn about the architecture of datawarehouses and how they differ from traditional databases.
They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. You can also get data science training on-demand wherever you are with our Ai+ Training platform.
Difficulty in moving non-SAP data into SAP for analytics which encourages data silos and shadow IT practices as business users search for ways to extract the data (which has datagovernance implications).
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. DataGovernanceDatagovernance is the foundation of any data quality framework. It primarily caters to large organizations with complex data environments.
The Snowflake Data Cloud is a cloud-based datawarehouse that is becoming increasingly popular among businesses of all sizes. Establish datagovernance guidelines. Define clear datagovernance guidelines to ensure data consistency, integrity, and security across multiple accounts.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. But what does this mean from a practitioner perspective? Happy to chat.
It accurately recognizes diverse data types and supports various table structures, excluding certain data types like GEOGRAPHY and BINARY. The process computes costs based on data volume. It enhances datagovernance by introducing a tagging mechanism.
Data Quality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules. This results in poor credibility and data consistency after some time, leading businesses to mistrust the data pipelines and processes. Contact phData Today!
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The existing Data Catalog becomes the Default catalog (identified by the AWS account number) and is readily available in SageMaker Lakehouse.
Datagovernance: Ensure that the data used to train and test the model, as well as any new data used for prediction, is properly governed. For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, datagovernance becomes crucial.
And celebrating the ability for Machine Learning Data Catalogs to support data culture in every enterprise. Join us at one of our upcoming events and share your story of human-machine collaboration to create data culture. Follow us at #MLDC as we tour the world. – John F.
Der andere Teil des Process Minings ist jedoch noch viel wesentlicher, denn es handelt sich dabei um das Fundament der Analyse: Die Datenmodellierung des Event Logs. Jedes Process Mining Tool benötigt pro Use Case mindestens ein Event Log. Idealerweise werden nur fertige Event-Logs bzw. Celonis Process Mining) übertragen.
Dabei darf gerne in Erinnerung gerufen werden, dass Process Mining im Kern eine Graphenanalyse ist, die ein Event Log in Graphen umwandelt, Aktivitäten (Events) stellen dabei die Knoten und die Prozesszeiten die Kanten dar, zumindest ist das grundsätzlich so. Es handelt sich dabei also um eine Analysemethodik und nicht um ein Tool.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
Practitioners and hands-on data users were thrilled to be there, and many connected as they shared their progress on their own data stack journeys. People were familiar with the value of a data catalog (and the growing need for datagovernance ), though many admitted to being somewhat behind on their journeys.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content