This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
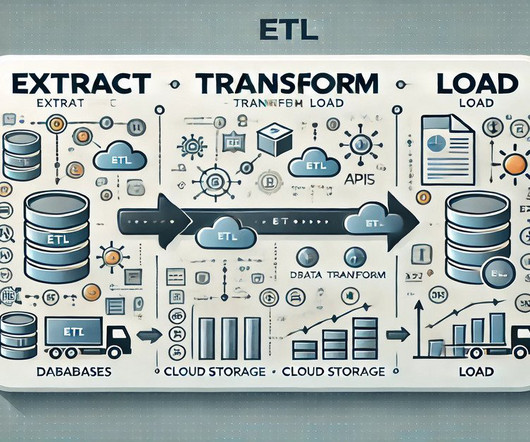
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and data engineering. It supports a holistic data model, allowing for rapid prototyping of various models.
These sessions will provide insights into the latest advancements in generative AI, datagovernance, AI workloads, and more. Throughout the week, AWS leaders and joint customers will lead breakout sessions, lightning talks, and panels showcasing real use cases across industries.
Once authenticated, authorization ensures that the individual is allowed access only to the areas they are authorized to enter. DataGovernance: Setting the Rules D ata governance takes on the role of a regulatory framework, guiding the responsible management, utilization, and protection of your organization’s most valuable asset—data.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It allows data engineers to define and manage complex workflows as directed acyclic graphs (DAGs).
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer. Identify your existing datascience strengths. Stay on top of data engineering trends.
IBM’s Next Generation DataStage is an ETL tool to build data pipelines and automate the effort in data cleansing, integration and preparation. As a part of data pipeline, Address Verification Interface (AVI) can remediate bad address data.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Technologies: Hadoop, Spark, etc. Read more to know.
In my first business intelligence endeavors, there were data normalization issues; in my DataGovernance period, Data Quality and proactive Metadata Management were the critical points. The post The Declarative Approach in a Data Playground appeared first on DATAVERSITY. It is something so simple and so powerful.
Understand what insights you need to gain from your data to drive business growth and strategy. Best practices in cloud analytics are essential to maintain data quality, security, and compliance ( Image credit ) Datagovernance: Establish robust datagovernance practices to ensure data quality, security, and compliance.
Data Warehouses and Relational Databases It is essential to distinguish data lakes from data warehouses and relational databases, as each serves different purposes and has distinct characteristics. Schema Enforcement: Data warehouses use a “schema-on-write” approach. You can connect with her on Linkedin.
In particular, its progress depends on the availability of related technologies that make the handling of huge volumes of data possible. These technologies include the following: Datagovernance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security.
By 2020, over 40 percent of all datascience tasks will be automated. GDPR helped to spur the demand for prioritized datagovernance , and frankly, it happened so fast it left many companies scrambling to comply — even still some are fumbling with the idea. Machine Learning Experience is a Must. The Rise of Regulation.
Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
All of this data might be overwhelming for engineers who struggle to pull in data sets quickly enough. Older ETL technology, which might be code-heavy and slow down your process even more, isn’t helpful. Other industries fear automation, but data engineers are their friends in this instance.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT.
Key Takeaways Data Engineering is vital for transforming raw data into actionable insights. Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering?
Creating data pipelines and workflows Data engineers create data pipelines and workflows that enable data to be collected, processed, and analyzed efficiently. By creating efficient data pipelines and workflows, data engineers enable organizations to make data-driven decisions quickly and accurately.
What Is a Data Warehouse? On the other hand, a Data Warehouse is a structured storage system designed for efficient querying and analysis. It involves the extraction, transformation, and loading (ETL) process to organize data for business intelligence purposes. It often serves as a source for Data Warehouses.
Regular Data Audits Conduct regular data audits to identify issues and discrepancies. This proactive approach allows you to detect and address problems before they compromise data quality. DataGovernance Framework Implement a robust datagovernance framework. How Do You Fix Poor Data Quality?
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is datagovernance.
Support for Advanced Analytics : Transformed data is ready for use in Advanced Analytics, Machine Learning, and Business Intelligence applications, driving better decision-making. Compliance and Governance : Many tools have built-in features that ensure data adheres to regulatory requirements, maintaining datagovernance across organisations.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
Cost reduction by minimizing data redundancy, improving data storage efficiency, and reducing the risk of errors and data-related issues. DataGovernance and Security By defining data models, organizations can establish policies, access controls, and security measures to protect sensitive data.
Image generated with Midjourney In today’s fast-paced world of datascience, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
We specialize in multiple functions, which include but are not limited to, datagovernance , dashboarding, data & analytics engineering, and datascience. At Alation, we focus most of our time on connecting data sources and building useful data transformations to provide reporting for different teams.
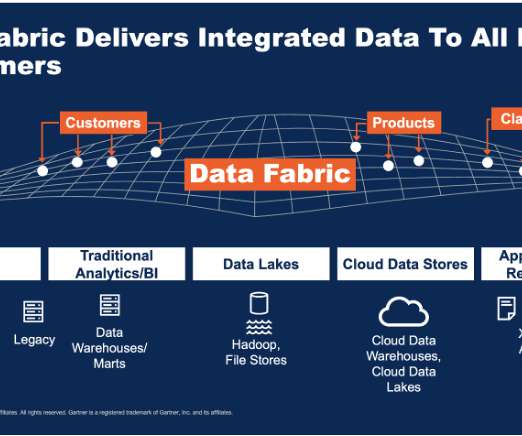
A unified data fabric also enhances data security by enabling centralised governance and compliance management across all platforms. Automated Data Integration and ETL Tools The rise of no-code and low-code tools is transforming data integration and Extract, Transform, and Load (ETL) processes.
To handle sparse data effectively, consider using junk dimensions to group unrelated attributes or creating factless fact tables that capture events without associated measures. Ensuring Data Consistency Maintaining data consistency across multiple fact tables can be challenging, especially when dealing with conformed dimensions.
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. However, merely knowing what it consists of isn’t enough.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis. Understanding ETL (Extract, Transform, Load) processes is vital for students.
In Part 1 and Part 2 of this series, we described how data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations. Project sponsors seek to empower more and better data-driven decisions and actions throughout their enterprise; they intend to expand their […].
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen DataScience und Data Engineering ist enorm. Data Lakes: Unterstützt MS Azure Blob Storage. Pipelines/ETL : Unterstützt Technologien wie SQL Server Integration Services und Azure Data Factory.
Together with the Hertie School , we co-hosted an inspiring event, Empowering in Data & Governance. The event was opened by Aliya Boranbayeva , representing Women in Big Data Berlin and the Hertie School DataScience Lab , alongside Matthew Poet , representing the Hertie School.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content