This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
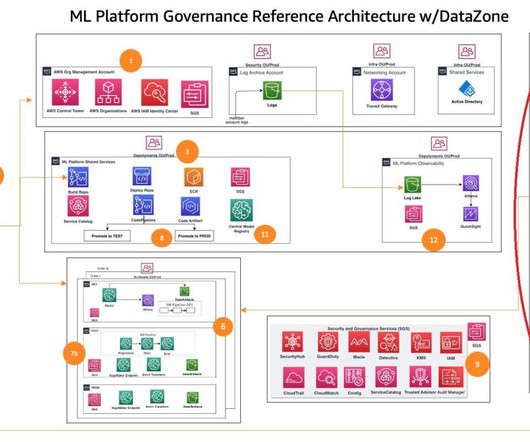
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up datagovernance at scale using Amazon DataZone for the data mesh. However, as data volumes and complexity continue to grow, effective datagovernance becomes a critical challenge.
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
But those end users werent always clear on which data they should use for which reports, as the data definitions were often unclear or conflicting. Business glossaries and early best practices for datagovernance and stewardship began to emerge. A datalake!
Data virtualization is transforming the way organizations access and manage their data. By allowing seamless integration of information from various sources without physical data movement, businesses can gain better insights and streamline their operations. What is data virtualization?
While datalakes and data warehouses are both important Data Management tools, they serve very different purposes. If you’re trying to determine whether you need a datalake, a data warehouse, or possibly even both, you’ll want to understand the functionality of each tool and their differences.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding DataLakes A datalake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Leading companies like Cisco, Nielsen, and Finnair turn to Alation + Snowflake for datagovernance and analytics. By joining forces, we can build more potent, tailored solutions that leverage datagovernance as a competitive asset. Lastly, active datagovernance simplifies stewardship tasks of all kinds.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. In this article, we’ll focus on a datalake vs. data warehouse.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and governdata stored in AWS, on-premises, and third-party sources. The datalake environment is required to configure an AWS Glue database table, which is used to publish an asset in the Amazon DataZone catalog.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “datalake.” While data warehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between DataLakes and Data Warehouses appeared first on DATAVERSITY.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
In an effort to better understand where datagovernance is heading, we spoke with top executives from IT, healthcare, and finance to hear their thoughts on the biggest trends, key challenges, and what insights they would recommend. Get the Trendbook What is the Impact of DataGovernance on GenAI?
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. With an on-premise deployment, enterprises have full control over data security, data access, and datagovernance. Data that needs to be tightly controlled (e.g. The Problem with Hybrid Cloud Environments.
As an organization embraces digital transformation , more data is available to inform decisions. To use that data, decision-makers across the company will need to have access. However, opening the floodgates of information comes with challenges. It can also help prevent data misuse. What is Data Analytics?
“The key point is that no organization governsinformation simply because it can. there has to be a business context, and the increasing realization of this context explains the rise of information stewardship applications.” – May 2018 Gartner Market Guide for Information Stewardship Applications.
A datalake becomes a data swamp in the absence of comprehensive data quality validation and does not offer a clear link to value creation. Organizations are rapidly adopting the cloud datalake as the datalake of choice, and the need for validating data in real time has become critical.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a datalake, and building an API to extract needed information isn’t working. Click to learn more about author Brian Platz.
Big data engineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and datagovernance foundations to enable fine-grained data access.
Many users struggle to access the information they need or understand its full context once that access is unlocked. What’s worse, just 3% of the data in a business enterprise meets quality standards. There’s also no denying that data management is becoming more important, especially to the public.
Cloud analytics is the art and science of mining insights from data stored in cloud-based platforms. By tapping into the power of cloud technology, organizations can efficiently analyze large datasets, uncover hidden patterns, predict future trends, and make informed decisions to drive their businesses forward.
This past week, I had the pleasure of hosting DataGovernance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , DataGovernance lead at Alation. Can you have proper data management without establishing a formal datagovernance program?
The rise of datalakes and adjacent patterns such as the data lakehouse has given data teams increased agility and the ability to leverage major amounts of data. Constantly evolving data privacy legislation and the impact of major cybersecurity breaches has led to the call for responsible data […].
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is datagovernance. What is a DataLake? Today, datalakes and data warehouses are colliding.
A new research report by Ventana Research, Embracing Modern DataGovernance , shows that modern datagovernance programs can drive a significantly higher ROI in a much shorter time span. Historically, datagovernance has been a manual and restrictive process, making it almost impossible for these programs to succeed.
Datagovernance is traditionally applied to structured data assets that are most often found in databases and information systems. This blog focuses on governing spreadsheets that contain data, information, and metadata, and must themselves be governed.
Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake. Create a datalake with Lake Formation.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
It also requires an organization-wide datagovernance approach, from adopting new types of employee training to creating new policies for data storage. Architecture for data democratization Data democratization requires a move away from traditional “data at rest” architecture, which is meant for storing static data.
This explosive growth of data is driven by various factors, including the proliferation of internet-connected devices, social media interactions, and the increasing digitization of business processes. Key Takeaways Big Data originates from diverse sources, including IoT and social media. What is Big Data?
This explosive growth of data is driven by various factors, including the proliferation of internet-connected devices, social media interactions, and the increasing digitization of business processes. Key Takeaways Big Data originates from diverse sources, including IoT and social media. What is Big Data?
According to IDC, the size of the global datasphere is projected to reach 163 ZB by 2025, leading to the disparate data sources in legacy systems, new system deployments, and the creation of datalakes and data warehouses. Most organizations do not utilize the entirety of the data […].
Accounting for the complexities of the AI lifecycle Unfortunately, typical data storage and datagovernance tools fall short in the AI arena when it comes to helping an organization perform the tasks that underline efficient and responsible AI lifecycle management. But the implementation of AI is only one piece of the puzzle.
For the preceding techniques, the foundation should provide scalable infrastructure for data storage and training, a mechanism to orchestrate tuning and training pipelines, a model registry to centrally register and govern the model, and infrastructure to host the model. Access controls to models should be established.
In this four-part blog series on data culture, we’re exploring what a data culture is and the benefits of building one, and then drilling down to explore each of the three pillars of data culture – data search & discovery, data literacy, and datagovernance – in more depth. what does it look like?
Over the past few years, the industry has increasingly recognized the need to adopt a data lakehouse architecture because of the inherent benefits. This approach improves data infrastructure costs and reduces time-to-insight by consolidating more data workloads into a single source of truth on the organization’s datalake.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
Many organizations use data visualization to identify patterns or consumer trends and communicate findings to stakeholders better. Data Integration A data pipeline can be used to gather data from various disparate sources in one data store. Checking the data quality before and after the cleansing steps is critical.
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure.
A Data Catalog is a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses. What is a Data Catalog?
The ways in which we store and manage data have grown exponentially over recent years – and continue to evolve into new paradigms. For much of IT history, though, enterprise data architecture has existed as monolithic, centralized “datalakes.” The post Data Mesh or Data Mess?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content