This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. The following diagram shows a basic layout of how the solution works.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. With an on-premise deployment, enterprises have full control over data security, data access, and datagovernance. Data that needs to be tightly controlled (e.g. The Problem with Hybrid Cloud Environments.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and datagovernance foundations to enable fine-grained data access.
The Precisely team recently had the privilege of hosting a luncheon at the Gartner Data & Analytics Summit in London. It was an engaging gathering of industry leaders from various sectors, who exchanged valuable insights into crucial aspects of datagovernance, strategy, and innovation.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
And third is what factors CIOs and CISOs should consider when evaluating a catalog – especially one used for datagovernance. The Role of the CISO in DataGovernance and Security. They want CISOs putting in place the datagovernance needed to actively protect data. So CISOs must protect data.
His mission is to enable customers achieve their business goals and create value with data and AI. He helps architect solutions across AI/ML applications, enterprise data platforms, datagovernance, and unified search in enterprises.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud data warehouse or datalake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance. Best Practice 5.
In that sense, data modernization is synonymous with cloud migration. Modern data architectures, like cloud data warehouses and cloud datalakes , empower more people to leverage analytics for insights more efficiently. What Is the Role of the Cloud in Data Modernization? Efficient Data Processing.
Collaboration across teams – Shared features allow disparate teams like fraud, marketing, and sales to collaborate on building ML models using the same reliable data instead of creating siloed features. Audit trail for compliance – Administrators can monitor feature usage by all accounts centrally using CloudTrail event logs.
Who should have access to sensitive data? How can my analysts discover where data is located? All of these questions describe a concept known as datagovernance. The Snowflake AI Data Cloud has built an entire blanket of features called Horizon, which tackles all of these questions and more.
Enterprise data architects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of data pipelines. Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
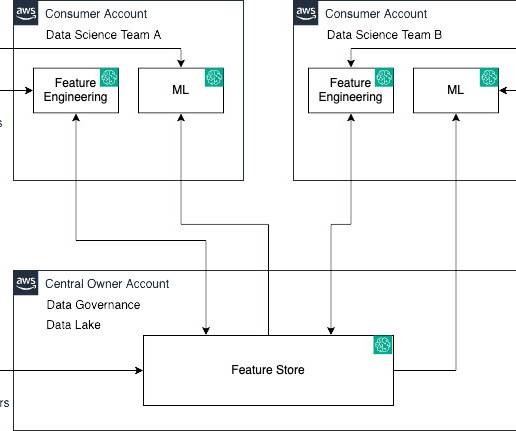
DataGovernance Account This account hosts datagovernance services for datalake, central feature store, and fine-grained data access. The lead data scientist approves the model locally in the ML Dev Account. ML Prod Account This is the production account for new ML models.
Key Takeaways Data Engineering is vital for transforming raw data into actionable insights. Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering?
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. A common use case in healthcare for this connector type is ingesting data from external providers and vendors that deliver flat files.
Overcoming the challenges of data catalog adoption takes more than patience and persistence. You’ll need a plan that recognizes adoption as a process that unfolds over time—not an event that happens at a point in time. People – Which data stakeholders will you bring on board at what times? How will data curation be funded?
Airline Reporting Corporation (ARC) sells data products to travel agencies and airlines. Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 datalake, Snowflake cloud data warehouse and Tableau (and how it can be fixed).
They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. The reason this is an important skill is that ETL is a critical process for data warehousing and business intelligence.
Difficulty in moving non-SAP data into SAP for analytics which encourages data silos and shadow IT practices as business users search for ways to extract the data (which has datagovernance implications).
But how do the unfolding events impact your business? So, ARC worked to make data more accessible across domains while capturing tribal knowledge in the data catalog; this reduced the subject-matter-expertise bottlenecks during product development and accelerated higher quality analysis.
LakeFS LakeFS is an open-source platform that provides datalake versioning and management capabilities. It sits between the datalake and cloud object storage, allowing you to version and control changes to datalakes at scale.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Data Streaming Learning about real-time data collection methods using tools like Apache Kafka and Amazon Kinesis. Students should understand the concepts of event-driven architecture and stream processing. Once data is collected, it needs to be stored efficiently.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Data Security and Governance Maintaining data security is crucial for any company.
And celebrating the ability for Machine Learning Data Catalogs to support data culture in every enterprise. Join us at one of our upcoming events and share your story of human-machine collaboration to create data culture. Follow us at #MLDC as we tour the world. – John F.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content