This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and governdata stored in AWS, on-premises, and third-party sources. The datalake environment is required to configure an AWS Glue database table, which is used to publish an asset in the Amazon DataZone catalog.
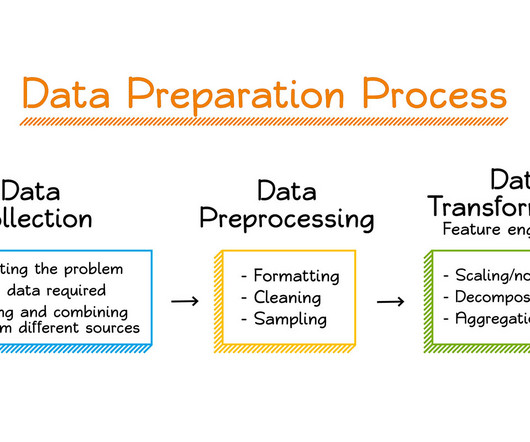
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
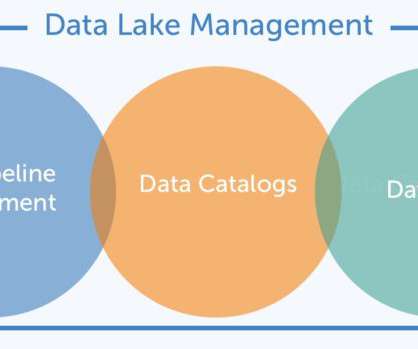
While data fabric is not a standalone solution, critical capabilities that you can address today to prepare for a data fabric include automated data integration, metadata management, centralized datagovernance, and self-service access by consumers. Increase metadata maturity.
The data catalog also stores metadata (data about data, like a conversation), which gives users context on how to use each asset. It offers a broad range of data intelligence solutions, including analytics, datagovernance, privacy, and cloud transformation. Data Catalog by Type.
Figure 1 illustrates the typical metadata subjects contained in a data catalog. Figure 1 – Data Catalog Metadata Subjects. Datasets are the files and tables that data workers need to find and access. They may reside in a datalake, warehouse, master data repository, or any other shared data resource.
This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and datagovernance. 2) When data becomes information, many (incremental) use cases surface.
From a datagovernance perspective, this is a massive risk to organizations by exposing them to the whole laundry of privacy and security breaches. No-code/low-code experience using a diagram view in the datapreparation layer similar to Dataflows. Therefore, Datamarts are not a replacement for Dataflows.
Key Takeaways Data Engineering is vital for transforming raw data into actionable insights. Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering?
Whether it’s for ad hoc analytics, data transformation, data sharing, datalake modernization or ML and gen AI, you have the flexibility to choose. Integrated solutions for zero-ETL datapreparation: IBM databases on AWS offer integrated solutions that eliminate the need for ETL processes in datapreparation for AI.
Data Literacy—Many line-of-business people have responsibilities that depend on data analysis but have not been trained to work with data. Their tendency is to do just enough data work to get by, and to do that work primarily in Excel spreadsheets. Will data stewards assume curation responsibilities?
Even something like gamification may emerge as a way to fully engage data shoppers as a community. Behind the scenes, ‘backroom services” will power the storefront, performing such tasks as data acquisition, datapreparation, data curation and cataloging, and tracking. Building the EDM.
Support for Advanced Analytics : Transformed data is ready for use in Advanced Analytics, Machine Learning, and Business Intelligence applications, driving better decision-making. Compliance and Governance : Many tools have built-in features that ensure data adheres to regulatory requirements, maintaining datagovernance across organisations.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content