This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview Learn about viewing data as streams of immutable events in contrast to mutable containers Understand how Apache Kafka captures real-time data through event. The post Apache Kafka: A Metaphorical Introduction to Event Streaming for Data Scientists and DataEngineers appeared first on Analytics Vidhya.
Introduction A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details. The post Data Abstraction for DataEngineering with its Different Levels appeared first on Analytics Vidhya.
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Whether you’re a researcher, developer, startup founder, or simply an AI enthusiast, these events provide an opportunity to learn from the best, gain hands-on experience, and discover the future of AI. If youre serious about staying at the forefront of AI, development, and emerging tech, DeveloperWeek 2025 is a must-attend event.
In this four-part blog series "Lessons learned from building Cybersecurity Lakehouses," we will discuss a number of challenges organizations face with dataengineering.
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
AI conferences and events are organized to talk about the latest updates taking place, globally. Why must you attend AI conferences and events? Attending global AI-related virtual events and conferences isn’t just a box to check off; it’s a gateway to navigating through the dynamic currents of new technologies. billion by 2032.
One notable recent release is Yambda-5B , a 5-billion-event dataset contributed by Yandex, based on data from its music streaming service, now available via Hugging Face. In recent years, several new datasets have been made public that aim to better reflect real-world usage patterns, spanning music, e-commerce, advertising, and beyond.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Fun Python Projects for Absolute Beginners Bored of theory?
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
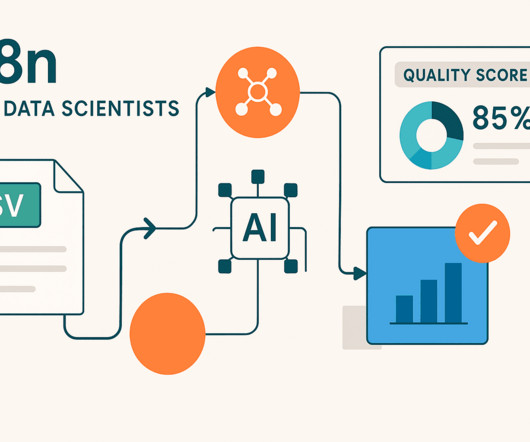
This transforms your workflow into a distribution system where quality reports are automatically sent to project managers, dataengineers, or clients whenever you analyze a new dataset. Email Integration Add a Send Email node to automatically deliver reports to stakeholders by connecting it after the HTML node.
On top of that, this agent should use the content by including relevant hotel information in this proposal for business events or campaigns. Because instead of relying only on the companys document, the model pulls information from its original training data. But there is an issue: the agent frequently hallucinates.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Run the Full DeepSeek-R1-0528 Model Locally Running the quantized version DeepSeek-R1-0528 Model locally (..)
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter The 7 Most Useful Jupyter Notebook Extensions for Data Scientists In this article, we will explore seven (..)
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Serve Machine Learning Models via REST APIs in Under 10 Minutes Stop leaving your models on your laptop. (..)
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Build a Data Cleaning & Validation Pipeline in Under 50 Lines of Python Clean and validate messy (..)
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log Data Model for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Introduction to Apache Flume Apache Flume is a data ingestion mechanism for gathering, aggregating, and transmitting huge amounts of streaming data from diverse sources, such as log files, events, and so on, to a centralized data storage. It has a simplistic and adaptable […].
Initially, it was designed to handle log data solely, but later, it was developed to process eventdata. Introduction Apache Flume, a part of the Hadoop ecosystem, was developed by Cloudera. The Apache Flume tool is designed mainly for ingesting a high volume […]. The post Get to Know Apache Flume from Scratch!
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
After this inspiring start, mentees had the opportunity to participate in speed mentoring sessions, where they engaged with some of the best leaders in data science, AI, big data-driven solutions, sales, business development, dataengineering, partnerships, and more.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Automating GitHub Workflows with Claude 4 Learn how to set up the Claude App in your GitHub repository (..)
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter MLFlow Mastery: A Complete Guide to Experiment Tracking and Model Management MLFlow is a tool that helps (..)
Obstacles for dataengineers & developers Collection and maintenance of data from different sources is itself a hectic task for dataengineers and developers. Connectors are packaged as Docker images, which allows total flexibility over the technologies used to implement them.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter How to Combine Streamlit, Pandas, and Plotly for Interactive Data Apps With just two Python files and (..)
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Integrating DuckDB & Python: An Analytics Guide Learn how to run lightning-fast SQL queries on (..)
Learn More ⟶ Talent Assessment Conduct Customized Online Assessments on our Powerful Cloud-based Platform, Secured with Best-in-class Proctoring Learn More ⟶ Research & Advisory AIM Research produces a series of annual reports on AI & Data Science covering every aspect of the industry.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 FREE AI Tools That’ll Save You 10+ Hours a Week No tech skills needed.
Now that we’re in 2024, it’s important to remember that dataengineering is a critical discipline for any organization that wants to make the most of its data. These data professionals are responsible for building and maintaining the infrastructure that allows organizations to collect, store, process, and analyze data.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Forget Streamlit: Create an Interactive Data Science Dashboard in Excel in Minutes In this tutorial, (..)
This article was published as a part of the Data Science Blogathon. convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically.
Join DataRobot and leading organizations June 7 and 8 at DataRobot AI Experience 2022 (AIX) , a unique virtual event that will help you rapidly unlock the power of AI for your most strategic business initiatives. Join the virtual event sessions in your local time across Asia-Pacific, EMEA, and the Americas. Join DataRobot AIX June 7–8.
All these sites use some event streaming tool to monitor user activities. […]. Introduction Have you ever wondered how Instagram recommends similar kinds of reels while you are scrolling through your feed or ad recommendations for similar products that you were browsing on Amazon?
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content