This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction MongoDB is a free open-source No-SQLdocument database. The post How To Create An Aggregation Pipeline In MongoDB appeared first on Analytics Vidhya.
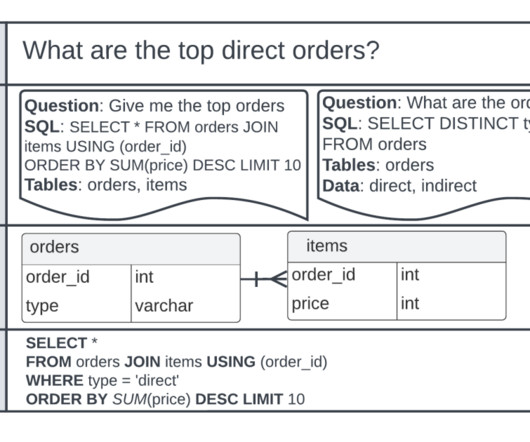
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This can be overwhelming for nontechnical users who lack proficiency in SQL. This application allows users to ask questions in natural language and then generates a SQL query for the users request.
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Create and load sample data In this post, we use two sample datasets: a total sales dataset CSV file and a sales target document in PDF format.
The data is stored in a data lake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. Data is normally stored in databases, and can be queried using the most common query language, SQL. The challenge is to assure quality.
Whether we are analyzing IoT data streams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions? appeared first on Analytics Vidhya.
This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights. A standout application is the SQL-to-natural language capability, which translates complex SQL queries into plain English and vice versa, bridging the gap between technical and business teams.
Summary: The ALTER TABLE command in SQL is used to modify table structures, allowing you to add, delete, or alter columns and constraints. Introduction The ALTER TABLE command in SQL is essential for modifying the structure of existing database tables. What is the ALTER TABLE Command in SQL? Types and Importance.
Just last month, Salesforce made a major acquisition to power its Agentforce platform—just one in a number of recent investments in unstructured data management providers. “Most data being generated every day is unstructured and presents the biggest new opportunity.” What should their next steps be?
It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Fivetran’s automated data movement platform simplifies the ETL (extract, transform, load) process by automating most of the time-consuming tasks of ETL that dataengineers would typically do.
These new components separate and modularize the logic of data handling vs orchestrating. Instead, it automatically decides the chunk size based on the number of documents and other parameters. It defines an execution plan and prepares the data processing. Load The last step is the ingestion of the data into the db2 warehouse.
To start using OpenSearch for anomaly detection you first must index your data into OpenSearch , from there you can enable anomaly detection in OpenSearch Dashboards. To learn more, see the documentation. To learn more, see the documentation. To learn more, see the documentation.
It comes with a rather lightweight intellisense, and highlights for both SQL and Jinja use. The real power is the ability to run your models and view the outputs, or even have your SQL compiled to verify that your Jinja or SQL compiles into the correct model.
Transformers for Document Understanding Vaishali Balaji | Lead Data Scientist | Indium Software This session will introduce you to transformer models, their working mechanisms, and their applications. Free and paid passes are available now–register here.
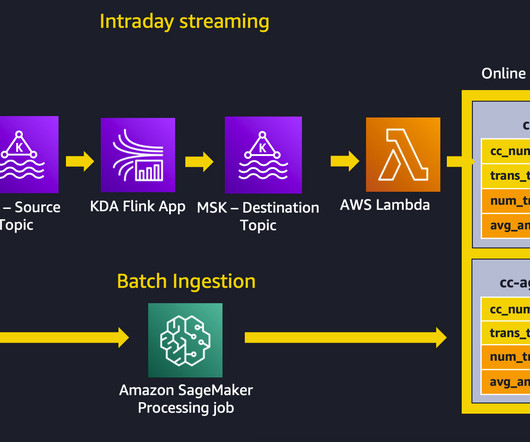
In our use case, we show how using SQL for aggregations can enable a data scientist to provide the same code for both batch and streaming. In our use case, we ingest live credit card transactions to a source MSK topic, and use a Kinesis Data Analytics for Apache Flink application to create aggregate features in a destination MSK topic.
This allows you to explore features spanning more than 40 Tableau releases, including links to release documentation. . A diamond mark can be selected to list the features in that release, and selecting a colored square in the feature list will open release documentation in your browser. The Salesforce purchase in 2019.
to catalog enterprise data by observing analyst behaviors. Our approach was contrasted with the traditional manual wiki of notes and documentation and labeled as a modern data catalog. We envisioned and learnt from the early production customer implementations that cataloging data wasn’t enough.
It offers magic ( %spark , %sql ) commands to run Spark code, perform SQL queries, and configure Spark settings like executor memory and cores. The sparkmagic kernel contains a set of tools for interacting with remote Spark clusters through notebooks.
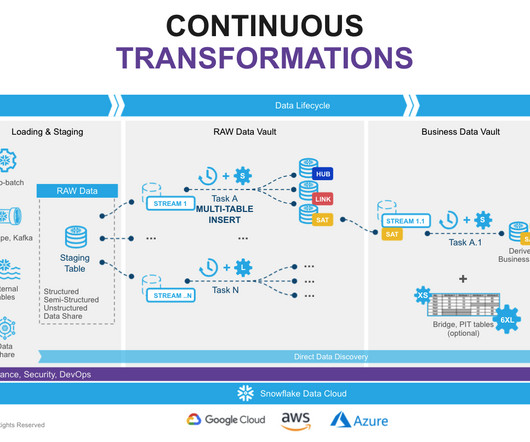
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your data pipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines. Saurabh Gupta is a Principal Engineer at Zeta Global.
However, many analysts and other data professionals run into two common problems: They are not given direct access to their database They lack the skills in SQL to write the queries themselves The traditional solution to these problems is to rely on IT and dataengineering teams. Only use the data you need.
Implementing best practices can improve performance, reduce costs, and improve data quality. This section outlines key practices focused on automation, monitoring and optimisation, scalability, documentation, and governance. To optimise ETL, organisations should conduct thorough analyses to identify these issues.
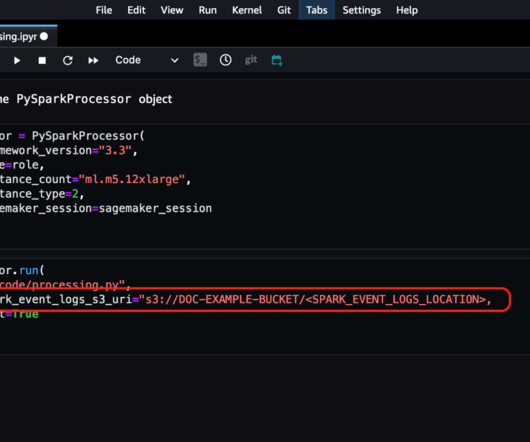
With SageMaker Processing jobs, you can use a simplified, managed experience to run data preprocessing or postprocessing and model evaluation workloads on the SageMaker platform. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. For more information on processing jobs, see Process data.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. Check out the Kubeflow documentation. For example, neptune.ai
Snowflake Copilot, soon-to-be GA, allows technical users to convert questions into SQL. Cortex Search : This feature provides a search solution that Snowflake fully manages from data ingestion, embedding, retrieval, reranking, and generation. At the same time, Cortex Analysts will be able to provide the answers to business questions.
What is Snowpark and Why Use It for Building Data Pipelines? The Snowpark API includes the DataFrame API and integrates with other popular open-source APIs developers can use to complete dataengineering tasks. Please refer to the Snowflake documentation for connecting to Snowflake with Python for more information.
The exam will cover all aspects of using Snowflake and its components to apply data analysis principles, from preparing and loading data to presenting data and meeting business requirements. In the case of practice tests and quizzes, find the relevant section within Snowflake’s documentation for each question.
Though scripted languages such as R and Python are at the top of the list of required skills for a data analyst, Excel is still one of the most important tools to be used. Because they are the most likely to communicate data insights, they’ll also need to know SQL, and visualization tools such as Power BI and Tableau as well.
They are also designed to handle concurrent access by multiple users and applications, while ensuring data integrity and transactional consistency. Examples of OLTP databases include Oracle Database, Microsoft SQL Server, and MySQL. Final words Back to our original question: What is an online transaction processing database?
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
For example, a new data scientist who is curious about which customers are most likely to be repeat buyers, might search for customer data only to discover an article documenting a previous project that answered their exact question. Query editors embedded directly into data catalogs have a few advantages for data scientists.
These procedures are designed to automate repetitive tasks, implement business logic, and perform complex data transformations , increasing the productivity and efficiency of data processing workflows. Snowflake stored procedures and dbt Hooks are essential to modern dataengineering and analytics workflows.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the cloud data warehouse. This graph is an example of one analysis, documented in our internal catalog.
For greater detail, see the Snowflake documentation. Copy Into When loading data into Snowflake, the very first and most important rule to follow is: do not load data with SQL inserts! Loading small amounts of data is cumbersome and costly: Each insert is slow — and time is credits.
Prime examples of this in the data catalog include: Trust Flags — Allow the data community to endorse, warn, and deprecate data to signal whether data can or can’t be used. Data Profiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape.
This allows you to explore features spanning more than 40 Tableau releases, including links to release documentation. . A diamond mark can be selected to list the features in that release, and selecting a colored square in the feature list will open release documentation in your browser. The Salesforce purchase in 2019.
Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. Game changer ChatGPT in Software Engineering: A Glimpse Into the Future | HackerNoon Generative AI for DevOps: A Practical View - DZone ChatGPT for DevOps: Best Practices, Use Cases, and Warnings.
Integration: Airflow integrates seamlessly with other dataengineering and Data Science tools like Apache Spark and Pandas. Open-Source Community: Airflow benefits from an active open-source community and extensive documentation. Scalability: Designed to handle large volumes of data efficiently.
The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode. In 2021, Microsoft enabled Custom SQL queries to be run to Snowflake in DirectQuery mode further enhancing the connection capabilities between the platforms.
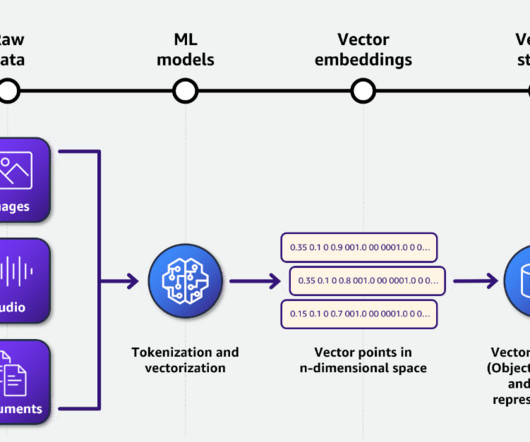
Vectors (and Word Vectors) Vector Databases hold information like documents, images, and audio files that do not fit into the tabular format expected by traditional databases. This is why it makes them appropriate for storing and retrieving non-traditional data sources like documents, images, and audio files. And why stop there?
SageMaker Canvas allows interactive data exploration, transformation, and preparation without writing any SQL or Python code. Complete the following steps to prepare your data: On the SageMaker Canvas console, choose Data preparation in the navigation pane. On the Create menu, choose Document. Choose Create.
Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML. Aggregating and preparing large amounts of data is a critical part of ML workflow. Data scientists and dataengineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content