This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction Companies struggle to manage and report all their data. The data repository should […]. The post Basics of DataModeling and Warehousing for DataEngineers appeared first on Analytics Vidhya.
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
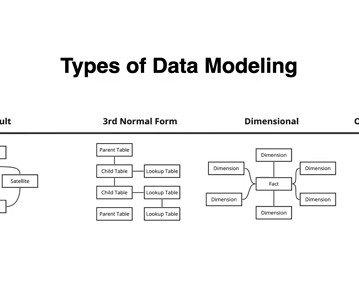
This article was published as a part of the DataScience Blogathon. Introduction A datamodel is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details.
Navigating the realm of datascience careers is no longer a tedious task. In the current landscape, datascience has emerged as the lifeblood of organizations seeking to gain a competitive edge. They require strong analytical skills, knowledge of datamodeling, and expertise in business intelligence tools.
This article was published as a part of the DataScience Blogathon Overview When Apache Cassandra first came out, it included a command-line interface for dealing with thrift. Manipulation of data in this manner was inconvenient and caused knowing the API’s intricacies.
This article was published as a part of the DataScience Blogathon. Introduction NoSQL databases allow us to store vast amounts of data and access them anytime, from any location and device. However, deciding which datamodelling technique best suits your needs is complex.
Introduction In the era of data-driven decision-making, having accurate datamodeling tools is essential for businesses aiming to stay competitive. As a new developer, a robust datamodeling foundation is crucial for effectively working with databases.
Companies use Business Intelligence (BI), DataScience , and Process Mining to leverage data for better decision-making, improve operational efficiency, and gain a competitive edge. The integration of these technologies helps companies harness data for growth and efficiency. Each applications has its own datamodel.
Datascience myths are one of the main obstacles preventing newcomers from joining the field. In this blog, we bust some of the biggest myths shrouding the field. The US Bureau of Labor Statistics predicts that datascience jobs will grow up to 36% by 2031. So, let’s dive into unveiling these myths. 1.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and dataengineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
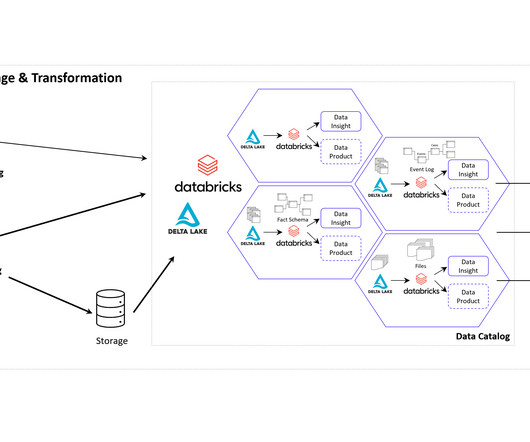
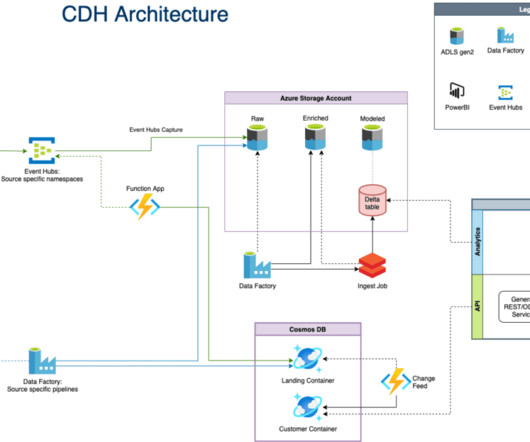
In addition to Business Intelligence (BI), Process Mining is no longer a new phenomenon, but almost all larger companies are conducting this data-driven process analysis in their organization. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
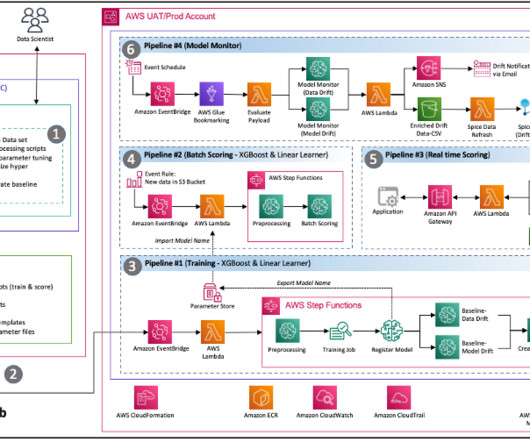
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
In a world of ever-evolving data tools and technologies, some approaches stand the test of time. Thats the case Dustin DorseyPrincipal Data Architect at Onyx makes for dimensional datamodeling , a practice born in the 1990s that continues to provide clarity, performance, and scalability in modern data architecture.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
In the contemporary age of Big Data, Data Warehouse Systems and DataScience Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. The post Why using Infrastructure as Code for developing Cloud-based Data Warehouse Systems?
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? This post will dive deeper into the nuances of each field.
Summary: The fundamentals of DataEngineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Dataengineering refers to the design of systems that are capable of collecting, analyzing, and storing data at a large scale. In manufacturing, dataengineering aids in optimizing operations and enhancing productivity while ensuring curated data that is both compliant and high in integrity.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven DataModeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today. Register here!
Welcome to Beyond the Data, a series that investigates the people behind the talent of phData. DataEngineer at phData. DataEngineer? As a Senior DataEngineer, I wear many hats. On the technical side, I clean and organize data, design storage solutions, and build transformation pipelines.
DataRobot is excited to announce the graduation of the first class of our 10X Applied DataScience Academy. The founding of the 10X Academy is part of DataRobot’s commitment to developing automation that improves the productivity of data scientists while democratizing access to AI for non-data scientists.
Investors and traders are constantly seeking ways to gain an edge, and this is where the role of DataScience in stock market analysis comes in. This article delves into the pivotal role of DataScience in stock market analysis, discussing key takeaways that highlight its significance.
With the integration of SageMaker and Amazon DataZone, it enables collaboration between ML builders and dataengineers for building ML use cases. ML builders can request access to data published by dataengineers. Also, you can update the model’s deploy status.
Foster a Data-Driven Culture Promote a culture where data quality is a shared responsibility. Encourage teams to prioritize data accuracy and consistency at every stage of data handling. Continuous Training and Development The field of datascience is constantly evolving.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Collectively, these modules address governance across various dimensions, such as infrastructure, data, model, and cost. ML platform services This module helps the ML platform engineering team set up shared services that are used by the datascience teams on their team accounts.
Unfortunately, even the datascience industry — which should recognize tabular data’s true value — often underestimates its relevance in AI. Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication.
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines. Saurabh Gupta is a Principal Engineer at Zeta Global.
Of the organizations surveyed, 52 percent were seeking machine learning modelers and data scientists, 49 percent needed employees with a better understanding of business use cases, and 42 percent lacked people with dataengineering skills. Your team already understands your business and your data.
The duties of a Machine Learning Engineer are multi-faceted and encompass a wide range of tasks. Does a machine learning engineer do coding? Machine learning engineers are professionals who possess a blend of skills in software engineering and datascience. How dataengineers tame Big Data?
As you can imagine, datascience is a pretty loose term or big tent idea overall. Though just about every industry imaginable utilizes the skills of a data-focused professional, each has its own challenges, needs, and desired outcomes. What makes this job title unique is the “Swiss army knife” approach to data.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai Check out the Metaflow Docs.
Introduction to Containers for DataScience/DataEngineering Michael A Fudge | Professor of Practice, MSIS Program Director | Syracuse University’s iSchool In this hands-on session, you’ll learn how to leverage the benefits of containers for DS and dataengineering workflows.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Datascience / AI / ML leaders: Heads of DataScience, VPs of Advanced Analytics, AI Lead etc. The book contains a full chapter dedicated to generative AI. Key Takeaways 1.
As they attempt to put machine learning models into production, datascience teams encounter many of the same hurdles that plagued data analytics teams in years past: Finding trusted, valuable data is time-consuming. Obstacles, such as user roles, permissions, and approval request prevent speedy data access.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides datascience and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic datascience concepts to advanced machine learning techniques.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















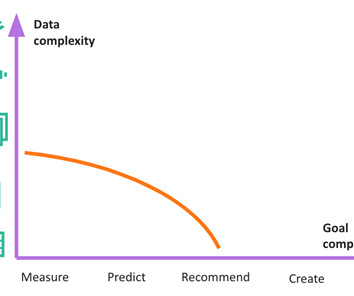





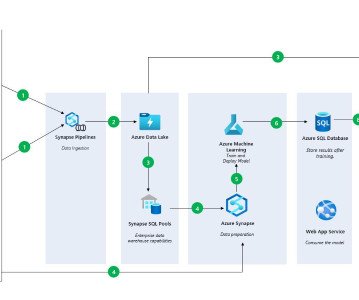



















Let's personalize your content