
Build a financial research assistant using Amazon Q Business and Amazon QuickSight for generative AI–powered insights
MAY 14, 2025
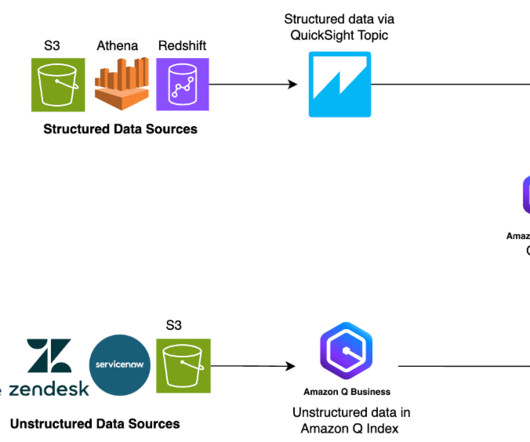
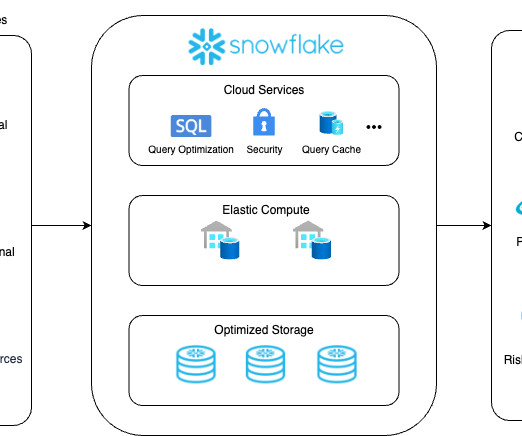
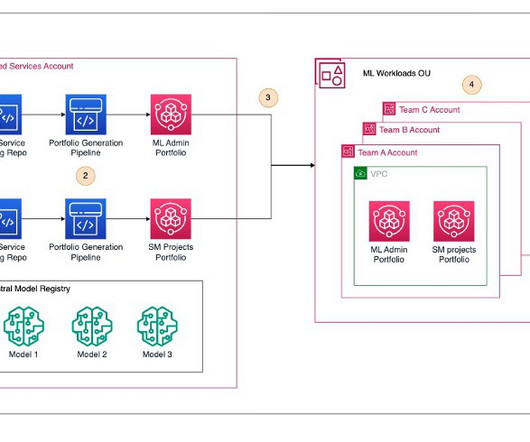
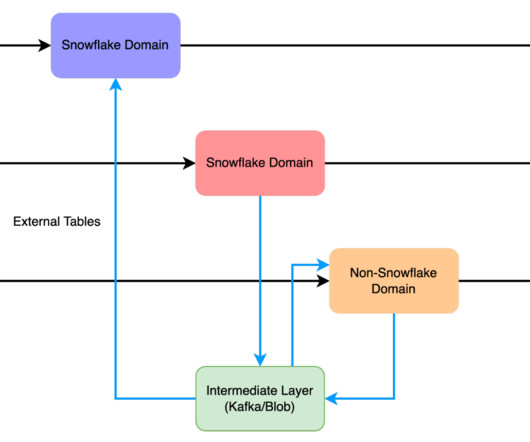
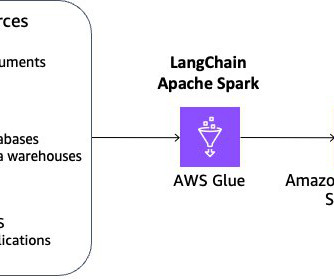
Their information is split between two types of data: unstructured data (such as PDFs, HTML pages, and documents) and structured data (such as databases, data lakes, and real-time reports). Different types of data typically require different tools to access them.



































Let's personalize your content