This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
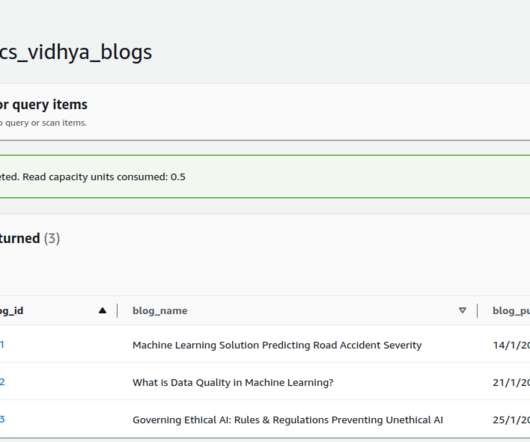
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models MachineLearning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
Introduction The demand for data to feed machinelearning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
🔗 Link to the code on GitHub Why Data Cleaning Pipelines? Think of datapipelines like assembly lines in manufacturing. Wrapping Up Datapipelines arent just about cleaning individual datasets. Each step performs a specific function, and the output from one step becomes the input for the next.
Dataengineers are the unsung heroes of the data-driven world, laying the essential groundwork that allows organizations to leverage their data for enhanced decision-making and strategic insights. What is a dataengineer?
This transforms your workflow into a distribution system where quality reports are automatically sent to project managers, dataengineers, or clients whenever you analyze a new dataset. This proactive approach helps you identify datapipeline issues before they impact downstream analysis or model performance.
Feature Platforms — A New Paradigm in MachineLearning Operations (MLOps) Operationalizing MachineLearning is Still Hard OpenAI introduced ChatGPT. The growth of the AI and MachineLearning (ML) industry has continued to grow at a rapid rate over recent years.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others.
Distinction between data architect and dataengineer While there is some overlap between the roles, a data architect typically focuses on setting high-level data policies. In contrast, dataengineers are responsible for implementing these policies through practical database designs and datapipelines.
Dataengineering startup Prophecy is giving a new turn to datapipeline creation. Known for its low-code SQL tooling, the California-based company today announced data copilot, a generative AI assistant that can create trusted datapipelines from natural language prompts and improve pipeline quality …
By leveraging GenAI, we can streamline and automate data-cleaning processes: Clean data to use AI? Clean data through GenAI! Three ways to use GenAI for better data Improving data quality can make it easier to apply machinelearning and AI to analytics projects and answer business questions.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable datapipelines. What Does a DataEngineer Do?
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
These tools will help you streamline your machinelearning workflow, reduce operational overheads, and improve team collaboration and communication. Machinelearning (ML) is the technology that automates tasks and provides insights. It allows data scientists to build models that can automate specific tasks.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. Reach out to set up a meeting with experts onsite about your AI engineering needs. This post is cowritten with Isaac Cameron and Alex Gnibus from Tecton.
As AI and dataengineering continue to evolve at an unprecedented pace, the challenge isnt just building advanced modelsits integrating them efficiently, securely, and at scale. Join Veronika Durgin as she uncovers the most overlooked dataengineering pitfalls and why deferring them can be a costly mistake.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Analyze data using generative AI. Prepare data for machinelearning.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
DataEngineer. In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a dataengineer, you could also build and maintain datapipelines that create an interconnected data ecosystem that makes information available to data scientists.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. About the Authors Emrah Kaya is DataEngineering Manager at Omron Europe and Platform Lead for ODAP Project.
Overview of core disciplines Data science encompasses several key disciplines including dataengineering, data preparation, and predictive analytics. Dataengineering lays the groundwork by managing data infrastructure, while data preparation focuses on cleaning and processing data for analysis.
Machinelearning (ML) engineer Potential pay range – US$82,000 to 160,000/yr Machinelearningengineers are the bridge between data science and engineering. They are responsible for building intelligent machines that transform our world.
Machinelearning The 6 key trends you need to know in 2021 ? Automation Automating datapipelines and models ➡️ 6. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team?
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
This article explores the importance of ETL pipelines in machinelearning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. What is an ETL datapipeline in ML?
MachineLearning Covering modern ML topics — including ensemble algorithms, feature engineering, AutoML, real-time, and edge deployments — this track emphasizes explainability, bias mitigation, and domain-specific case studies. Ideal for anyone focused on translating data into impactful visuals and stories.
Harrison Chase, CEO and Co-founder of LangChain Michelle Yi and Amy Hodler Sinan Ozdemir, AI & LLM Expert | Author | Founder + CTO of LoopGenius Steven Pousty, PhD, Principal and Founder of Tech Raven Consulting Cameron Royce Turner, Founder and CEO of TRUIFY.AI
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. He specializes in building scalable machinelearning infrastructure, distributed systems, and containerization technologies.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
While speaking at AIMs event DES 2025, Manjunatha G, engineering and site leader at the 3M Global Technology Centre, laid out a practical path to integrate AI agents into dataengineering workflows.
Prompt engineers work closely with data scientists and machinelearningengineers to ensure that the prompts are effective and that the models are producing the desired results. DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data.
Moreover, data integration platforms are emerging as crucial orchestrators, simplifying intricate datapipelines and facilitating seamless connectivity across disparate systems and data sources. These platforms provide a unified view of data, enabling businesses to derive insights from diverse datasets efficiently.
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
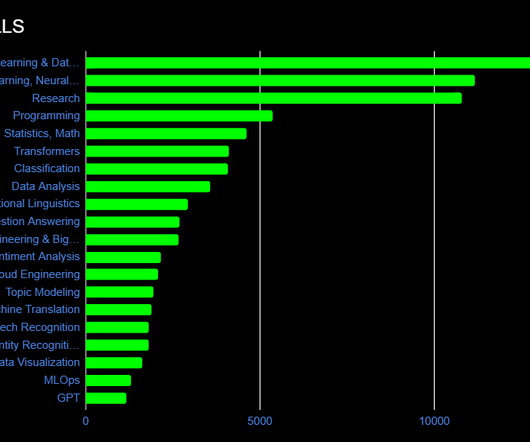
Knowing how spaCy works means little if you don’t know how to apply core NLP skills like transformers, classification, linguistics, question answering, sentiment analysis, topic modeling, machine translation, speech recognition, named entity recognition, and others. The chart below shows what’s hot right now.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
Advanced-DataEngineering and ML Ops with Infrastructure as Code This member-only story is on us. Photo by Markus Winkler on Unsplash This story explains how to create and orchestrate machinelearningpipelines with AWS Step Functions and deploy them using Infrastructure as Code. Upgrade to access all of Medium.
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ MachineLearningEngineer ’ may sound more prestigious than ‘DataEngineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
Best practices for building ETLs for ML Best practices for building ETLs for ML | Source: Author The significance of ETLs in machinelearning projects Exploring a pivotal facet of every machinelearning endeavor: ETLs. These insights are specifically curated for machinelearning applications.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
We couldn’t be more excited to announce two events that will be co-located with ODSC East in Boston this April: The DataEngineering Summit and the Ai X Innovation Summit. Learn more about them below. DataEngineering Summit Our second annual DataEngineering Summit will be in-person for the first time!
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content