This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
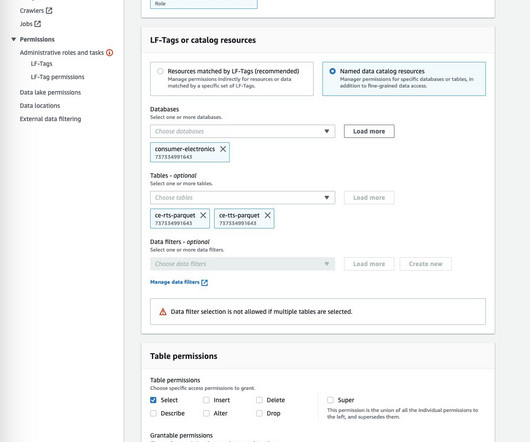
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
Separation of storage and compute : Lakebases store their data in modern datalakes (object stores) in open formats, which enables scaling compute and storage separately, leading to lower TCO and eliminating lock-in. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and MLengineers require capable tooling and sufficient compute for their work. Data scientists and MLengineers require capable tooling and sufficient compute for their work.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
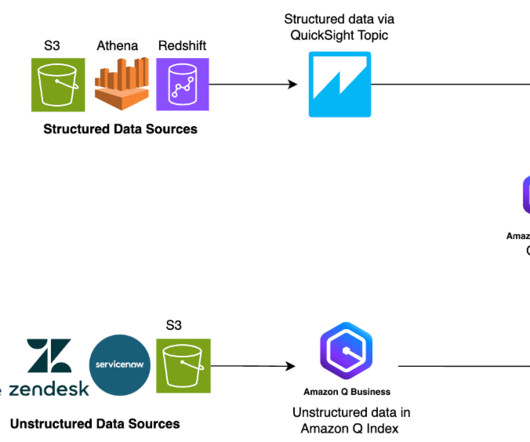
Their information is split between two types of data: unstructured data (such as PDFs, HTML pages, and documents) and structured data (such as databases, datalakes, and real-time reports). Different types of data typically require different tools to access them. Traditionally, businesses face a challenge.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
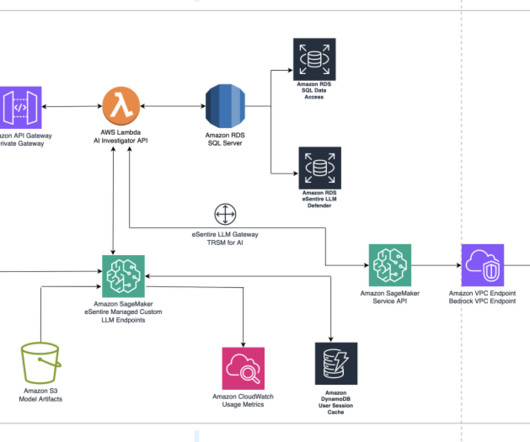
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
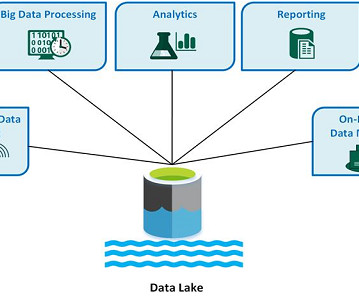
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
5 Concerns for ML Safety in the Era of LLMs and Generative AI The growth of large language models and generative AI has spurred new concerns for ML safety and cybersecurity. 5 DataEngineering and Data Science Cloud Options for 2023 AI development is incredibly resource intensive.
This combination of great models and continuous adaptation is what will lead to a successful machine learning (ML) strategy. MLOps focuses on the intersection of data science and dataengineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle.
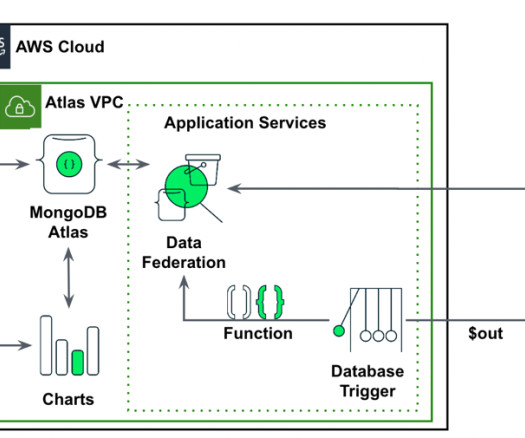
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. MongoDB vector data store MongoDB Atlas Vector Search is a new feature that allows you to store and search vector data in MongoDB.
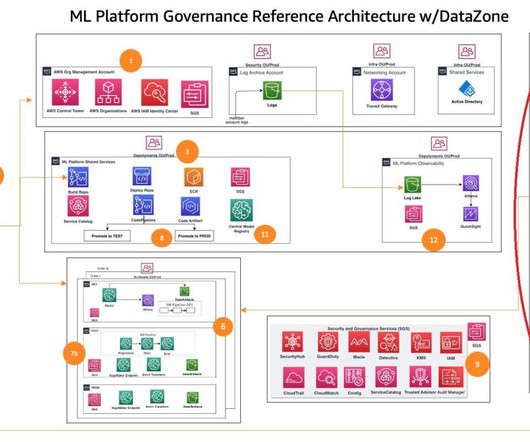
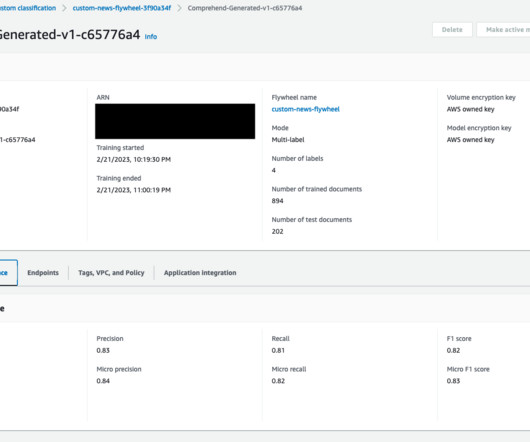
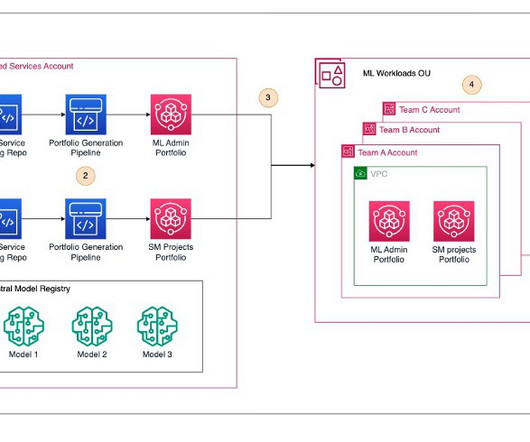
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including datalakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
To achieve the desired accuracy in KPI calculations, the data pipeline was refined to achieve consistent and precise performance, which leads to meaningful insights. At this point, it became possible for the calculator agent to forego the Pandas or Spark data processing implementation.
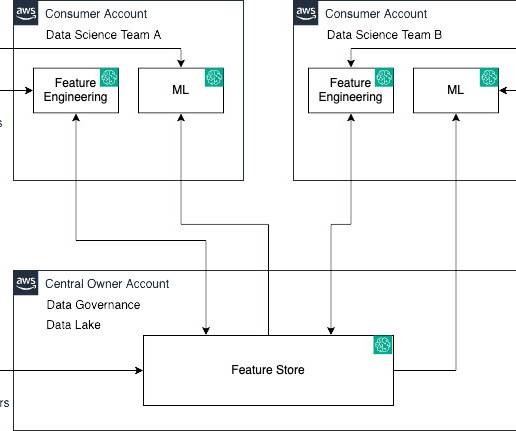
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. Their task is to construct and oversee efficient data pipelines.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. They’re looking for people who know all related skills, and have studied computer science and software engineering.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machine learning (ML) APIs for model development (public preview) and deployment (private preview). phData has been working in dataengineering since the inception of the company back in 2015.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. Given the range of tools and data types, a separate data versioning logic will be necessary.
Despite the challenges, Afri-SET, with limited resources, envisions a comprehensive data management solution for stakeholders seeking sensor hosting on their platform, aiming to deliver accurate data from low-cost sensors. This happens only when a new data format is detected to avoid overburdening scarce Afri-SET resources.
By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
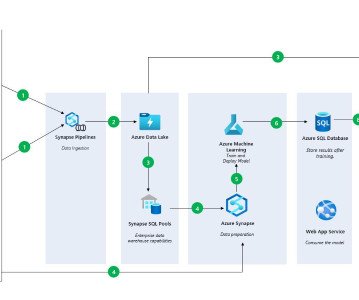
Using Azure ML to Train a Serengeti Data Model, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti Data Model for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
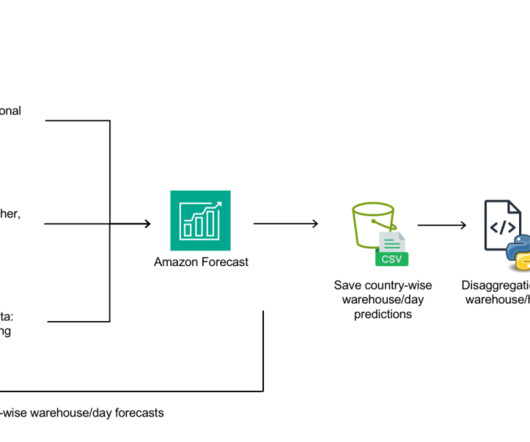
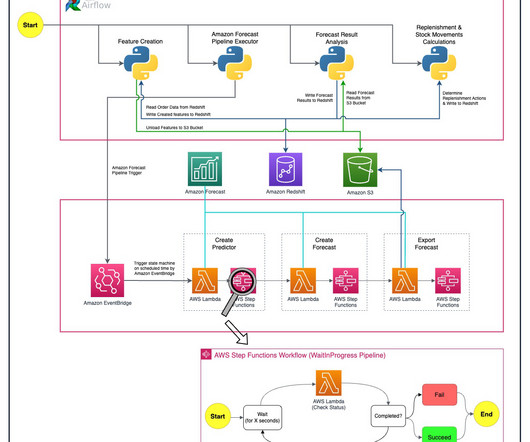
Amazon Forecast is a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts. In this post, we describe how we reduced the modelling time by 70% by doing the feature engineering and modelling using Amazon Forecast. He loves combining open-source projects with cloud services.
Chief Information Officer, Legal Industry Survey respondents noted improved data quality and compliance and risk management as the top two outcomes for organizations with a focus on more standardized data controls when working to implement GenAI and LLM applications.
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. Mutlu Polatcan is a Staff DataEngineer at Getir, specializing in designing and building cloud-native data platforms.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machine learning (ML). The development and use of these models explain the enormous amount of recent AI breakthroughs.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
You’ll use MLRun, Langchain, and Milvus for this exercise and cover topics like the integration of AI/ML applications, leveraging Python SDKs, as well as building, testing, and tuning your work. In this session, we’ll demonstrate how you can fine-tune a Gen AI model, build a Gen AI application, and deploy it in 20 minutes.
Powering a knowledge management system with a data lakehouse Organizations need a data lakehouse to target data challenges that come with deploying an AI-powered knowledge management system. It provides the combination of datalake flexibility and data warehouse performance to help to scale AI.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. IBM watsonx.ai With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
Over time, we called the “thing” a data catalog , blending the Google-style, AI/ML-based relevancy with more Yahoo-style manual curation and wikis. Thus was born the data catalog. In our early days, “people” largely meant data analysts and business analysts. ML and DataOps teams).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content