This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Image Source: GitHub Table of Contents What is DataEngineering? Components of DataEngineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is DataEngineering?
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
This article was published as a part of the Data Science Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models MachineLearning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Data Lakehouse has emerged as a significant innovation in data management architecture, bridging the advantages of both datalakes and data warehouses. By enabling organizations to efficiently store various data types and perform analytics, it addresses many challenges faced in traditional data ecosystems.
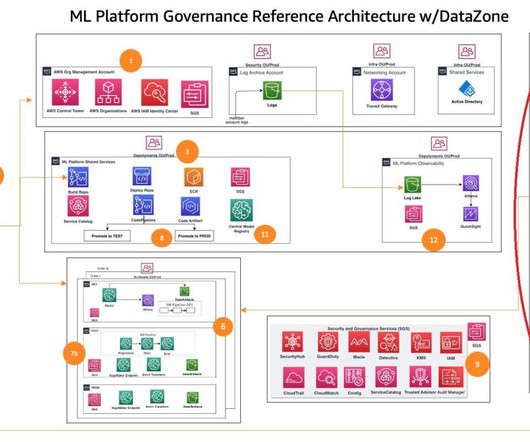
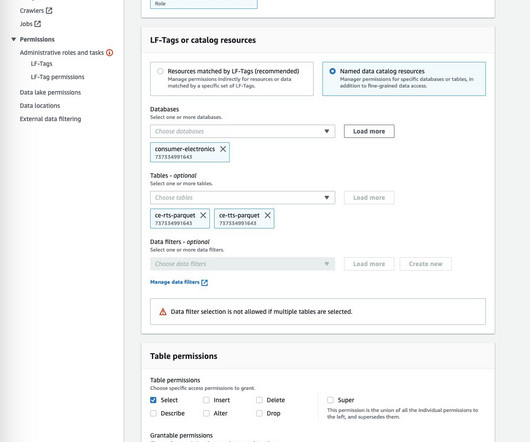
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. Data governance account – This account hosts the central data governance services provided by Amazon DataZone.
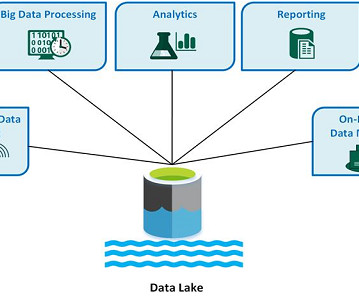
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
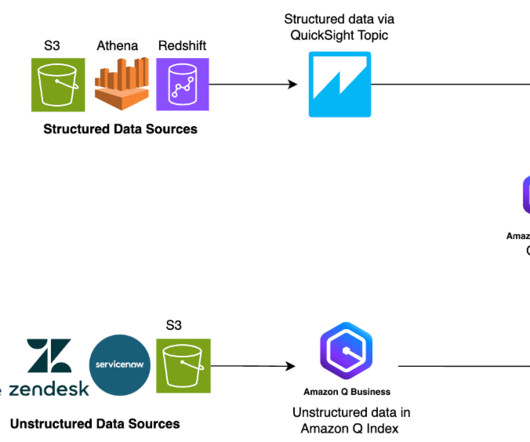
Data is the foundation for machinelearning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machinelearning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
Customers of every size and industry are innovating on AWS by infusing machinelearning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. How to improve indexing.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machinelearning (ML), data sharing and monetization, and more.
DatasaurAI-Powered DataLabeling Datasaur focuses on improving AI development with its open-source data labeling solutions. Designed for NLP and machinelearning applications, Datasaurs tools enable teams to streamline data annotation workflows.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. Register by Friday for 50% off! See them here!
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Big Data Architect. Zach Mitchell is a Sr.
Their information is split between two types of data: unstructured data (such as PDFs, HTML pages, and documents) and structured data (such as databases, datalakes, and real-time reports). Different types of data typically require different tools to access them. Traditionally, businesses face a challenge.
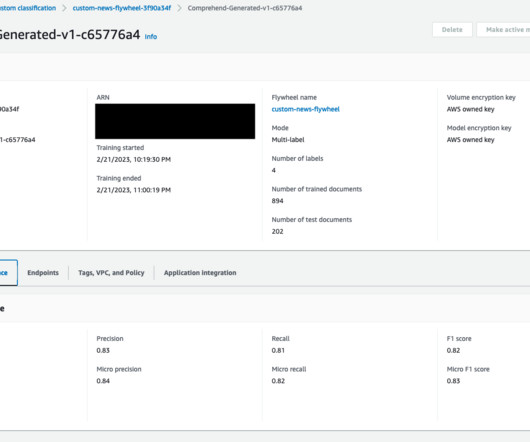
This combination of great models and continuous adaptation is what will lead to a successful machinelearning (ML) strategy. Today, we are excited to announce the launch of Amazon Comprehend flywheel—a one-stop machinelearning operations (MLOps) feature for an Amazon Comprehend model.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Manual labor is no longer the only option for improving data.
Prompt engineers work closely with data scientists and machinelearningengineers to ensure that the prompts are effective and that the models are producing the desired results. DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data.
When you think of dataengineering , what comes to mind? In reality, though, if you use data (read: any information), you are most likely practicing some form of dataengineering every single day. Said differently, any tools or steps we use to help us utilize data can be considered dataengineering.
To achieve the desired accuracy in KPI calculations, the data pipeline was refined to achieve consistent and precise performance, which leads to meaningful insights. At this point, it became possible for the calculator agent to forego the Pandas or Spark data processing implementation.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. Scikit-learn also earns a top spot thanks to its success with predictive analytics and general machinelearning.
5 DataEngineering and Data Science Cloud Options for 2023 AI development is incredibly resource intensive. As such, here are a few data science cloud options to help you handle some work virtually. Learn more about how you can speak and present at ODSC West here! Here are a few things to keep an eye out for.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services.
EvolvabilityIts Mostly About Data Contracts Editors note: Elliott Cordo is a speaker for ODSC East this May 1315! Be sure to check out his talk, Enabling Evolutionary Architecture in DataEngineering , there to learn about data contracts and plentymore.
Amazon SageMaker enables enterprises to build, train, and deploy machinelearning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. As a DataEngineer he was involved in applying AI/ML to fraud detection and office automation.
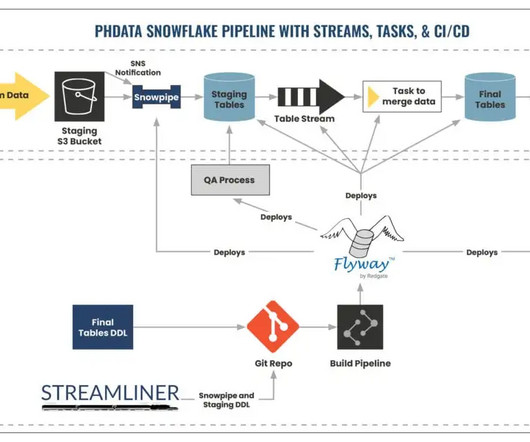
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machinelearning (ML) APIs for model development (public preview) and deployment (private preview). phData has been working in dataengineering since the inception of the company back in 2015.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content