This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
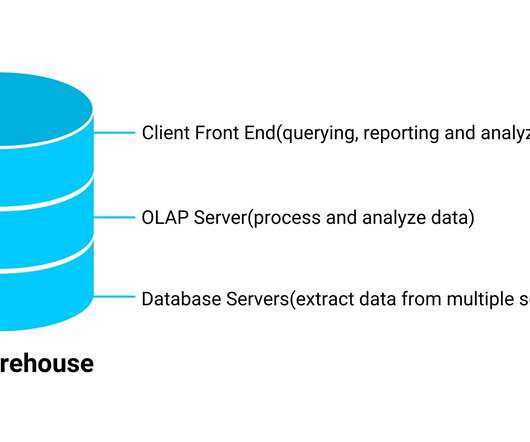
Image Source: GitHub Table of Contents What is DataEngineering? Components of DataEngineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is DataEngineering?
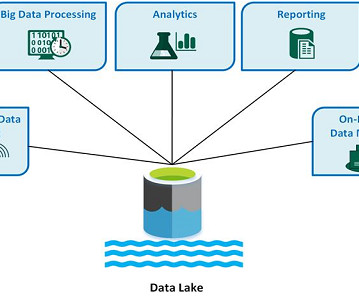
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
This article was published as a part of the Data Science Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
By their definition, the types of data it stores and how it can be accessible to users differ. This article will discuss some of the features and applications of data warehouses, data marts, and data […]. The post Data Warehouses, Data Marts and DataLakes appeared first on Analytics Vidhya.
Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better? We can use it to represent facts, figures, and other information that we can use to make decisions. appeared first on Analytics Vidhya.
Overview Understand the meaning of datalake and data warehouse We will see what are the key differences between Data Warehouse and DataLake. The post What are the differences between DataLake and Data Warehouse? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
A comparative overview of data warehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. Data Warehouse appeared first on Analytics Vidhya.
Separation of storage and compute : Lakebases store their data in modern datalakes (object stores) in open formats, which enables scaling compute and storage separately, leading to lower TCO and eliminating lock-in. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Introduction We are all pretty much familiar with the common modern cloud data warehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as Azure DataLake Storage Gen2) AND a data warehouse compute engine […].
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. The post Warehouse, Lake or a Lakehouse – What’s Right for you? Selecting one among […].
Data Lakehouse has emerged as a significant innovation in data management architecture, bridging the advantages of both datalakes and data warehouses. By enabling organizations to efficiently store various data types and perform analytics, it addresses many challenges faced in traditional data ecosystems.
Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform. Enterprises have slowly started adopting Lakehouses for their data ecosystems as they offer cost efficiencies of datalakes and the performance of warehouses. […].
As organizations are maturing their data infrastructure and accumulating more data than ever before in their datalakes, Open and Reliable table formats.
Big dataengineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
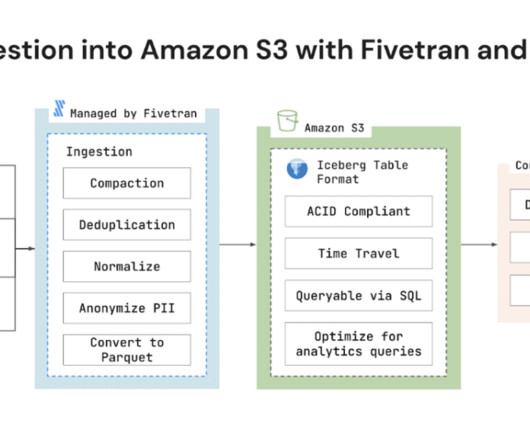
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. Well also dive into […] The post How to Use Apache Iceberg Tables? appeared first on Analytics Vidhya.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. On the home page, select Synapse DataEngineering.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
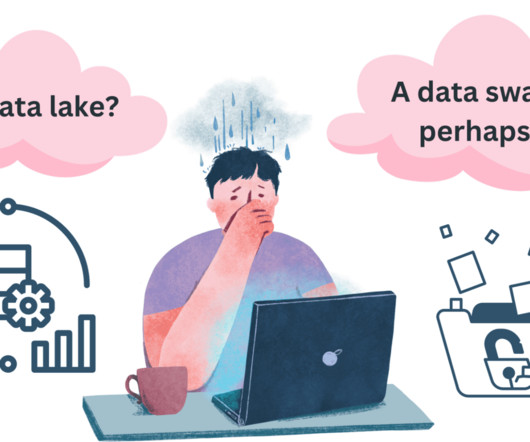
The Data Dilemma: From Chaos toClarity In the world of data management, weve all beenthere: A simple request spirals into a maze of thingslike: A CSV labeled final_v2_final_final.csv A Parquet file in a forgotten S3folder A table with brokenlineage An abandoned SQL notebook from yearsago What starts as a datalake often becomes a dataswamp!
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Today we’re excited to announce the launch of Segment DataLakes, a new turnkey customer datalake that provides the dataengineering foundation needed to power data science and advanced analytics use cases.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. It can also be integrated into major data platforms like Snowflake.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
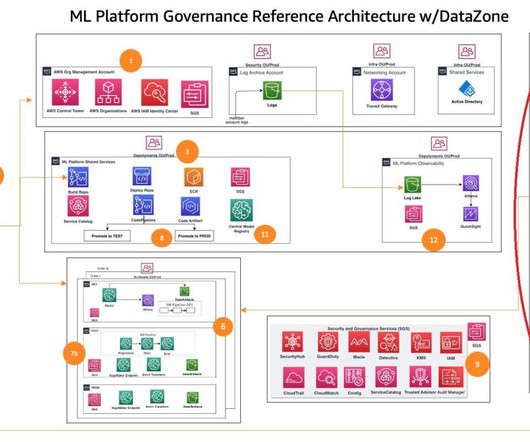
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
We’ve just wrapped up our first-ever DataEngineering Summit. If you weren’t able to make it, don’t worry, you can watch the sessions on-demand and keep up-to-date on essential dataengineering tools and skills. It also addresses the strategies and best practices for implementing a data mesh.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content