
Data Classification: Does Python still have a need for class without dataclass?
Hacker News
FEBRUARY 14, 2023
Comments (..)

Hacker News
FEBRUARY 14, 2023
Comments (..)

Smart Data Collective
JANUARY 9, 2023
SQL uses a straightforward system of data classification with tables and columns that make it relatively easy for people to navigate and use. Python is a high-level, general-purpose programming language that has a wide variety of uses and applications. R Programming Language.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
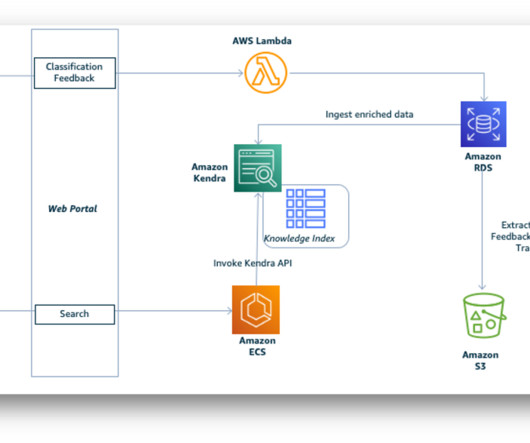
AWS Machine Learning Blog
MARCH 29, 2023
Data ingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The postprocessing component is capable of extracting data from complex, multi-format, multi-page PDF files with varying headers, footers, footnotes, and multi-column data.
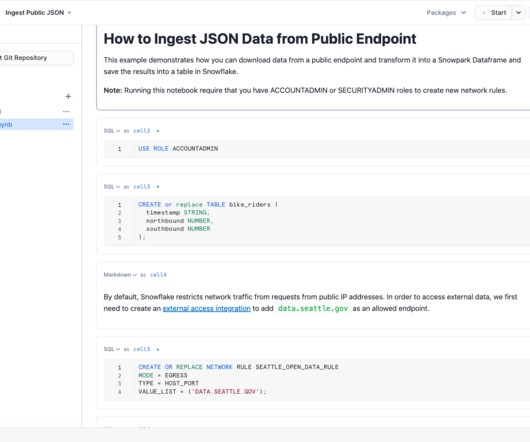
phData
JULY 1, 2024
Snowflake announced many new features that will enhance development and collaboration: Snowflake Notebooks: Currently available in public preview, Snowflake notebooks provide a notebook interface that enables data teams to collaborate with Python and SQL in one place. Furthermore, Snowflake Notebooks can also be run on a schedule.

phData
OCTOBER 23, 2023
Limitation of Data Classification Table Function Tagging is a feature in Snowflake, represented as a schema-level object. It empowers a data governance team to mark and label PII and sensitive information, followed by associating a policy object to safeguard these fields.

AWS Machine Learning Blog
MARCH 27, 2025
Prerequisites To follow along with this post, set up Amazon SageMaker Studio to run Python in a notebook and interact with Amazon Bedrock. The Python code invokes the Amazon Bedrock Runtime service: import boto3 import json from datetime import datetime import time # Create an Amazon Bedrock Runtime client in the AWS Region of your choice.
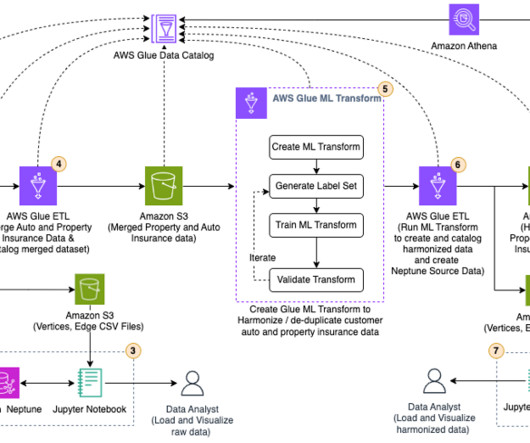
JUNE 26, 2023
Load and visualize the raw data in Neptune This section uses SageMaker Jupyter notebooks to load, query, explore, and visualize the raw property and auto insurance data in Neptune. We use Python scripts to analyze the data in a Jupyter notebook. Under Data classification tools, choose Record Matching.

Expert insights. Personalized for you.







Let's personalize your content