This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The K-NearestNeighbor (KNN) algorithm is an intriguing method in the realm of supervised learning, celebrated for its simplicity and intuitive approach to predicting outcomes. Often employed for both classification and regression tasks, KNN leverages the proximity of data points to derive insights and make decisions.
Zheng’s “Guide to Data Structures and Algorithms” Parts 1 and Part 2 1) Big O Notation 2) Search 3) Sort 3)–i)–Quicksort 3)–ii–Mergesort 4) Stack 5) Queue 6) Array 7) Hash Table 8) Graph 9) Tree (e.g.,
By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. The data mining process The data mining process is structured into four primary stages: data gathering, data preparation, data mining, and dataanalysis and interpretation.
This reveals hidden patterns that might have been overlooked in traditional dataanalysis methods. Nearestneighbor search algorithms : Efficiently retrieving the closest patient vec t o r s to a given query. Indexing : The vector database utilizes algorithms like PQ, LSH, or HNSW (detailed below) to index vectors.
The objective is to construct models that can accurately predict the class of new, unseen data, making classification a cornerstone of dataanalysis. They function by breaking down data into subsets based on feature values, ultimately leading to class label predictions at the leaves of the tree.
Support Vector Machines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space. Decision Trees: These work by asking a series of yes/no questions based on data features to classify data points.
Handling missing data in causal AI To ensure reliable results, Causal AI implements various strategies for effectively managing missing data: Data imputation : Techniques, including KNearestNeighbor and Moving Average, help estimate missing values.
Oil and gas dataanalysis – Before beginning operations at a well a well, an oil and gas company will collect and process a diverse range of data to identify potential reservoirs, assess risks, and optimize drilling strategies. Consider a financial dataanalysis system.
A sector that is currently being influenced by machine learning is the geospatial sector, through well-crafted algorithms that improve dataanalysis through mapping techniques such as image classification, object detection, spatial clustering, and predictive modeling, revolutionizing how we understand and interact with geographic information.
Nevertheless, its applications across classification, regression, and anomaly detection tasks highlight its importance in modern data analytics methodologies. The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning?
In this article, we will discuss the KNN Classification method of analysis. The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel.
Therefore, it mainly deals with unlabelled data. The ability of unsupervised learning to discover similarities and differences in data makes it ideal for conducting exploratory dataanalysis. It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean.
Classification algorithms —predict categorical output variables (e.g., “junk” or “not junk”) by labeling pieces of input data. Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others.
By the end of the lesson, readers will have a solid grasp of the underlying principles that enable these applications to make suggestions based on dataanalysis. Figure 7: TF-IDF calculation (source: Towards Data Science ). The item ratings of these -closest neighbors are then used to recommend items to the given user.
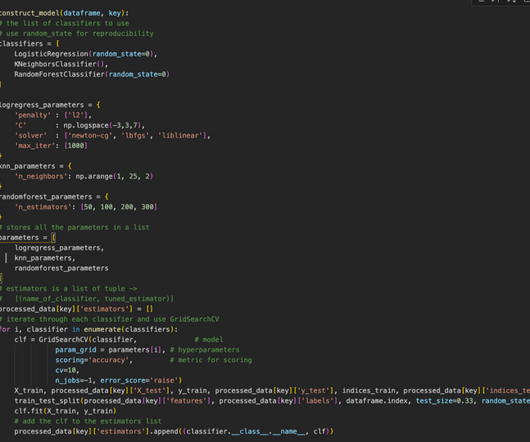
Common machine learning algorithms for supervised learning include: K-nearestneighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. Regression modeling is a statistical tool used to find the relationship between labeled data and variable data.
Without this library, dataanalysis wouldn’t be the same without pandas, which reign supreme with its powerful data structures and manipulation tools. Pandas provides a fast and efficient way to work with tabular data. It is widely used in data science, finance, and other fields where dataanalysis is essential.
Its internal deployment strengthens our leadership in developing dataanalysis, homologation, and vehicle engineering solutions. Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input.
To maintain the integrity of our core data, we do not retain or use the prompts or the resulting account summary for model training. Instead, after a summary is produced and delivered to the seller, the generated content is permanently deleted.
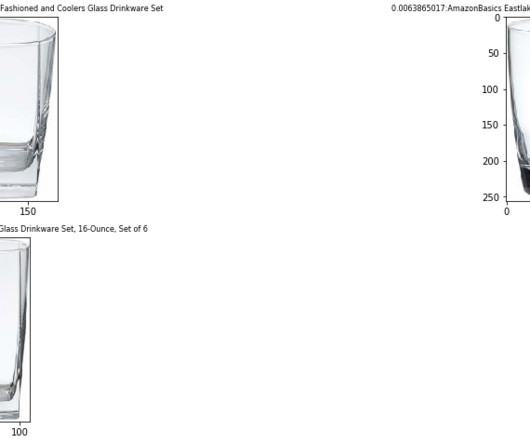
You use pandas to load the metadata, then select products that have US English titles from the data frame. Pandas is an open-source dataanalysis and manipulation tool built on top of the Python programming language. We use the first metadata file in this demo. You use an attribute called main_image_id to identify an image.
Some common quantitative evaluations are linear probing , Knearestneighbors (KNN), and fine-tuning. Multi-modal/temporal data is one of the important aspects of remote sensing and deep learning. It allows us to perform big dataanalysis. Besides that, there is also qualitative evaluation.
Anomaly Detection in Machine Learning: An approach to dataanalysis and Machine Learning called “anomaly detection,” also referred to as “outlier detection,” focuses on finding data points or patterns that considerably differ from what is considered to be “normal” or anticipated behaviour.
Data Cleaning: Raw data often contains errors, inconsistencies, and missing values. Data cleaning identifies and addresses these issues to ensure data quality and integrity. Data Visualisation: Effective communication of insights is crucial in Data Science.
K-NearestNeighbors), while others can handle large datasets efficiently (e.g., It offers extensive support for Machine Learning, dataanalysis, and visualisation. It’s also important to consider the algorithm’s complexity, the model’s interpretability, and its scalability. Random Forests).
K-Nearest Neighbou r: The k-NearestNeighbor algorithm has a simple concept behind it. The method seeks the knearest neighbours among the training documents to classify a new document and uses the categories of the knearest neighbours to weight the category candidates [3].
Anomaly detection ( Figure 2 ) is a critical technique in dataanalysis used to identify data points, events, or observations that deviate significantly from the norm. Similarly, autoencoders can be trained to reconstruct input data, and data points with high reconstruction errors can be flagged as anomalies.
The following Venn diagram depicts the difference between data science and data analytics clearly: 3. Dataanalysis can not be done on a whole volume of data at a time especially when it involves larger datasets. The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance.
That post was dedicated to an exploratory dataanalysis while this post is geared towards building prediction models. among supervised models and k-nearestneighbors, DBSCAN, etc., Motivation The motivating question is— ‘What are the chances of survival of a heart failure patient?’. among unsupervised models.
Heart disease stands as one of the foremost global causes of mortality today, presenting a critical challenge in clinical dataanalysis. Leveraging hybrid machine learning techniques, a field highly effective at processing vast healthcare data volumes is increasingly promising in effective heart disease prediction.
Identifying and addressing these missing values is essential for accurate dataanalysis and effective modeling. Categories of missing data Understanding the different categories of missing data helps in choosing the right strategy for handling them.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content