This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Census studies: Collection of demographic data linked to specific locations. Land records: Documentation of land ownership and usage. Uses beyond traditional applications Spatial data is increasingly important in scientific research, public policy, healthcare innovations, and technological advancements.
Data integration plays a key role in achieving this by incorporating data cleansing techniques, ensuring that the information used is accurate and consistent. Reduction of data silos Breaking down data silos is essential for enhancing collaboration across different departments within an organization.
Garbage in, garbage out (GIGO) highlights a fundamental truth in data processing: the quality of the output is only as good as the quality of the input. This principle resonates across various domains, from software development to dataanalysis, and underscores the critical relationship between input and results.
This solution extends the capabilities demonstrated in Automate chatbot for document and data retrieval using Amazon Bedrock Agents and Knowledge Bases , which discussed using Amazon Bedrock Agents for document and data retrieval. This capability enables users to query structured data using natural language.
Monitoring Key Performance Indicators (KPIs) Health care organizations deploying AI are likely incorporating other digital transformations such as the Internet of Things and other smart technologies to gather data. This process is time-consuming and requires copious amounts of data.
As Roosh Ventures notes, the data streaming market is rapidly evolving today. Big Data, the Internet of Things , and AI generate continuous streams of data but companies currently lack the infrastructure development experience to leverage this effectively.
New Avenues of Data Discovery. New data-collection technologies , like internet of things (IoT) devices, are providing businesses with vast banks of minute-to-minute data unlike anything collected before. The Growing BI Analyst Shortage.
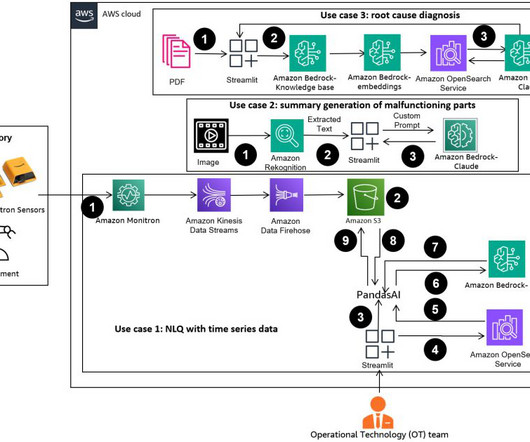
Agents like PandasAI come into play, running this code on high-resolution time series data and handling errors using FMs. PandasAI is a Python library that adds generative AI capabilities to pandas, the popular dataanalysis and manipulation tool. Next, you create the knowledge base for the documents in Amazon S3.
While hospitals mostly do the same things, the communities that they serve can be very different. Dataanalysis allows Town X’s hospital to anticipate what sort of medical conditions these high obesity levels will produce, and plan accordingly. The benefits of using data technology are well documented.
Conversely, OLAP systems are optimized for conducting complex dataanalysis and are designed for use by data scientists, business analysts, and knowledge workers. OLAP systems support business intelligence, data mining, and other decision support applications.
Python’s dataanalysis and visualization libraries, such as Pandas and Matplotlib, empower Data Scientists and analysts to derive valuable insights. It is widely used for dataanalysis, modeling, and building Machine Learning models. Its flexibility allows developers to work on diverse projects.
Protein folding , document summarisation and playing chess are just a few of the applications that we have seen in previous years. Exemplifying the potential of combining AI with Internet of Things technology, dairy cow farms reportedly monitored and improved the health of their livestock.
Until recently, managers and technicians relied on manual tools like Excel spreadsheets and document tracking to accomplish this. Predictive maintenance constantly assesses and re-assesses an asset’s condition in real-time via sensors that collect data via IoT.
DataAnalysis is significant as it helps accurately assess data that drive data-driven decisions. Different tools are available in the market that help in the process of analysis. It is a powerful and widely-used platform that revolutionises how organisations analyse and derive insights from their data.
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient dataanalysis across clusters. Variety Variety indicates the different types of data being generated.
Like most Gen AI use cases, the first step to achieving customer service automation is to clean and centralize all information in a data warehouse for your AI to work from. Document Search Everyone who’s ever read a product manual knows it can be notoriously complex, and finding the information you’re looking for is difficult.
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient dataanalysis across clusters. Variety Variety indicates the different types of data being generated.
By incorporating metadata into the data model, users can easily discover, understand, and interpret the data stored in the lake. With the amounts of data involved, this can be crucial to utilizing a data lake effectively. However, this can be time-consuming and prone to human error, leading to misinformation.
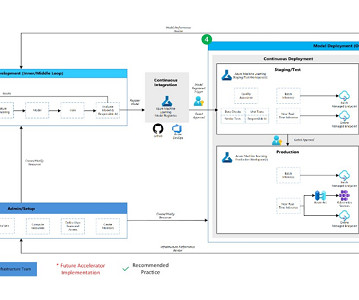
Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow. A typical workflow is illustrated here from data ingestion, EDA (Exploratory DataAnalysis), experimentation, model development and evaluation, to the registration of a candidate model for production.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content