This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. Thus, the earlier in the process that data is cleansed and curated, the more time data consumers can reduce in datapreparation and cleansing.
Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. Thus, the earlier in the process that data is cleansed and curated, the more time data consumers can reduce in datapreparation and cleansing.
Proper data preprocessing is essential as it greatly impacts the model performance and the overall success of dataanalysis tasks ( Image Credit ) Data integration Data integration involves combining data from various sources and formats into a unified and consistent dataset.
Continuous ML model retraining is one method to overcome this challenge by relearning from the most recent data. This requires not only well-designed features and ML architecture, but also datapreparation and ML pipelines that can automate the retraining process. But there is still an engineering challenge.
They all agree that a Datamart is a subject-oriented subset of a data warehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for dataanalysis, not the full history of data.
SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including dataanalysis, data processing, model training, generative AI app building, and more, in a single governed environment.
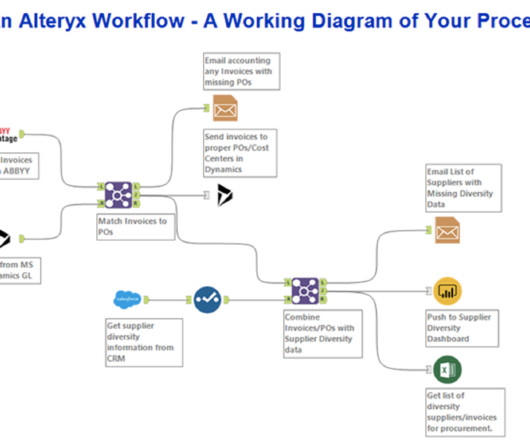
The platform employs an intuitive visual language, Alteryx Designer, streamlining datapreparation and analysis. With Alteryx Designer, users can effortlessly input, manipulate, and output data without delving into intricate coding, or with minimal code at most. What is Alteryx Designer?
By integrating AI capabilities, Excel can now automate DataAnalysis, generate insights, and even create visualisations with minimal human intervention. AI-powered features in Excel enable users to make data-driven decisions more efficiently, saving time and effort while uncovering valuable insights hidden within large datasets.
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
This includes duplicate removal, missing value treatment, variable transformation, and normalization of data. Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for datapreparation before analysis.
Data lakes, while useful in helping you to capture all of your data, are only the first step in extracting the value of that data. We recently announced an integration with Trifacta to seamlessly integrate the Alation Data Catalog with self-service data prep applications to help you solve this issue.
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries.
It enables reporting and DataAnalysis and provides a historical data record that can be used for decision-making. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity.
The output of a query can be displayed directly within the notebook, facilitating seamless integration of SQL and Python workflows in your dataanalysis. These connections are used by AWS Glue crawlers, jobs, and development endpoints to access various types of data stores. They can also be written to a pandas DataFrame.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. I’ll show you best practices for using Jupyter Notebooks for exploratory dataanalysis. When data science was sexy , notebooks weren’t a thing yet.
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. In this section, I will talk about best practices around building the Data Processing platform. are present in the data. How to set up an ML Platform in eCommerce?
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
AWS SageMaker serves as a complete autonomous machine learning system, which makes the entire ML process easier by handling datapreparation together with model training and deployment, and monitoring functions. Selected organizations choose to implement combined approaches in their dataanalysis methods.
Sales teams can forecast trends, optimize lead scoring, and enhance customer engagement all while reducing manual dataanalysis. From customer service chatbots to data-driven decision-making , Watson enables businesses to extract insights from large-scale datasets with precision.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content