This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. Developed by Yandex, CatBoost was built to address two of the most significant challenges in machinelearning: Handling categorical variables efficiently. random_state=42) 3.
Sign in Sign out Contributor Portal Latest Editor’s Picks Deep Dives Contribute Newsletter Toggle Mobile Navigation LinkedIn X Toggle Search Search Data Science How I Automated My MachineLearning Workflow with Just 10 Lines of Python Use LazyPredict and PyCaret to skip the grunt work and jump straight to performance.
Overfitting in machinelearning is a common challenge that can significantly impact a model’s performance. What is overfitting in machinelearning? The model essentially memorizes the training data rather than learning to generalize from it.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Get the FREE ebook The Great Big Natural Language Processing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, MachineLearning, AI & Analytics straight to your inbox.
Grid search is a powerful technique that plays a crucial role in optimizing machinelearning models. By systematically exploring a set range of hyperparameters, grid search enables data scientists and machinelearning practitioners to significantly enhance the performance of their algorithms. What are hyperparameters?
This research proposes a novel framework for enhancing heart disease prediction using a hybrid approach that integrates classical and quantum-inspired machinelearning techniques. A Support Vector Machine (SVM) classifier has been used in both classical and quantum domains.
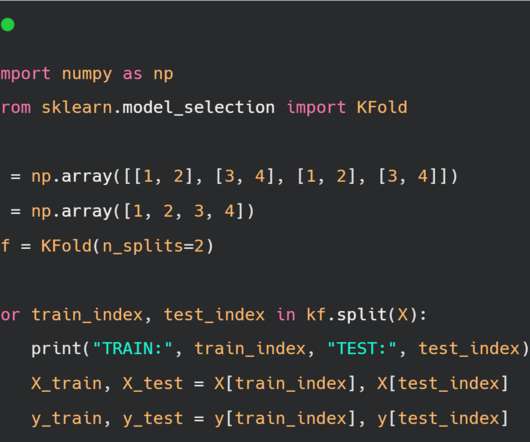
Cross-validation is an essential technique in machinelearning, designed to assess a model’s predictive performance. By implementing cross-validation, you can reduce the risk of overfitting, where a model performs well on training data but poorly on test data. What is cross-validation?
Holdout data plays a pivotal role in the world of machinelearning, serving as a crucial tool for assessing how well a model can apply learned insights to unseen data. Understanding holdout data is essential for anyone involved in creating and validatingmachinelearning models. What is holdout data?
In today’s data-driven world, machinelearning fuels creativity across industries-from healthcare and finance to e-commerce and entertainment. For many fulfilling roles in data science and analytics, understanding the core machinelearning algorithms can be a bit daunting with no examples to rely on.
Summary: Accuracy in MachineLearning measures correct predictions but can be deceptive, particularly with imbalanced or multilabel data. Introduction When you work with MachineLearning , accuracy is the easiest way to measure success. Key Takeaways: Accuracy in MachineLearning is a widely used metric.
Since landmines are not used randomly but under war logic , MachineLearning can potentially help with these surveys by analyzing historical events and their correlation to relevant features. Validation results in Colombia. Each entry is the mean (std) performance on validation folds following the block cross-validation rule.
Summary: MachineLearning’s key features include automation, which reduces human involvement, and scalability, which handles massive data. Introduction: The Reality of MachineLearning Consider a healthcare organisation that implemented a MachineLearning model to predict patient outcomes based on historical data.
The bias-variance tradeoff is essential in machinelearning, impacting how accurately models predict outcomes. Each machinelearning model faces the challenge of effectively capturing data patterns while avoiding errors that stem from both bias and variance. What is bias-variance tradeoff? What is underfitting?
We apply Discrete Wavelet Transform (DWT) for feature extraction and evaluate CSNN performance on the Physionet EEG dataset, benchmarking it against traditional deep learning and machinelearning methods. Notably, this F1-score represents an improvement over previous benchmarks, highlighting the effectiveness of our approach.
Validation set plays a pivotal role in the model training process for machinelearning. It serves as a safeguard, ensuring that models not only learn from the data they are trained on but are also able to generalize effectively to unseen examples. What is a validation set? What is a validation set?
Over time, the relevance of GIGO has evolved, finding application not just in computing but also in data science, machinelearning, and even social sciences. Machinelearning failures In machinelearning, using inaccurate training data can severely distort model predictions.
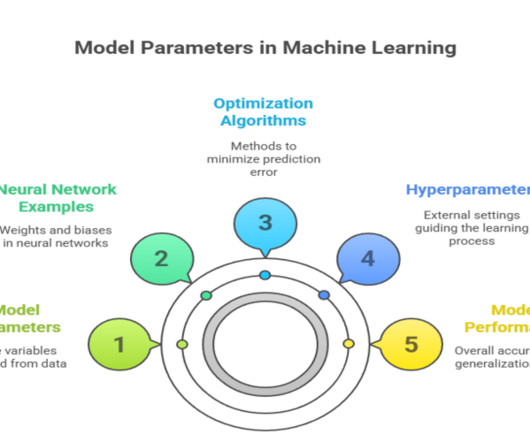
Summary: Model parameters are the internal variables learned from data that define how machinelearning models make predictions. Proper initialization and optimization of parameters are crucial for model accuracy, generalization, and efficient learning in AI applications. What Are Model Parameters?
The prototype model in machinelearning is an essential approach that empowers data scientists to develop and refine machinelearning models efficiently. What is the prototype model in machinelearning? What is model prototyping? Emphasizing continuous improvement is vital.
Hyperparameter autotuning intelligently optimizes machinelearning model performance by automatically testing parameter combinations, balancing accuracy and generalizability, as demonstrated in a real-world particle physics use case.
In this study, three machinelearning approaches, extreme gradient boosting (XGBoost), random forest (RF), and M5P, were used for constructing the prediction model for the impact of elevated temperatures on the compressive strength of concrete modified by marble and granite construction waste powders as partial cement replacements in concrete.
To determine the best parameter values, we conducted a grid search with 10-fold cross-validation, using the F1 multi-class score as the evaluation metric. For the classifier, we employ SVM, using the scikit-learn Python module. Diego Martn Montoro is an AI Expert and MachineLearning Engineer at Applus+ Idiada Datalab.
Why is RMSE important in machinelearning? In the realm of machinelearning, RMSE serves a crucial role in assessing the effectiveness of predictive algorithms. Cross-validation: Use techniques like k-fold cross-validation to assess model robustness and prevent overfitting.
Introduction The Gaussian Mixture Model (GMM) stands as one of the most powerful and flexible tools in the field of unsupervised MachineLearning and statistics. Widely used in image segmentation, speech recognition, and anomaly detection, GMM is essential for complex Data Analysis.
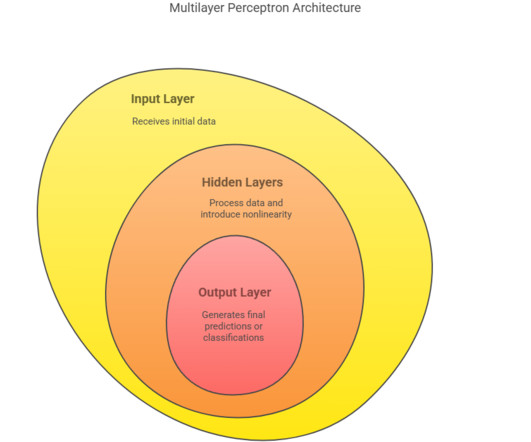
Summary: Multilayer Perceptron in machinelearning (MLP) is a powerful neural network model used for solving complex problems through multiple layers of neurons and nonlinear activation functions. The optimal architecture often requires experimentation and cross-validation.
By leveraging statistical techniques and machinelearning, organizations can forecast future trends based on historical data. Through various statistical methods and machinelearning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
Photo by Agence Olloweb on Unsplash Machinelearning model selection has always been a challenge. Traditionally, we rely on cross-validation to test multiple models XGBoost, LGBM, Random Forest, etc. Upgrade to access all of Medium.
Model selection in machinelearning is a pivotal aspect that shapes the trajectory of AI projects. What is model selection in machinelearning? Importance of model selection Effective model selection is crucial in the machinelearning lifecycle for several reasons.
Model calibration is a crucial aspect of machinelearning that ensures models not only make accurate predictions but also provide probabilities that reflect the likelihood of those predictions being correct. Understanding when to apply calibration can significantly enhance the effectiveness of machinelearning applications.
Then, a logistic regression model trained based on the activities of these gene sets demonstrated superior predictive performance (AUROC = 0.778) in ten-fold cross-validation, significantly outperforming 13 existing biomarkers, including PD-1 (AUROC = 0.678) and PD-L1 (AUROC = 0.54).
Ground truth is a fundamental concept in machinelearning, representing the accurate, labeled data that serves as a crucial reference point for training and validating predictive models. What is ground truth in machinelearning?
Model behavior in machinelearning is a multifaceted concept that encapsulates how predictive models make decisions based on the data they process. Understanding model behavior not only sharpens our grasp of machinelearning systems but also illuminates the challenges and opportunities tied to predictive accuracy.
Using SAS Viya Workbench for efficient setup and execution, this beginner-friendly guide shows how Scikit-learn pipelines can streamline machinelearning workflows and prevent common errors. The post Python ML pipelines with Scikit-learn: A beginners guide appeared first on SAS Blogs.
Welcome back to another exciting journey through the MachineLearning landscape! In our MachineLearning journey, we often fixate on metrics like accuracy, precision, and recall. Remember, in the world of machinelearning, understanding uncertainty is just as important as making accurate predictions.
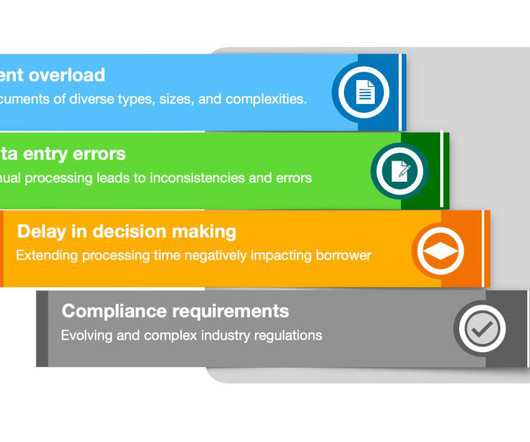
For example, a single mortgage application might require manual review and cross-validation of hundreds of pages of tax returns, pay stubs, bank statements, and legal documents, consuming significant time and resources. Let us know what you think in the comments section, or use the issues forum in the repository.
Generalizing things is easy for us humans, however, it can be challenging for MachineLearning models. This is where Cross-Validation comes into the picture.
This exploration delves into the essential aspects of ML model parameters and associated concepts, revealing their role in effective machinelearning. They determine how well the model learns from input features and make predictions. Datasets and cross-validation A thorough evaluation process involves distinct subsets of data.
We attempt to train our data set using various forms of MachineLearning models, either supervised or unsupervised, depending on the Business Problem. The post Different Types of Cross-Validations in MachineLearning appeared first on Analytics Vidhya. Given many models available for […].
Test sets play an essential role in machinelearning, serving as the benchmark for evaluating how well a model can perform on new, unseen data. Understanding the intricacies of different datasets, including training and validation datasets, is key for any practitioner aiming to develop robust machinelearning models.
In the model-building phase of any supervised machinelearning project, we train a model with the aim to learn the optimal values for all the weights and biases from labeled examples. The post Top 7 Cross-Validation Techniques with Python Code appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon I started learningmachinelearning recently and I think cross-validation is. The post “I GOT YOUR BACK” – Crossvalidation to Models. appeared first on Analytics Vidhya.
Introduction Cross-validation is a machinelearning technique that evaluates a model’s performance on a new dataset. This prevents overfitting by encouraging the model to learn underlying trends associated with the data.
Introduction Before explaining nested cross-validation, let’s start with the basics. The post A step by step guide to Nested Cross-Validation appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Model Building in MachineLearning is an important component of. The post Importance of CrossValidation: Are Evaluation Metrics enough? appeared first on Analytics Vidhya.
The post K-Fold CrossValidation Technique and its Essentials appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Image designed by the author Introduction Guys! Before getting started, just […].
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content