This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
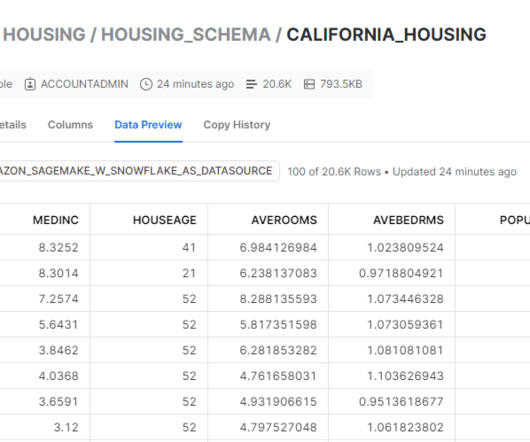
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
You can now use state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
Pietro Jeng on Unsplash MLOps is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently. Thus, MLOps is the intersection of Machine Learning, DevOps, and Data Engineering (Figure 1). There is no central store to manage models (versions and stage transitions).
Common mistakes and misconceptions about learning AI/ML Markus Spiske on Unsplash A common misconception of beginners is that they can learn AI/ML from a few tutorials that implement the latest algorithms, so I thought I would share some notes and advice on learning AI. Trying to code ML algorithms from scratch.
aws sagemaker create-cluster --cli-input-json file://cluster-config.json --region $AWS_REGION You should be able to see your cluster by navigating to SageMaker Hyperpod in the AWS Management Console and see a cluster named ml-cluster listed. After a few minutes, its status should change from Creating to InService.
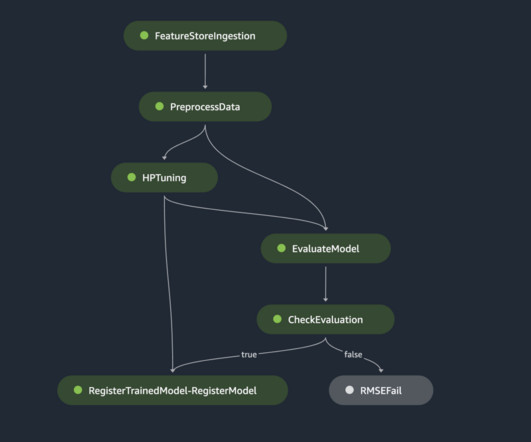
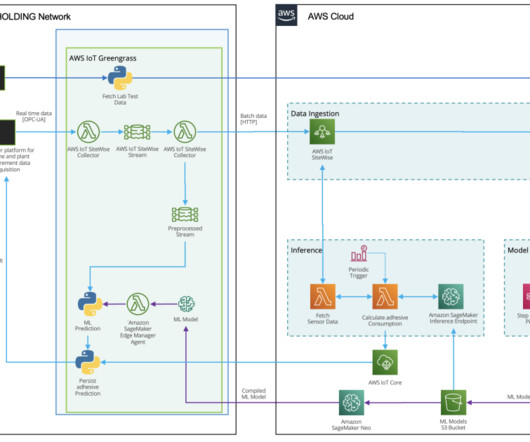
there is enormous potential to use machine learning (ML) for quality prediction. ML-based predictive quality in HAYAT HOLDING HAYAT is the world’s fourth-largest branded baby diapers manufacturer and the largest paper tissue manufacturer of the EMEA. After the datapreparation phase, a two-stage approach is used to build the ML models.
Machine learning (ML) models do not operate in isolation. To deliver value, they must integrate into existing production systems and infrastructure, which necessitates considering the entire ML lifecycle during design and development. GitHub serves as a centralized location to store, version, and manage your ML code base.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Going into developing machine learning models with a hands-on, data-centric AI approach has its benefits and requires a few extra steps to achieve. Learn more here.
In fact, AI/ML graduate textbooks do not provide a clear and consistent description of the AI software engineering process. Therefore, I thought it would be helpful to give a complete description of the AI engineering process or AI Process, which is described in most AI/ML textbooks [5][6]. 85% or more of AI projects fail [1][2].
The machine learning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses.
Only involving necessary people to do case validation or augmentation tasks reduces the risk of document mishandling and human error when dealing with sensitive data. About the Authors Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS).
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
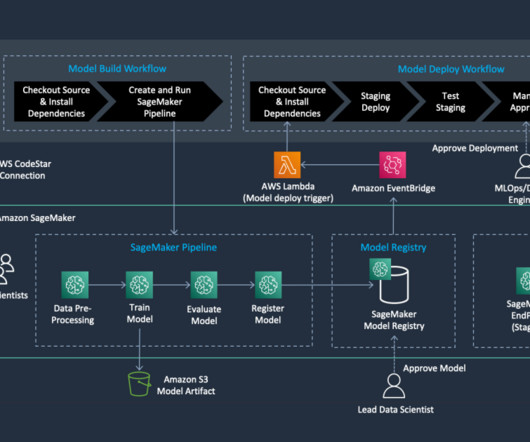
MLOps is a key discipline that often oversees the path to productionizing machine learning (ML) models. MLOps tooling helps you repeatably and reliably build and simplify these processes into a workflow that is tailored for ML. This capability leads to significant time and computational resource savings.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
input_ids return batch #apply the datapreparation function to all of our fine-tuning dataset samples using dataset's.map method. His current areas of focus are AI/ML infrastructure and applications. Dr. Changsha Ma is an AI/ML Specialist at AWS.
Some of the models offer capabilities for you to fine-tune them with your own data. SageMaker JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for machine learning (ML) with SageMaker. Mia Chang is an ML Specialist Solutions Architect for Amazon Web Services.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
It provides a collection of pre-trained models that you can deploy quickly and with ease, accelerating the development and deployment of machine learning (ML) applications. Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on.
Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
Established in 1987 at the University of California, Irvine, it has become a global go-to resource for ML practitioners and researchers. The UCI Machine Learning Repository is a well-known online resource that houses vast Machine Learning (ML) research and applications datasets. The global Machine Learning market continues to expand.
It combines various techniques from statistics, mathematics, computerscience, and domain expertise to interpret complex data sets. AI encompasses various subfields, including Machine Learning (ML), Natural Language Processing (NLP), robotics, and computer vision.
However, another motivation was a personal reflection on a field that did not yet exist a little over a decade ago when I first began my advanced studies in computerscience. Moreover, the work carried out by data scientists is distinct from other types of data analysis, because it requires a wider breadth of multidisciplinary skills.
However, another motivation was a personal reflection on a field that did not yet exist a little over a decade ago when I first began my advanced studies in computerscience. Moreover, the work carried out by data scientists is distinct from other types of data analysis, because it requires a wider breadth of multidisciplinary skills.
About the Authors Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. Ram Vegiraju is an ML Architect with the Amazon SageMaker Service team. In his spare time, he loves traveling and writing.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about datascience and Bayesian statistics. in computerscience from the University of California, Berkeley; and Bachelors and Masters degrees fromMIT.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










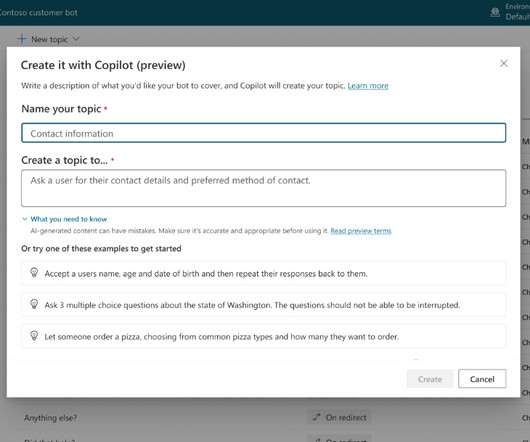



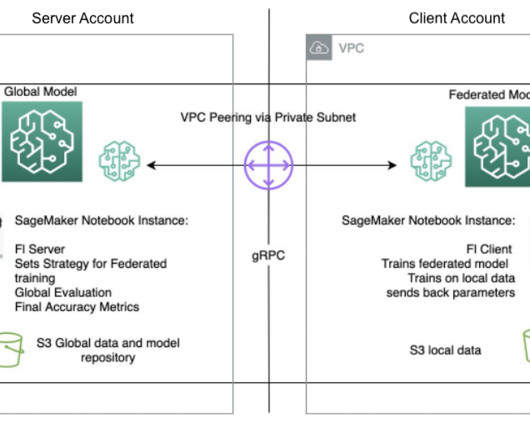
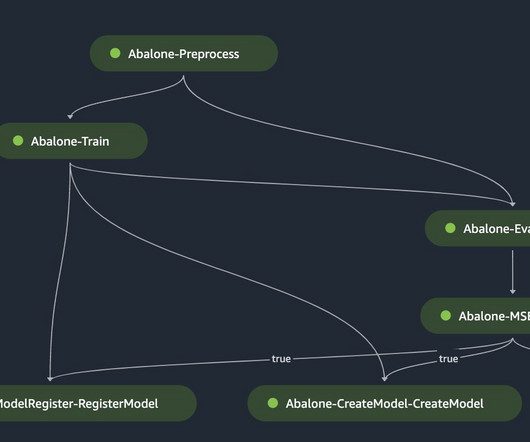


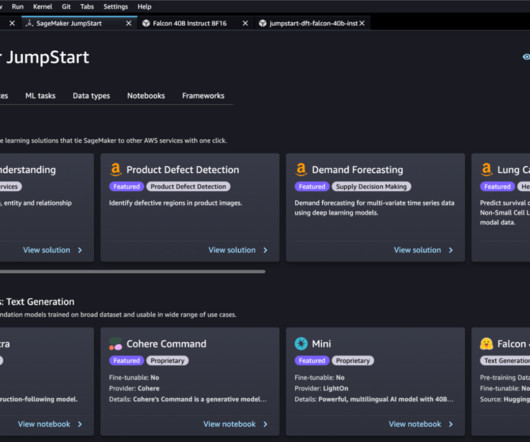












Let's personalize your content