This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
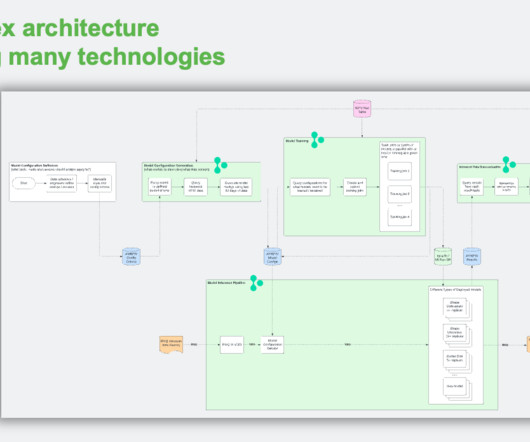
Cluster Setup Crusoe graciously lent us a cluster of 300 L40S GPUs. torchft can have many, many hosts in each replica group, but for this cluster, a single host/10 gpus per replica group had the best performance due to limited network bandwidth. Register now! The GPUs were split up across 30 hosts, each with 10 NVIDIA L40S GPUs.
Upcoming Webinars: How to build stunning Data Science Web applications in Python Thu, Feb 23, 2023, 12:00 PM — 1:00 PM EST This webinar presents Taipy, a new low-code Python package that allows you to create complete Data Science applications, including graphical visualization and the management of algorithms, models, and pipelines.
You can chat with your structured data by setting up structured data ingestion from AWS Glue Data Catalog tables and Amazon Redshift clusters in a few steps, using the power of Amazon Bedrock Knowledge Bases structured data retrieval. Use the data ingestion notebook to create a Redshift Serverless namespace and workgroup in the default VPC.
Visualization for Clustering Methods Clustering methods are a big part of data science, and here’s a primer on how you can visualize them. Professor Mark A. Lemley on Generative AI and the Law Here’s what Mark A.
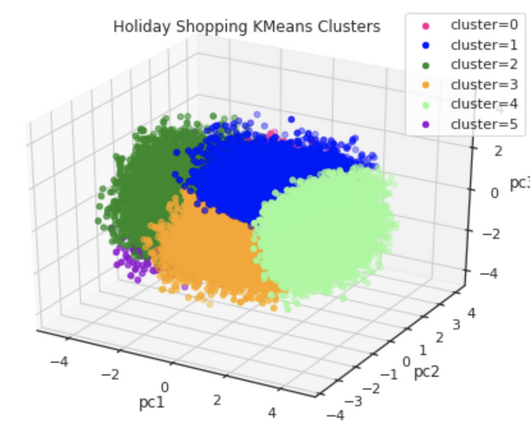
All of these techniques center around product clustering, where product lines or SKUs that are “closer” or more similar to each other are clustered and modeled together. Clustering by product group. The most intuitive way of clustering SKUs is by their product group. Clustering by sales profile.
You can hear more details in the webinar this article is based on, straight from Kaegan Casey, AI/ML Solutions Architect at Seagate. from local or virtual machine to K8s cluster) and the need for bespoke deployments. from local or virtual machine to K8s cluster) and the need for bespoke deployments.
During a recent ODSC webinar , Sean Tracey, Head of Developer Relations at Expanso, presented a compelling vision for running large language models (LLMs) securely, efficiently, and locally. Olama abstracts model complexity and provides a clean API for interaction.
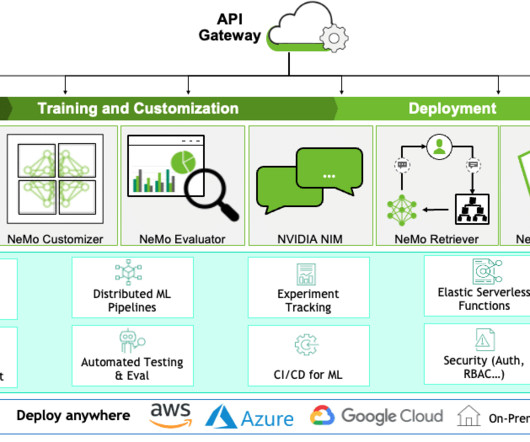
The blog is based on the webinar Deploying Gen AI in Production with NVIDIA NIM & MLRun with Amit Bleiweiss, Senior Data Scientist at NVIDIA, and Yaron Haviv, co-founder and CTO and Guy Lecker, ML Engineering Team Lead at Iguazio (acquired by McKinsey). You can watch the entire webinar here.
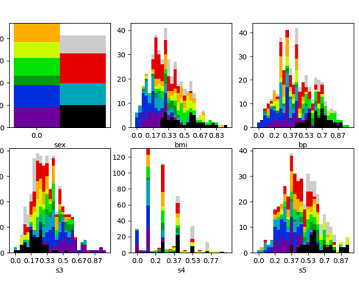
Evaluating Clustering in Machine Learning In this article, we’ll examine two renowned clustering evaluation methods: the Silhouette score and Density-Based Clustering Validation (DBCV). We’ll dive into their strengths, limitations, and ideal scenarios of use. We now have a podcast!
At a recent webinar hosted by Stefan Webb, Developer Advocate and champion of Milvus (an open-source vector database), he walked a global audience through the what, why, and how of building multimodal RAG systems. By mapping content to a high-dimensional space, related pieces cluster together.
Watch our Webinar Why Spatial Data Governance is Critical to Your Business Strategy Govern your spatial data with a strong data governance strategy. To learn more about the benefits of spatial data governance, watch our webinar featuring a demo titled Why spatial data governance is critical to your business strategy.
SIGN-UP FOR THE WEBINAR Bring clarity to geospatial link analysis Connections are at the heart of many geospatial intelligence investigations. You can also join our live webinar on March 26, 2025 to explore MapWeave’s powerful geospatial visualization capabilities, see live demos and learn how you can get involved.
Adding to the complexity, the USPS is encouraging use of Cluster Box Units to improve their efficiency adding another element to manage in home delivery. Learn more in our webinar, Unlock Efficiency With Your Address Data Today For a Smarter Tomorrow.
Join our webinar to explore more Furthermore, users can analyze the impact of executing Turbo actions on the underlying entity KPIs. Watch our new release webinar to learn more about this update. We extended our coverage and currently, Instana supports SAP BTP Kyma cluster monitoring. Learn more in our announcement blog.
Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms. Additionally, attending webinars and local meetups can significantly expand your knowledge and connections. Webinars often feature industry experts who share practical insights and experiences.
In a recent 30-minute webinar entitled, “Keeping Pace with Ongoing PFAS Developments,” Jack Sheldon, PFAS Service Line Leader, and Nasim Pica and Jason Lagowski, PFAS Subject Matter Experts at Antea Group, distilled down some of the most pressing updates on PFAS, from regulatory shifts to the latest forensic technologies.
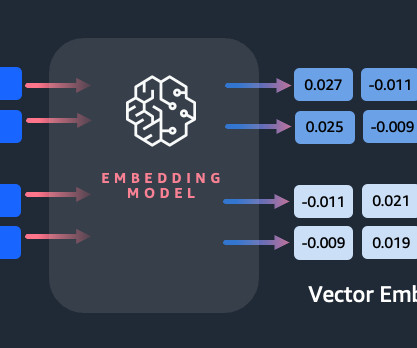
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
This data consists of 60+ hours of human labeled audio data, covering popular speech domains such as call centers, podcasts, broadcasts, and webinars. Building on In-House Hardware Conformer-2 was trained on our own GPU compute cluster of 80GB-A100s. As evidenced by the figure, we were able to observe a 6.8%
If combined with Apache Kafka’s high availability and streamlined data collection—enabling applications or other processing tools to spot patterns and trends—businesses would immediately be able to harness the MQ data along with other streams of events from Kafka clusters to develop real-time intelligent solutions.
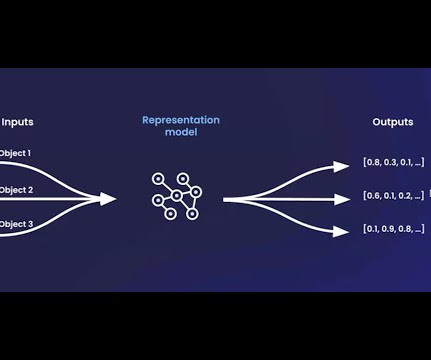
These models enable classification, clustering, similarity calculations, information retrieval, and other tasks. It facilitates methods such as embedding and clustering techniques to determine similar or dissimilar points. Look at our events page to sign up for research webinars, product overviews, and case studies.
Unsupervised Learning: Evaluating Clusters 25 Excellent Machine Learning OpenDatasets Want to become the next writer to get thousands of views on an article? We hold 35 webinars per year on average and host 15+ meetups in cities like Boston, NYC, DC, Seattle, and London. Learn more about contributing here !
They provide a rich view that incorporates boundaries, distance, and clusters of data points to unlock location-based insights that can inform decision-making across your organization. Learn more in our webinar, MapInfo Pro v2023: The Next Dimension in Spatial Analytics.
Join our webinar to explore more Furthermore, users can analyze the impact of executing Turbo actions on the underlying entity KPIs. Watch our new release webinar to learn more about this update. We extended our coverage and currently, Instana supports SAP BTP Kyma cluster monitoring. Learn more in our announcement blog.
Cassandra’s architecture is based on a peer-to-peer model where all nodes in the cluster are equal. Partition Key: Determines how data is distributed across nodes in the cluster. Its linear scalability means that as additional nodes are added to the cluster, overall performance improves proportionally.
Botnets Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Read more to learn about the data flow, the challenges, and the way we get successful results of botnet detection. Here’s how.
“Have educational gamification plus exercises for folks in lower management, with performance indicators tied to improving the health of the data, or find ways of actually increasing literacy without having to watch another compliance webinar.”. Don’t talk about regression and anomalies and clustering and data science,” he argues.
This is but one of the many benefits for application developers already using Kafka, as it enables easy security mechanisms across topics on multiple clusters, self-onboarding for access to topics and reduced disruption during Kafka administration—all at the Kafka protocol level to transparently apply enforcement policies.
Key techniques in unsupervised learning include: Clustering (K-means) K-means is a clustering algorithm that groups data points into clusters based on their similarities. Participating in the ML Community Attending conferences, joining webinars, and reading research papers provide valuable insights into emerging trends.
This includes supervised learning techniques like linear regression and unsupervised learning methods like clustering. Engage in Continuous Learning Stay updated with industry trends through online courses, webinars, and workshops. Machine Learning Understanding Machine Learning algorithms is essential for predictive analytics.
It contains data clustering, classification, anomaly detection and time-series forecasting. Additionally, you should attend conferences and events like webinars and learn from your peers and experts. Furthermore, adopting new tools and technologies helps deliver a highly effective user experience.
Learn about supervised and unsupervised learning, regression, classification, clustering, and evaluation metrics. Follow industry blogs, attend conferences, and participate in online courses or webinars to expand your knowledge and skills. Explore popular machine learning libraries like sci-kit-learn and TensorFlow.
Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. I regularly participate in online courses, webinars, and conferences related to data analytics. You’re tasked with predicting sales for a retail store.
Focus is a struggle at every startup, but I’ve found it particularly hard at companies where you have a disruptive, highly differentiated, or next-generation product, rather than one that is tightly clustered with similar competitors. Sometimes it feels like the ratio of things we’d like to invest in to those we have time for is 100 to one.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content