This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Semi-supervisedlearning is reshaping the landscape of machine learning by bridging the gap between supervised and unsupervised methods. With vast amounts of unlabeled data available in various domains, semi-supervisedlearning proves to be an invaluable tool in tackling complex classification tasks.
In machine learning, few ideas have managed to unify complexity the way the periodic table once did for chemistry. Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. Each guest (data point) finds a seat (cluster) ideally near friends (similar data).
Supervisedlearning is a powerful approach within the expansive field of machine learning that relies on labeled data to teach algorithms how to make predictions. What is supervisedlearning? Supervisedlearning refers to a subset of machine learning techniques where algorithms learn from labeled datasets.
Clustering in machine learning is a fascinating method that groups similar data points together. By organizing data into meaningful clusters, businesses and researchers can gain valuable insights into their data, facilitating decision-making across various domains. What is clustering in machine learning?
Self-supervisedlearning (SSL) is a powerful tool in machine learning, but understanding the learned representations and their underlying mechanisms remains a challenge. This clustering process not only enhances downstream classification but also compresses the data information.
The mechanisms behind the success of multi-view self-supervisedlearning (MVSSL) are not yet fully understood. Contrastive MVSSL methods have been studied though the lens of InfoNCE, a lower bound of the Mutual Information (MI). However, the relation between other MVSSL methods and MI remains unclear. We also re-interpret the…
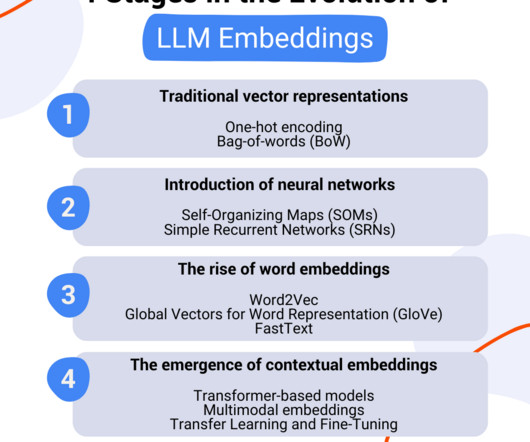
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
By allowing algorithms to learn autonomously, it opens the door to various innovative applications across different fields. From organizing vast datasets to finding similarities among complex information, unsupervised learning plays a pivotal role in enhancing decision-making processes and operational efficiencies.
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
The world of multi-view self-supervisedlearning (SSL) can be loosely grouped into four families of methods: contrastive learning, clustering, distillation/momentum, and redundancy reduction. This work not only brings new theoretical insights but also introduces practical tools to optimize self-supervised models.
Types of Machine Learning Algorithms Machine Learning has become an integral part of modern technology, enabling systems to learn from data and improve over time without explicit programming. The goal is to learn a mapping from inputs to outputs, allowing the model to make predictions on unseen data.
Let’s dig into some of the most asked interview questions from AI Scientists with best possible answers Core AI Concepts Explain the difference between supervised, unsupervised, and reinforcement learning. The model learns to map input features to output labels. .”
Therefore, SupervisedLearning vs Unsupervised Learning is part of Machine Learning. Let’s learn more about supervised and Unsupervised Learning and evaluate their differences. What is SupervisedLearning? What is Unsupervised Learning?
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights.
With the use of machine learning, people find out about the 2 main types of machine learning: Supervised and Unsupervised learning. SupervisedLearning First, what exactly is supervisedlearning? It is the most common type of machine learning that you will use. Let’s get right into it.
In this article, I’ll guide you through your first training session on a Machine Learning Algorithm: we’ll be training… pub.towardsai.net Classification and Regression fall under SupervisedLearning, a category in Machine Learning where we have prior knowledge of the target variable.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
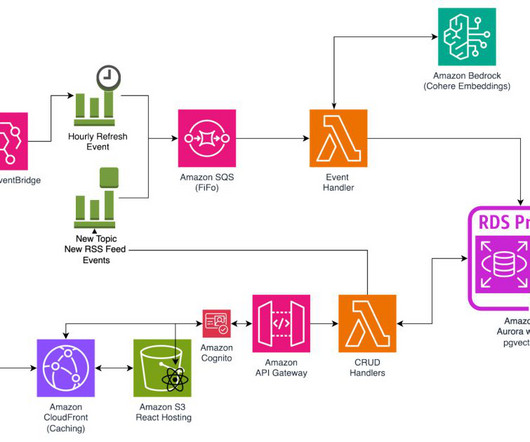
The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning. You can then say that if an article is clustered closely to one of these embeddings, it can be classified with the associated topic. We can then use pgvector to find articles that are clustered together.
The classification model learns from the training data, identifying the distinguishing characteristics between each class, enabling it to make informed predictions. Classification in machine learning can be a versatile tool with numerous applications across various industries.
NOTES, DEEP LEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISEDLEARNING A note of the paper I have read Photo by Kelly Sikkema on Unsplash Hi everyone, In today’s story, I would share notes I took from 32 pages of Wang et al., Taxonomy of the self-supervisedlearning Wang et al. 2022’s paper.
It has significantly impacted industries like finance, healthcare, and transportation by analysing data, making predictions, and automating decisions Predictive Modelling Machine Learning algorithms excel at predictive modelling, which involves using historical data to create models that forecast future events. predicting house prices).
Deep learning is transforming the landscape of artificial intelligence (AI) by mimicking the way humans learn and interpret complex data. It allows machines to analyze vast amounts of information, which can lead to incredible innovations across various industries. This makes deep learning more adaptable to complex datasets.
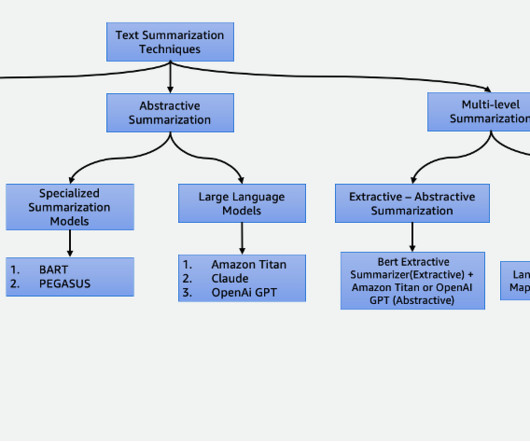
Summarization is the technique of condensing sizable information into a compact and meaningful form, and stands as a cornerstone of efficient communication in our information-rich age. In a world full of data, summarizing long texts into brief summaries saves time and helps make informed decisions.
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
In the world of data science, few events garner as much attention and excitement as the annual Neural Information Processing Systems (NeurIPS) conference. 2023’s event, held in New Orleans in December, was no exception, showcasing groundbreaking research from around the globe.
This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data. Types of Machine Learning for GIS 1. Supervisedlearning– In supervisedlearning, the input data and associated output labels are paired, letting the system be trained on labelled data.
We’re educating the computer to learn from data (the equivalent of practice), to make informed predictions (akin to riding the bicycle), and to progressively improve with each iteration. In the context of Machine Learning, data can be anything from images, text, numbers, to anything else that the computer can process and learn from.
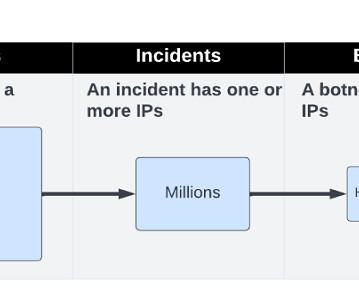
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
Better Decision Making Valuable insights into user behavior and preferences with adaptive AI can inform strategic decision-making. Some key characteristics that make AI adaptive are: Ability to Learn Continuously The AI system can process and analyze new information.
Building disruptive Computer Vision applications with No Fine-Tuning Imagine a world where computer vision models could learn from any set of images without relying on labels or fine-tuning. Understanding DINOv2 DINOv2 is a cutting-edge method for training computer vision models using self-supervisedlearning.
There are various types of machine learning algorithms, including supervisedlearning, unsupervised learning, and reinforcement learning. In supervisedlearning, the model learns from labeled examples, where the input data is paired with corresponding target labels.
On the other hand, artificial intelligence is the simulation of human intelligence in machines that are programmed to think and learn like humans. By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informed decisions and take autonomous actions.
Unsupervised Learning is a Machine Learning technique where the users do not require to supervise the model. Significantly, the technique allows the model to work independently by discovering its patterns and previously undetected information. Therefore, it mainly deals with unlabelled data.
Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. It is among the most widely used and straightforward regression and classification classifiers in machine learning today.
Summary: Entropy in Machine Learning quantifies uncertainty, driving better decision-making in algorithms. It optimises decision trees, probabilistic models, clustering, and reinforcement learning. This concept, pivotal in understanding data structures and communication systems, plays a significant role in Machine Learning.
Once you’re past prototyping and want to deliver the best system you can, supervisedlearning will often give you better efficiency, accuracy and reliability than in-context learning for non-generative tasks — tasks where there is a specific right answer that you want the model to find. That’s not a path to improvement.
The answer lies in the various types of Machine Learning, each with its unique approach and application. In this blog, we will explore the four primary types of Machine Learning: SupervisedLearning, UnSupervised Learning, semi-SupervisedLearning, and Reinforcement Learning.
Types of Machine Learning There are three main categories of Machine Learning, Supervisedlearning, Unsupervised learning, and Reinforcement learning. Supervisedlearning: This involves learning from labeled data, where each data point has a known outcome. Models […]
Basically, Machine learning is a part of the Artificial intelligence field, which is mainly defined as a technic that gives the possibility to predict the future based on a massive amount of past known or unknown data. ML algorithms can be broadly divided into supervisedlearning , unsupervised learning , and reinforcement learning.
A definition from the book ‘Data Mining: Practical Machine Learning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Clustering. Classification. Regression.
We’re excited to announce that many CDS faculty, researchers, and students will present at the upcoming thirty-seventh 2023 NeurIPS (Neural Information Processing Systems) Conference , taking place Sunday, December 10 through Saturday, December 16. The conference will take place in-person at the New Orleans Ernest N.
A sector that is currently being influenced by machine learning is the geospatial sector, through well-crafted algorithms that improve data analysis through mapping techniques such as image classification, object detection, spatial clustering, and predictive modeling, revolutionizing how we understand and interact with geographic information.
Azure ML SDK : For those who prefer a code-first approach, the Azure Machine Learning Python SDK allows data scientists to work in familiar environments like Jupyter notebooks while leveraging Azure’s capabilities. Check out the Python SDK reference for detailed information. Awesome, right?
This technology allows computers to learn from historical data, identify patterns, and make data-driven decisions without explicit programming. Based on the values of inputs or independent variables, these algorithms can make predictions about the dependent variable or classify output for the new input data based on this learnedinformation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content