
How to Migrate Hive Tables From Hadoop Environment to Snowflake Using Spark Job
phData
APRIL 26, 2024
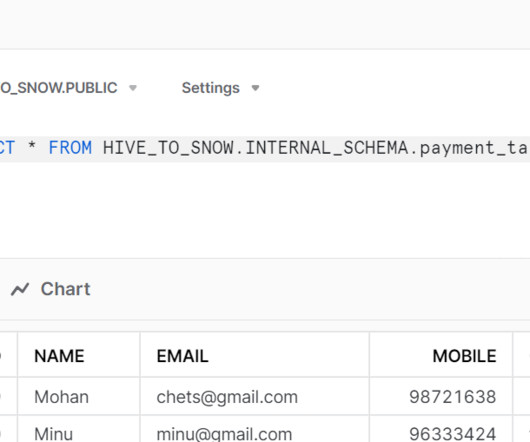
One common scenario that we’ve helped many clients with involves migrating data from Hive tables in a Hadoop environment to the Snowflake Data Cloud. Create a Dataproc Cluster: Click on Navigation Menu > Dataproc > Clusters. Click Create Cluster. Click Create to initiate the Dataproc cluster creation.
























Let's personalize your content