This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
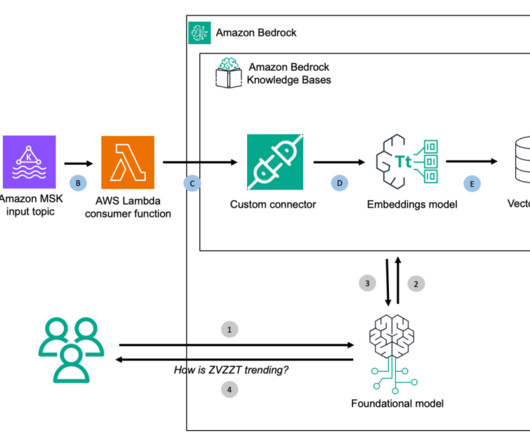
Think of the examples of clickstream data, credit card swipes, Internet of Things (IoT) sensor data, log analysis and commodity priceswhere both current data and historical trends are important to make a learned decision. In this step, you follow the detailed instructions that are mentioned at Create a topic in the Amazon MSK cluster.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
To meet the demands of modern-day transactions, relational databases also had to incorporate additional functionality such as clustering and sharding to enable global distribution and infinite scaling, utilizing the more cost-effective cloud storage available.
Moreover, the cluster can be rebalanced based on disk usage, such that large schemas automatically get more resources dedicated to them, while small schemas are efficiently packed together. The MERGE will re-partition the data across the cluster on the fly, in one parallel, distributed transaction. metric = alerts. alert_id , m.
A trusted leader in AI, Internet of Things (IoT), customer experience, and network and workflow management, CCC delivers innovations that keep people’s lives moving forward when it matters most. The Lambda will download these previous predictions from Amazon S3.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content