This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
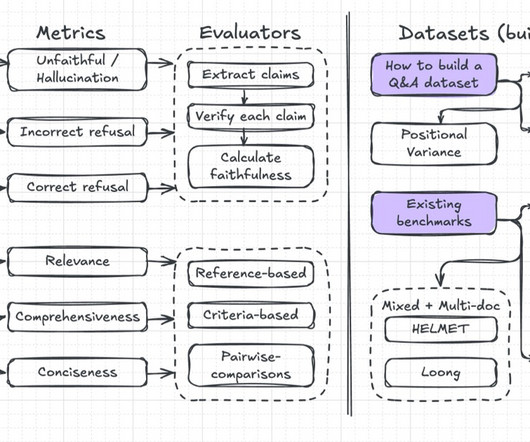
Open-ended questions: Queries on broad themes or interpretative topics rarely have a single definitive answer, especially for large documents or corpora. Definitions: These assess a model’s ability to explain domain-specific content based on the document. or “What is the legal clause mentioned in Section 2.1?”
The SageMaker Python SDK provides the ScriptProcessor class, which you can use to run your custom processing script in a SageMaker processing step. SageMaker provides the PySparkProcessor class within the SageMaker Python SDK for running Spark jobs. slim-buster RUN pip3 install pandas==0.25.3 scikit-learn==0.21.3
Ray is an open source framework that makes it straightforward to create, deploy, and optimize distributed Python jobs. At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray clusters and Kubernetes clusters pair well together.
These services support single GPU to HyperPods (cluster of GPUs) for training and include built-in FMOps tools for tracking, debugging, and deployment. Having access to a JupyterLab IDE with Python 3.9, To get started, complete the following steps: Install the latest version of the sagemaker-python-sdk using pip. 3.10, or 3.11
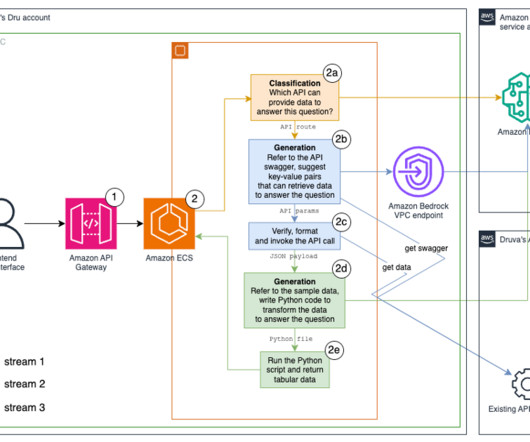
Generate and run data transformation Python code. Stream 3: Generate and run data transformation Python code Next, we took the response from the API call and transformed it to answer the user question. The request arrives at the microservice on our existing Amazon Elastic Container Service (Amazon ECS) cluster.
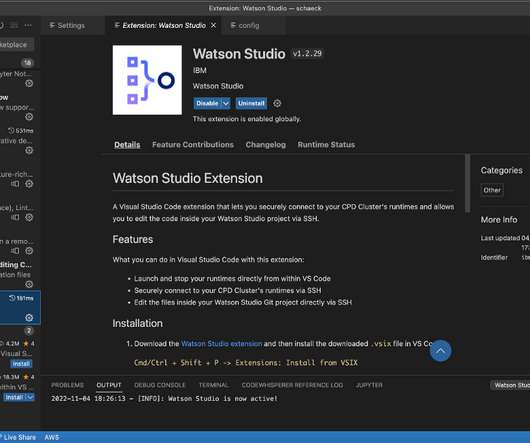
VS Code desktop integration lets data scientists use a familiar IDE to run and debug code that runs on the Cloud Pak for Data cluster. We show how the new Watson Studio extension for VS Code makes it easy to connect to Python runtime environments within Cloud Pak for Data projects. New in Cloud Pak for Data 4.6,
With containers, scaling on a cluster becomes much easier. Solution overview We walk you through the following high-level steps: Provision an ECS cluster of Trn1 instances with AWS CloudFormation. Create a task definition to define an ML training job to be run by Amazon ECS. Run the ML task on Amazon ECS.
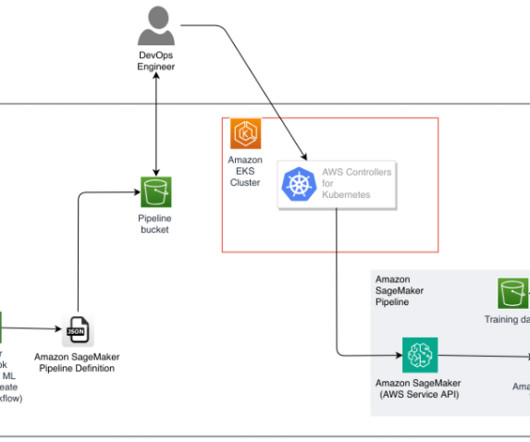
ACK allows you to take advantage of managed model building pipelines without needing to define resources outside of the Kubernetes cluster. This configuration takes the form of a Directed Acyclic Graph (DAG) represented as a JSON pipeline definition. kubectl for working with Kubernetes clusters. yq for YAML processing.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
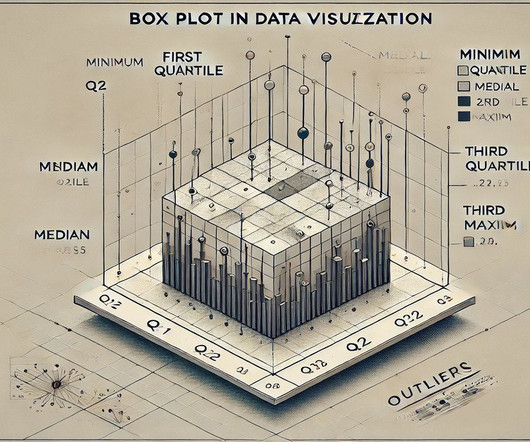
This article will explore the definition of a Box Plot, its essential components, and the formulas used in creating it. Definition of a Box Plot The definition of a Box Plot centres around its ability to show variability in data distribution. Box Plots help detect patterns by showing how data clusters around the median.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
How Clustering Can Help You Understand Your Customers Better Customer segmentation is crucial for businesses to better understand their customers, target marketing efforts, and improve satisfaction. Clustering, a popular machine learning technique, identifies patterns in large datasets to group similar customers and gain insights.
It is very easy for a data scientist to use Python or R and create machine learning models without input from anyone else in the business operation. Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. AIIA MLOps blueprints.
Azure ML SDK : For those who prefer a code-first approach, the Azure Machine Learning Python SDK allows data scientists to work in familiar environments like Jupyter notebooks while leveraging Azure’s capabilities. Check out the Python SDK reference for detailed information. Deep Learning with Python by Francois Chollet.
Tableau Data Types: Definition, Usage, and Examples Tableau has become a game-changer in the world of data visualization. Summary Table: Data Type in Tableau Data Type Definition Example Common Use Case String Textual characters “Customer Name” Categorizing data, adding labels Numerical Numbers (integers & decimals) 123.45
The IDP CDK constructs and samples are a collection of components to enable definition of IDP processes on AWS and published to GitHub. Prerequisites To deploy the samples, you need an AWS account , the AWS Cloud Development Kit (AWS CDK) , a current Python version and Docker are required.
If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
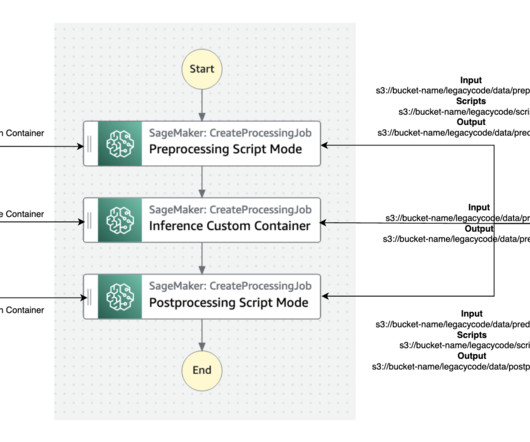
The term legacy code refers to code that was developed to be manually run on a local desktop, and is not built with cloud-ready SDKs such as the AWS SDK for Python (Boto3) or Amazon SageMaker Python SDK. The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK.
Python is one of the widely used programming languages in the world having its own significance and benefits. Its efficacy may allow kids from a young age to learn Python and explore the field of Data Science. Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. It’s a programming model that allows you to create distributed objects that maintain an internal state and can be accessed concurrently by multiple tasks running on different nodes in a Ray cluster.
Definition and significance of data science The significance of data science cannot be overstated. Predictive modeling and machine learning: Familiarity with programming languages like Python, R, and SQL. Statistical methods: Techniques such as classification, regression, and clustering enable data exploration and modeling.
About Rapids The RAPIDS data science framework uses GPU to run end-to-end pipelines and has a Python-like interface. python rapidsai-csp-utils/colab/pip-install.py __version__ Let's try clustering a sample dataset and compare the runtime of clustering functions by running it with CPU and then with GPU. The CPU took 5.15
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code.
Choosing the right method of machine learning deployment is crucial for optimal performance and scalability Alternatively, web services can offer more cost-effective and almost real-time predictions, especially when the model runs on a cluster or cloud service with readily available CPU power.
Memory-safe languages like Java and Python automate allocating and deallocating memory, though there are still ways to work around the languages’ built-in protections. WebAssembly provides a browser-based compilation target for high-level languages ranging from C to Rust (including C++, C#, Python, and Ruby). Well, partly.
So a 2500 core testing cluster is small potatoes!” We have a 2500 core cluster dedicated to running over 75M tests per week so that the hundreds of developers working on these codes can continue to deliver new versions all day long. So a 2500 core testing cluster is small potatoes! Definitely!
You can integrate a Data Wrangler data preparation flow into your machine learning (ML) workflows to simplify data preprocessing and feature engineering, taking data preparation to production faster without the need to author PySpark code, install Apache Spark, or spin up clusters. Choose Python (Pandas). After notebook files (.ipynb)
It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. You can use artifacts to manage configuration, so everything from hyperparameters to cluster sizing can be managed in a single file, tracked alongside the results.
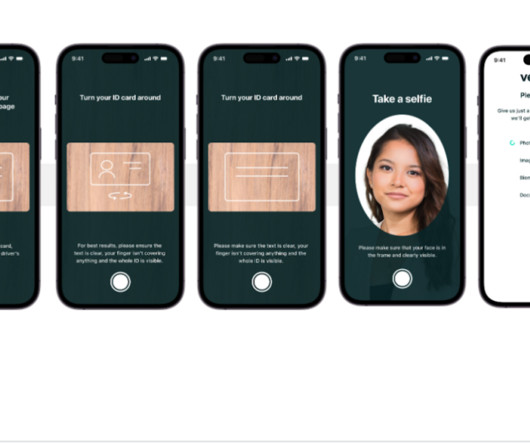
Infrastructure and development challenges Veriff’s backend architecture is based on a microservices pattern, with services running on different Kubernetes clusters hosted on AWS infrastructure. For more information, refer to Managing Python Runtime and Libraries. Also, config files for Python steps need to point to python_env.tar.gz
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. Why: Data Makes It Different.
Let’s explore the specific role and responsibilities of a machine learning engineer: Definition and scope of a machine learning engineer A machine learning engineer is a professional who focuses on designing, developing, and implementing machine learning models and systems.
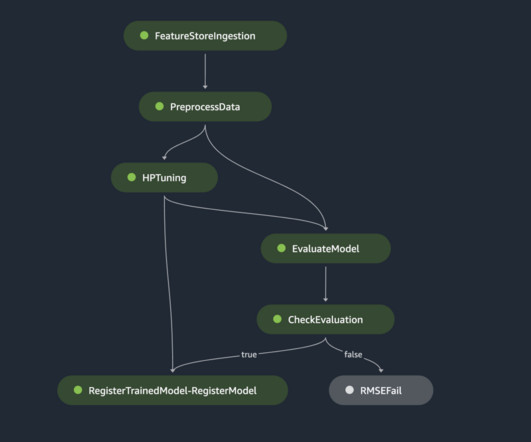
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. The following figure shows schema definition and model which reference it. This can be achieved by enabling the awslogs log driver within the logConfiguration parameters of the task definitions.
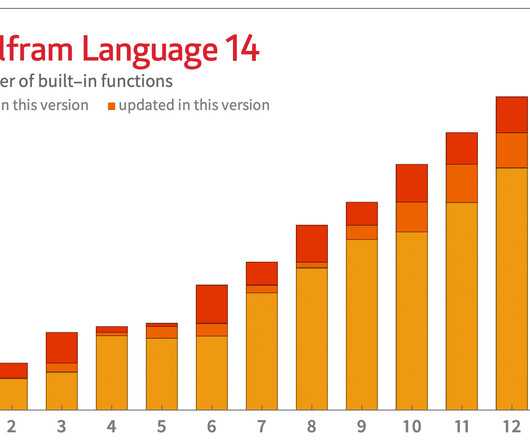
And it wasn’t long before we got to the point—first with indefinite integrals, and later with definite integrals—where what’s now the Wolfram Language could do integrals better than any human. And, yes, one can give a basic definition for this easily enough using ordinary differentiation and equation solving. Let’s start with Python.
This step-function instantiated a cluster of instances to extract and process data from S3 and the further steps of pre-processing, training, evaluation would run on a single large EC2 instance. We could re-use the previous Sagemaker Python SDK code to run the modules individually into Sagemaker Pipeline SDK based runs.
For example, it can scale the data, perform univariate feature selection, conduct PCA at different variance threshold levels, and apply clustering. It comes with a set of functions, which ensure HPO arguments are returned in a format expected when deploying multiple model definitions at once. py"): estimator_name = script.split(".")[0].replace("_",
These are multifaceted problems in which, by definition, certain entities should first be identified. It’s an open-source Python package for Exploratory Data Analysis of text. In that case, we will have an even harder time than before with an LLM. An entire statistical analysis of those entities in the dataset should be carried out.
I realized that the algorithm assumes that we like a particular genre and artist and groups us into these clusters, not letting us discover and experience new music. It gives us this final result: Conclusion The app definitely isn’t perfect. While scrolling through my recommended playlist.
Engineers must manually write custom data preprocessing and aggregation logic in Python or Spark for each use case. For this post, we refer to the following notebook , which demonstrates how to get started with Feature Processor using the SageMaker Python SDK.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. The CUDA platform is used through complier directives and extensions to standard languages, such as the Python cuNumeric library. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
In addition, we’re making it easy to get the most signal out of your data with new Multimodal Clustering , Segmented Modeling , and Multilabel Classification. And we’re not slowing down. platform release. Each of these use cases can be launched without a single line of code!
How to Pivot and Plot Data WithPandas 3 Tips for Using Python Libraries to Create 3D Animation Show Me the Data: 8 Awesome Time SeriesSources Transforming Skewed Data for MachineLearning What is Pruning in Machine Learning? VSCode: Which Is the Better PythonIDE? Were planning for the 10th anniversary of ODSC East to be the biggest one yet.
Problem definition Traditionally, the recommendation service was mainly provided by identifying the relationship between products and providing products that were highly relevant to the product selected by the customer. Make sure to enter the same PyTorch framework, Python version, and other details that you used to train the model.
Using a clustering method, want to determine the greatest number of speakers that could reasonably be heard in the audio. Finally, Speaker Diarization models take the utterance embeddings (produced above), and cluster them into as many clusters as there are speakers. Well, we'll definitely highly promote that.
Thanks to its various operators, it is integrated with Python, Spark, Bash, SQL, and more. Programming language: It offers a simple way to transform Python code into an interactive workflow application. Cloud-agnostic and can run on any Kubernetes cluster. Programming language: Airflow is very versatile. It is lightweight.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content