This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In machinelearning, few ideas have managed to unify complexity the way the periodic table once did for chemistry. Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. Each guest (data point) finds a seat (cluster) ideally near friends (similar data).
Density-based clustering stands out in the realm of data analysis, offering unique capabilities to identify natural groupings within complex datasets. What is density-based clustering? This method effectively distinguishes dense regions from sparse areas, identifying clusters while also recognizing outliers.
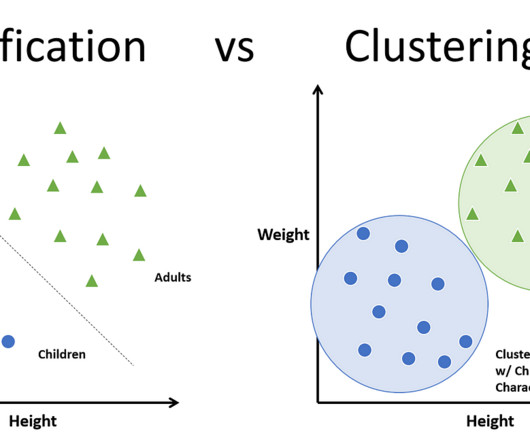
Definitely not. This is where the organization part comes in— by categorizing the brands as a whole or taking a more […] The post Classification vs. Clustering- Which One is Right for Your Data? Introduction Imagine walking into a shopping mall with hundreds of brands and products, all jumbled up and randomly placed in the shops.
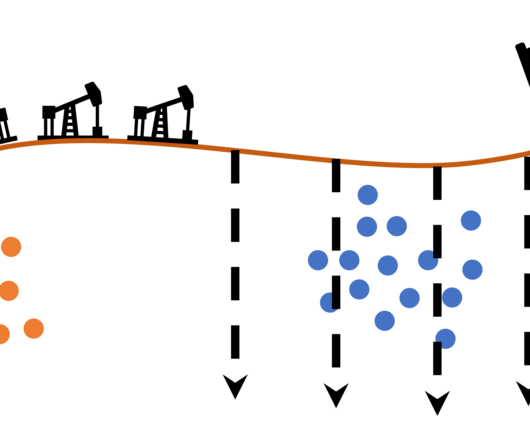
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. The major components of RELand are illustrated in Fig.
Machinelearning deployment is a crucial step in bringing the benefits of data science to real-world applications. With the increasing demand for machinelearning deployment, various tools and platforms have emerged to help data scientists and developers deploy their models quickly and efficiently.
Machinelearning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. What are machinelearning algorithms? Regression: Focuses on predicting continuous values, such as forecasting sales or estimating property prices.
Welcome to this comprehensive guide on Azure MachineLearning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machinelearning models. This is where Azure MachineLearning shines by democratizing access to advanced AI capabilities.
In machinelearning, decision boundaries play a crucial role in determining how effectively models classify data. Definition of decision boundary The definition of a decision boundary is rooted in its functionality within classification algorithms.
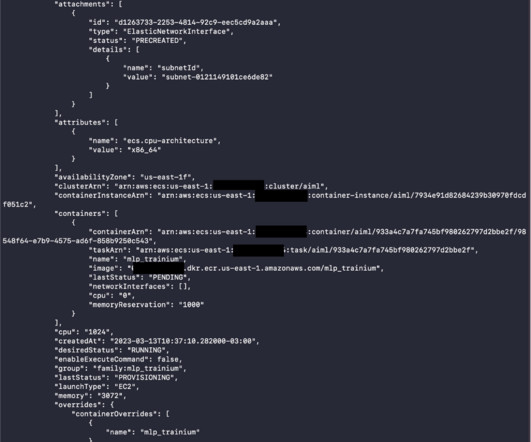
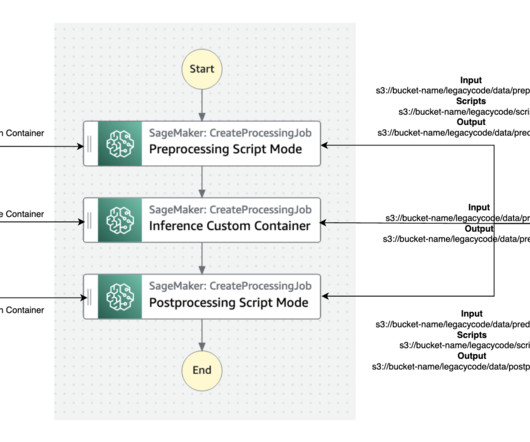
Running machinelearning (ML) workloads with containers is becoming a common practice. With containers, scaling on a cluster becomes much easier. Solution overview We walk you through the following high-level steps: Provision an ECS cluster of Trn1 instances with AWS CloudFormation. Run the ML task on Amazon ECS.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The AML feature store standardizes variable definitions using scientifically validated algorithms.
Hyperplanes are pivotal fixtures in the landscape of machinelearning, acting as crucial decision boundaries that help classify data into distinct categories. Their role extends beyond mere classification; they also facilitate regression and clustering, demonstrating their versatility across various algorithms.
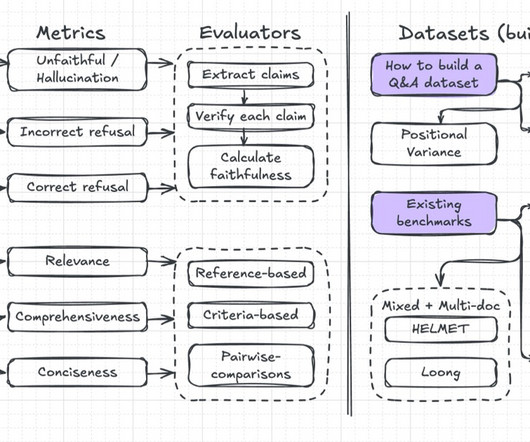
Open-ended questions: Queries on broad themes or interpretative topics rarely have a single definitive answer, especially for large documents or corpora. Definitions: These assess a model’s ability to explain domain-specific content based on the document. or “What is the legal clause mentioned in Section 2.1?”
Definition and purpose of parallel file systems Understanding the necessity for handling large volumes of data in the modern landscape highlights the importance of parallel file systems. Definitions and key differences Access methods differ significantly between parallel and distributed file systems.
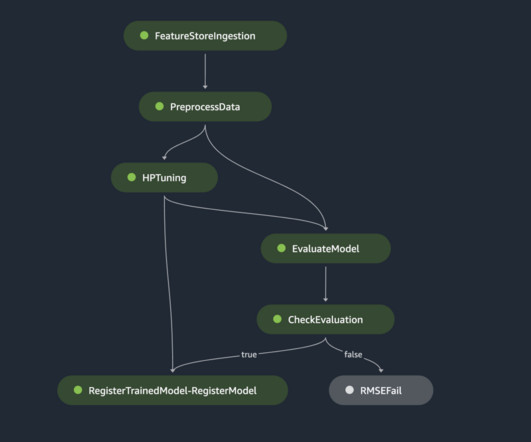
Tens of thousands of AWS customers use AWS machinelearning (ML) services to accelerate their ML development with fully managed infrastructure and tools. Cluster resources are provisioned for the duration of your job, and cleaned up when a job is complete. Refer to the sample Step Functions workflow.
Machinelearning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster.
In a world where data is rapidly generated and accumulated, the ability to distill important features from a vast array of variables can significantly enhance the efficiency and effectiveness of data analysis and machinelearning models. What is dimensionality reduction? This can result in poor generalization to new, unseen data.
In this article we will speak about Serverless Machinelearning in AWS, so sit back, relax, and enjoy! Introduction to Serverless MachineLearning in AWS Serverless computing reshapes machinelearning (ML) workflow deployment through its combination of scalability and low operational cost, and reduced total maintenance expenses.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray promotes the same coding patterns for both a simple machinelearning (ML) experiment and a scalable, resilient production application.
Beginner’s Guide to ML-001: Introducing the Wonderful World of MachineLearning: An Introduction Everyone is using mobile or web applications which are based on one or other machinelearning algorithms. You might be using machinelearning algorithms from everything you see on OTT or everything you shop online.
Machine teaching is redefining how we interact with artificial intelligence (AI) and machinelearning (ML). As industries increasingly adopt AI solutions, professionals without a technical background can now step into the realm of machinelearning, leveraging powerful algorithms to automate tasks and improve decision-making.
Revolutionizing the way we organize the data, Databricks introduced a game-changer called Liquid Clustering in this year’s Data + AI Summit. An innovative feature that redefines the boundaries of partitioning and clustering for Delta tables. Writing data to a clustered table — Most operations do not automatically cluster data on write.
Moving across the typical machinelearning lifecycle can be a nightmare. Machinelearning platforms are increasingly looking to be the “fix” to successfully consolidate all the components of MLOps from development to production. What is a machinelearning platform? That’s where this guide comes in!
Starting simple Predictive maintenance often requires complex machinelearning models that can be difficult to implement and interpret. To improve the quality of the region definition, we can use a GMM with multiple components. This allows us to model the complex, non-elliptical distribution of machine states.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
It can be even more valuable when used in conjunction with machinelearning. MachineLearning Helps Companies Get More Value Out of Analytics. You will get even more value out of analytics if you leverage machinelearning at the same time. This is why businesses are looking to leverage machinelearning (ML).
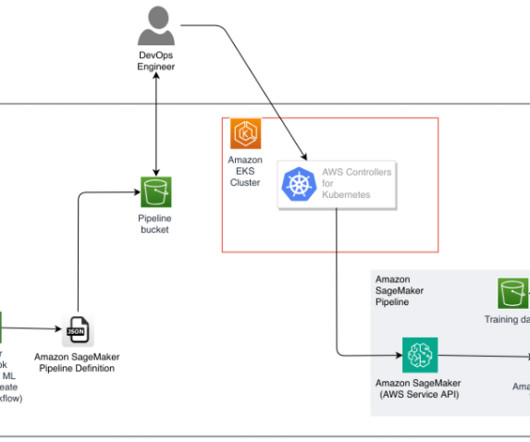
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machinelearning (ML) applications. ACK allows you to take advantage of managed model building pipelines without needing to define resources outside of the Kubernetes cluster. kubectl for working with Kubernetes clusters.
It usually comprises parsing log data into vectors or machine-understandable tokens, which you can then use to train custom machinelearning (ML) algorithms for determining anomalies. This process is called hyperparameter tuning and is an essential part of machinelearning. installed in them.
Understanding Supervised vs Unsupervised Learning: A Comparative Overview Introduction Hello dear readers, hope you’re doing just fine! (Or Or even better than that) Machinelearning has transformed the way businesses operate by automating processes, analyzing data patterns, and improving decision-making.
Data mining is a fascinating field that blends statistical techniques, machinelearning, and database systems to reveal insights hidden within vast amounts of data. ClusteringClustering groups similar data points based on their attributes. This approach is useful for predicting outcomes based on historical data.
To learn more about DeepSeek-R1, refer to DeepSeek-R1 model now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart and deep dive into the thesis behind building DeepSeek-R1. Task definition (count_task) This is a task that we want this agent to execute. This agent is equipped with a tool called BlocksCounterTool.
By leveraging statistical techniques and machinelearning, organizations can forecast future trends based on historical data. Through various statistical methods and machinelearning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
Machinelearning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machinelearning engineers and data scientists have gained prominence.
Supervised learning is a powerful approach within the expansive field of machinelearning that relies on labeled data to teach algorithms how to make predictions. Supervised learning refers to a subset of machinelearning techniques where algorithms learn from labeled datasets.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learneddefinitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
Amazon SageMaker enables enterprises to build, train, and deploy machinelearning (ML) models. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Set up the database access and network access.
Nvidia provides an interface known as Rapids to execute pandas, visualize large datasets and even Scikit-Learn for feature engineering and machinelearning model training on GPU. __version__ The cuml library facilitates machinelearning tasks by using the scikit-learn interface. Well, worry no more.
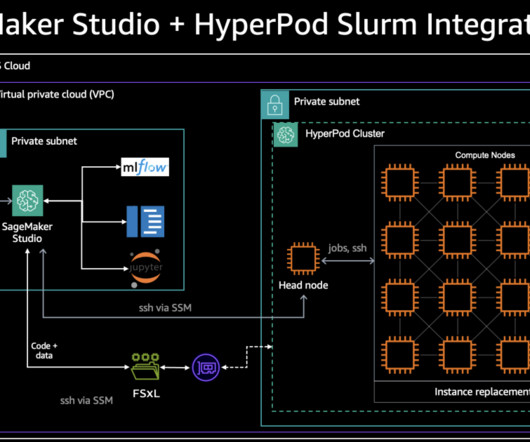
Foundation Models (FMs) demand distributed training clusters — coordinated groups of accelerated compute instances , using frameworks like PyTorch — to parallelize workloads across hundreds of accelerators (like AWS Trainium and AWS Inferentia chips or NVIDIA GPUs). The likelihood of these failures increases with the size of the cluster.
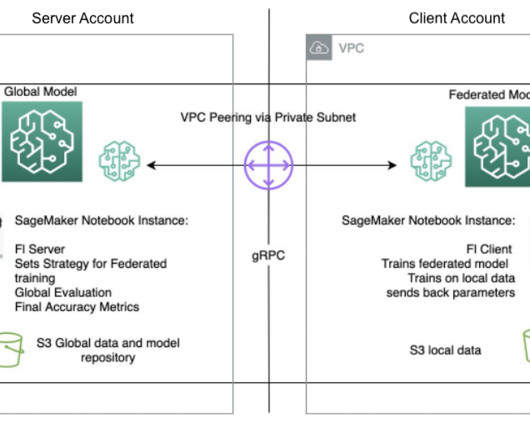
Machinelearning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. In contrast, with federated learning, training usually occurs in multiple separate accounts or across Regions. She has extensive experience in machinelearning with a PhD degree in computer science.
The functionality of deep learning Deep learning relies heavily on the architecture of neural networks, which consist of interconnected layers that process information similarly to the human brain. Definition of neural networks Neural networks are designed to recognize patterns in data.
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
Triplet loss is a crucial concept in machinelearning that plays a significant role in how algorithms understand similarities between data points. Understanding how triplet loss functions can enhance your ability to train effective models in similarity learning.
Definition and significance of data science The significance of data science cannot be overstated. Predictive analytics utilizes statistical algorithms and machinelearning to forecast future outcomes based on historical data. Machinelearning engineer: Focuses on the development of predictive models.
Definition and purpose of personalization engines Personalization engines enhance e-commerce by providing customized user experiences that allow businesses to cater to individual customer needs. Implementation of advanced techniques such as machinelearning for improved effectiveness.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content