

Data mining
Dataconomy
MARCH 4, 2025
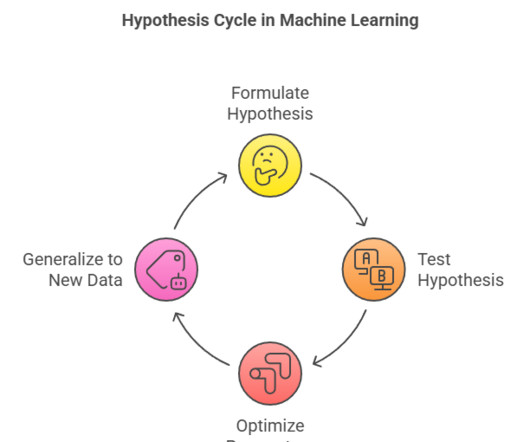
Classification Classification techniques, including decision trees, categorize data into predefined classes. Clustering Clustering groups similar data points based on their attributes. One common example is k-means clustering, which segments data into distinct groups for analysis.





















Let's personalize your content