This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Azure Data Studio has rapidly gained popularity among developers and databaseadministrators for its user-friendly design and powerful features. As a versatile tool, it simplifies the management of both SQL Server and Azure SQLdatabases, offering a modern alternative to traditional database management solutions.
Summary: This article explores the fundamental differences between clustered and non-clustered index in database management. Understanding these distinctions is crucial for optimizing data retrieval and ensuring efficient database operations, ultimately leading to improved application performance and user experience.
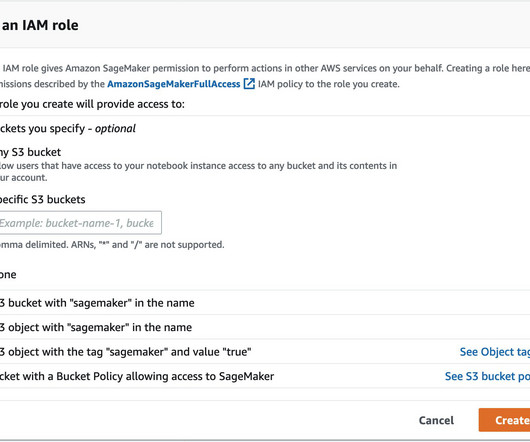
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
Clustered Index A clustered index determines the physical order in which data is stored in the database. Each table can have only one clustered index because the actual data rows are stored in the order specified by the clustered index. In that case, the entire table is sorted by Employee_ID.
SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. While it may not be a traditional programming language, SQL plays a crucial role in Data Science by enabling efficient querying and extraction of data from databases.
Cassandra’s architecture is based on a peer-to-peer model where all nodes in the cluster are equal. Partition Key: Determines how data is distributed across nodes in the cluster. Its linear scalability means that as additional nodes are added to the cluster, overall performance improves proportionally.
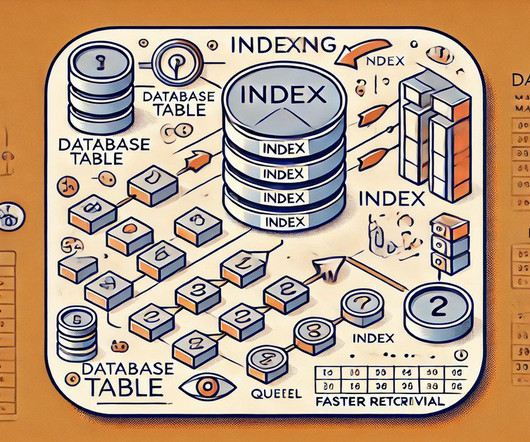
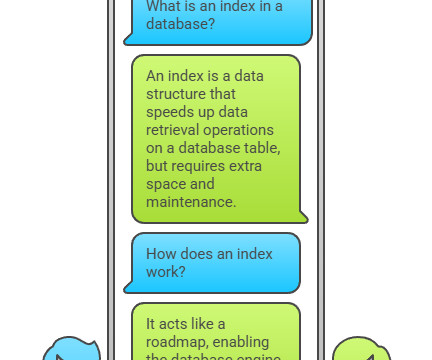
Summary: The SQL CREATE INDEX statement is a powerful tool for improving query performance by creating indexes on frequently searched columns. Indexes enable faster data retrieval, optimize joins, and enhance database efficiency. At the heart of this mechanism lies the SQL CREATE INDEX statement. What is a SQL Index?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content