This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
inherits tags on the cluster definition, while serverless adheres to Serverless Budget Policies ( AWS | Azure | GCP ). Case 2: Only one task runs on serverless In this case, BP tags would also propagate to system tables for the serverless compute usage, while the classic compute billing record inherits tags from the cluster definition.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Distributed databases represent a transformative step in data management, allowing organizations to harness data spread across multiple locations. As businesses increasingly seek agility in an interconnected world, understanding distributed databases becomes vital. What are distributed databases?
Cluster Setup Crusoe graciously lent us a cluster of 300 L40S GPUs. torchft can have many, many hosts in each replica group, but for this cluster, a single host/10 gpus per replica group had the best performance due to limited network bandwidth. If you have a new use case you’d like to collaborate on, please reach out!
This one-liner bins your data into ranges and finds the most populated interval, revealing where your values cluster most densely. Find the Most Frequent Value Range Understanding data distribution patterns often requires identifying concentration areas within your dataset. most_frequent_range = Counter([int(x//10)*10 for x in numbers]).most_common(1)[0]
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
The in-memory algorithms for approximate nearest neighbor search (ANNS) have achieved great success for fast high-recall search, but are extremely expensive when handling very large scale database. Thus, there is an increasing request for the hybrid ANNS solutions with small memory and inexpensive solid-state drive (SSD).
Through natural language processing, Amazon Bedrock Knowledge Bases transforms natural language queries into SQL queries, so users can retrieve data directly from supported sources without understanding database structure or SQL syntax. We use a bastion host to connect securely to the database from the public subnet.
On June 12, 2025 at NVIDIA GTC Paris, learn more about cuML and clustering algorithms during the hands-on workshop, Accelerate Clustering Algorithms to Achieve the Highest Performance. It dramatically improves algorithm performance for data-intensive tasks involving tens to hundreds of millions of records.
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
Organizations manage extensive structured data in databases and data warehouses. The system interprets database schemas and context, converting natural language questions into accurate queries while maintaining data reliability standards. Data analysts must translate business questions into SQL queries, creating workflow bottlenecks.
If you have a large-scale production workload and want to take the time to tune for the best price-performance and the most flexibility, you can use an OpenSearch Service managed cluster. For more details on best practices for operating an OpenSearch Service managed cluster, see Operational best practices for Amazon OpenSearch Service.
The unsung heroes behind this magic are embeddings, and their meticulously organized apartments are vector databases. But how do these magical numerical arrays get created, and how do they find their perfect spot in a database optimized for them? At their core, vector databases store embeddings as numerical arrays.
It gives these users a single, intuitive entry point to interact with data and AI—without needing to understand clusters, queries, models, or notebooks. Databricks One is a new product experience designed specifically for business users.
Context Manager Pattern for Resource Management When working with resources like files, database connections, or network sockets, you need to ensure they’re properly opened and closed, even if an error occurs. Example: Suppose you’re fetching user data from a database and want to provide context when a database error occurs.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
From regression models to clustering and time series analysis, sports datasets offer opportunities to apply diverse statistical and machine learning concepts. It’s relatable — many data scientists are already passionate fans. Why it matters: This high-resolution data enables detailed biomechanical and tactical analysis.
Such hurdles include the costs and infrastructure complexities that come with vector databases that enterprises need to seamlessly store, search, and manage high-dimensional embeddings at scale. Operational complexity – Teams are forced to divert valuable engineering resources toward managing and tuning dedicated vector databaseclusters.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
A users question is used as the query to retrieve relevant documents from a database. LangChain offers a collection of open-source building blocks, including memory management , data loaders for various sources, and integrations with vector databases all the essential components of a RAG system. Overview of a baseline RAG system.
This means: Less time spent tuning or scheduling maintenance manually Smarter execution that avoids unnecessary compute usage Better file sizes and clustering for faster query performance Deletion vectors are now enabled by default for new streaming tables and materialized views.
These models use knowledge graphs databases of known biological interactionsto infer how a new gene disruption might affect a cell. Gene set enrichment : Identify clusters of genes that behave similarly under perturbations and describe their common function.
The following policy restricts SageMaker Studio users access to EMR clusters by requiring that the cluster be tagged with a user key matching the user’s SourceIdentity. With SageMaker AI, you can simply request the secret at runtime, so your notebooks, training jobs, and inference endpoints stay free of hard-coded keys.
Admin > Cost Management > Usage type(Storage) Table level: TABLE_STORAGE_METRICS view in Snowflake account usage or database information_schema provides detailed table-level storage utilization, which is instrumental in determining the storage billing for each table within the account.
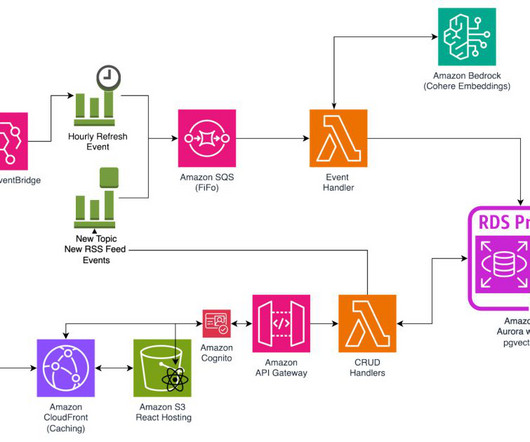
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector. Its hosted on AWS Lambda.
The key here is to focus on concepts like supervised vs. unsupervised learning, regression, classification, clustering, and model evaluation. Step 5: RAG & Vector Databases Retrieval-Augmented Generation (RAG) is a hybrid approach that combines information retrieval with text generation.
Turso Login Open main menu Product Docs Customers Pricing Blog Schedule a call Follow us on X Join us on Discord Login Sign Up Jun 16, 2025 Working on databases from prison: How I got here, part 2. I'd never worked on relational databases, but some experience with a cache had recently sparked an interest in storage engines.
At a recent webinar hosted by Stefan Webb, Developer Advocate and champion of Milvus (an open-source vector database), he walked a global audience through the what, why, and how of building multimodal RAG systems. By mapping content to a high-dimensional space, related pieces cluster together. Heres what you need toknow.
During the training process, our SageMaker HyperPod cluster was connected to this S3 bucket, enabling effortless retrieval of the dataset elements as needed. The integration of Amazon S3 and the SageMaker HyperPod cluster exemplifies the power of the AWS ecosystem, where various services work together seamlessly to support complex workflows.
Scanning the energy label links directly to the EPREL database, revealing granular specs, spare-part availability windows, and software-update commitments. Laggards cluster among entry-level OEMs that outsource design and run on razor-thin margins; for them, the seven-year spare-part stockpile is a capital-intensive hurdle.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities. Metadata filtering allows you to segment data inside of an OpenSearch Serverless vector database.
from local or virtual machine to K8s cluster) and the need for bespoke deployments. Iguazio allows the team to go from testing code locally to running at scale on a remote cluster within minutes. This setup happens once per toolset and is stored in a database. It takes about a week and can be fine-tuned over time.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Enhanced Search and Retrieval Augmented Generation: Vector search systems work by matching queries with embeddings in a database.
A right-sized cluster will keep this compressed index in memory. He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearchs vector database capabilities. Compression lowers cost by reducing the memory required by the vector engine, but it sacrifices accuracy in return.
Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. The implementation included a provisioned three-node sharded OpenSearch Service cluster. Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data.
This NoSQL database is optimized for rapid access, making sure the knowledge base remains responsive and searchable. Victor holds several patents in AI technologies, has published extensively on clustering and neural networks, and actively contributes to the open source community with projects that democratize access to AI tools.
The ingestion pipeline (3) ingests metadata (1) from services (2), including Amazon DataZone, AWS Glue, and Amazon Athena , to a Neptune database after converting the JSON response from the service APIs into an RDF triple format. Run SPARQL queries in the Neptune database to populate additional triples from inference rules.
Summary: This article explores the fundamental differences between clustered and non-clustered index in database management. Understanding these distinctions is crucial for optimizing data retrieval and ensuring efficient database operations, ultimately leading to improved application performance and user experience.
By employing a multi-modal approach, the solution connects relevant data elements across various databases. The app container is deployed using a cost-optimal AWS microservice-based architecture using Amazon Elastic Container Service (Amazon ECS) clusters and AWS Fargate.
This day-to-day data from multiple business units lands in relational databases hosted on Amazon Relational Database Service (Amazon RDS). Parcel Perform uses an Apache Kafka cluster managed by Amazon Managed Streaming for Apache Kafka (Amazon MSK) as the stream to move the data from the source to the S3 bucket.
These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems. These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems.
Configurations, user conversation histories, and usage metrics are securely stored in a persistent Amazon Relational Database Service (Amazon RDS) for PostgreSQL database, enabling audit readiness and supporting compliance.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content